Description
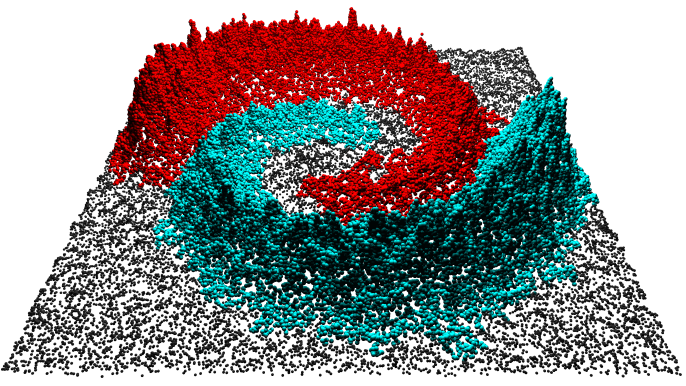
Data analysis is the process of cleaning, transforming, modelling or comparing data, in order to infer useful information and gain insights into complex phenomena. From a geometric perspective, when an instance (a physical phenomenon, an individual, etc.) is given as a fixed-sized collection of real-valued observations, it is naturally identified with a geometric point having these observations as coordinates. Any collection of such instances is then seen as a point cloud sampled in some metric or normed space.
This course reviews fundamental constructions related to the manipulation of such point clouds, mixing ideas from computational geometry and topology, statistics, and machine learning. The emphasis is on methods that not only come with theoretical guarantees, but also work well in practice. In particular, software references and example datasets will be provided to illustrate the constructions.
For any questions or concerns please contact Mathieu Carrière at mathieu.carriere[at]inria.fr, or Frédéric Cazals at frederic.cazals[at]inria.fr
Close
Outline
The course consists of the following eight lectures (3h each):
1. Computational Topology (I): Simplicial Complexes and Homology
2. Nearest Neighbors in Euclidean and metric spaces (I): Data Structures and Algorithms
3. Nearest Neighbors in Euclidean and metric spaces (II): Analysis
4. Comparing Samplings, Distributions, Clusterings
5. Computational Topology (II): Persistence Theory
6. Topological Machine Learning (I): Statistics and Representations
7. Topological Machine Learning (II): Guiding ML models
8. Dimensionality Reduction Algorithms
NB: course material (slides, notes) will be provided after the lectures.
Close
Class NN:DSA
Nearest neighbors in Euclidean and metric spaces: Data Structures and Algorithms
Summary
For data modeled as a point cloud, reporting the nearest neighbors (NN) of a given point is a fundamental operation consistently reused in data analysis. Efficient NN search methods will be reviewed, both for Euclidean and metric spaces.
- Euclidean spaces:
- Exact nearest neighbors via Voronoi diagrams
- Randomized k-d trees and random projection trees
- Metric spaces:
- Metric trees
- Linear approximating and eliminating search algorithm
- Selected important metrics, with applications:
- Hausdorff and Frechet distances
- Earth mover distance and optimal transport
- Earth mover distance with connectivity constraints
- The Mallow distance and its application to compare clusterings
Slides
Bibliography
- (book) Har-Peled, S. Geometric Approximation Algorithms. Mathematical Surveys and Monographs, AMS, 2011 (chapters 17 to 20).
- (book) Shakhnarovich, G., Darrell, T., and Indyk, P. Nearest-Neighbors Methods in Learning and Vision. Theory and Practice, MIT press, 2005.
- (book) Hanan, S. Foundations of multidimensional and metric data structures. Morgan Kaufmann, 2006.
- Arya, S., Mount, D.M., Netanyahu, N.S., Silverman, R. and Wu, A.Y. An optimal algorithm for approximate nearest neighbor searching fixed dimensions. Journal of the ACM, 45, 1998.
- Marius, M., and Lowe, D. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. VISAPP (1), 2009.
- Indyk, P., and Motwani, R. Approximate nearest neighbors: towards removing the curse of dimensionality. Proceedings of the thirtieth annual ACM symposium on Theory of computing, pages 604-613, 1998.
- Umeyama, S. Least-squares estimation of transformation parameters between two point patterns. IEEE Transactions on pattern analysis and machine intelligence, 13(4), 376-380, 1991.
- Yossi, R., Tomasi, C., and Guibas, L. The earth mover's distance as a metric for image retrieval. International Journal of Computer Vision 40.2: 99-121, 2000
- Elizaveta, L., and Bickel, P. The earth mover's distance is the Mallows distance: some insights from statistics. Proceedings Eighth IEEE International Conference on Computer Vision, IEEE, 2001.
- Ding, Z., Li, J., and Zha, H. A new mallows distance based metric for comparing clusterings. Proceedings of the 22nd international conference on Machine learning, ACM, 2005.
Close
Class NN:A
Nearest Neighbors in Euclidean and metric spaces: Analysis
Summary
This lecture will develop selected insights / mathematical analysis related to the data structures and algorithms seen in the first lecture.
High dimensional spaces and measure concentration phenomena: introduction and implications for NN algorithms:
- The notion of intrinsic dimension
- Experiments on nearest neighbor searches, regression, dimension estimation
- Random projection trees (RPT): search performance analysis
- RPT: adaptation to the intrinsic dimension
- Concentration phenomena: application to nearest neighbor searches
- Concentration phenomena: key properties
Slides
Bibliography
- Verma, N., Kpotufe, S., and Dasgupta, S. Which spatial partitions are adaptive to intrinsic dimension? UAI, 2009.
- Dasgupta, S., and Sinha, K. Randomized partition trees for exact nearest neighbor search. JMLR: Workshop and Conference Proceedings, 30:1--21, 2013.
- Vempala, S. Randomly-oriented kd Trees Adapt to Intrinsic Dimension. FSTTCS, 2012.
- Francois, D., Wertz, V., and Verleysen, M. The concentration of fractional distances. Knowledge and Data Engineering, IEEE Transactions on, 19(7), 873-886, 2007.
- Charu, A., Hinneburg, A., and Keim, D. On the surprising behavior of distance metrics in high dimensional space. Springer Berlin Heidelberg, 2001.
- Beyer, K., et al. When is nearest neighbor meaningful? Database Theory, Springer Berlin Heidelberg, 217-235, 1999.
Close
Class CT:SCH
Computational Topology (I): Simplicial Complexes and Homology
Summary
The purpose of this class is to introduce the most basic concepts of computational topology. We will present the definitions
of various types of combinatorial representations of topological spaces, called simplicial complexes,
and look at some of their mathematical properties, such as the nerve theorem.
Then, we will see how to compute topological invariants from these complexes, focusing on the so-called homology groups and their dimensions called Betti numbers.
Keywords
Geometric and Abstract Simplicial Complexes, Triangulations, Cover Complexes, Nerve Theorem, Homology.
Slides,
TD,
solution.
Bibliography
Munkres, J. Elements of Algebraic Topology, CRC Press, 1984.
Hatcher, A. Algebraic Topology, Cambridge University Press, 2002.
Edelsbrunner, H., Harer, J. Computational Topology: an introduction, AMS, 2010.
Close
Class CT:PH
Computational Topology (II): Persistence Theory
Summary
The purpose of this class is to present one of the main tools of topological
data analysis, the persistent homology groups and persistence barcodes/diagrams. We will present their
definitions and computation algorithms, as well as their theoretical
stability properties and their applications to point cloud data.
Keywords
Persistent Homology, Boundary Reduction Algorithm, Stability Theorem.
Slides,
TD,
solution.
Bibliography
Cohen-Steiner, D., Edelsbrunner, H. and Harer, J. Stability of persistence diagrams. Discrete and Computational Geometry, Volume 37, pp. 103-120, 2007.
Chazal, F., Cohen-Steiner, D., Guibas, L., Mémoli, F. and Oudot, S. Gromov-Hausdorff Stable Signatures for Shapes using Persistence. Computer Graphics Forum (proc. SGP), pp. 1393-1403, 2009.
Close
Class SDC
Comparing Samplings, Distributions, Clusterings
Summary
Scenarii where one needs to compare two point clouds representing two populations in a high dimensional space, or two clusterings of such point clouds, are commonplace. This lecture will review techniques to do so, in three steps. First, we will recall basics of statistical hypothesis testing and two-sample tests (TST). Second, upon rejecting the null hypothesis, we will study techniques to single out those regions in parametric space where the distributions differ. Finally, in a complementary realm, we will study the problem of comparing two clusterings of two point clouds.
- Statistical hypothesis testing and p-values
- Two-sample tests: from univariate to multivariate (MMD)
- Information theoretic measures to compare distributions
- Localizing data discrepancies upon performing two-sample test
- Comparing clusterings
Slides (main)
Slides (additional)
Bibliography
- (book) G. Casella and R. Berger, Statistical inference, Duxbury Press, 2001.
- (book) Mittelhammer, Ron C., and Ron C. Mittelhammer. Mathematical statistics for economics and business. Vol. 78. Berlin: Springer, 1996.
- (book) Lehmann, Erich L., and Joseph P. Romano. Testing statistical hypotheses. springer, 2006.
- Gretton, Arthur, et al. A kernel two-sample test. The Journal of Machine Learning Research 13 (2012): 723-773.
- Samory Kpotufe. Escaping the curse of dimensionality with a tree-based regressor.ra Conference on Learning Theory (COLT) 2009.
- Murdoch, Duncan J., Yu-Ling Tsai, and James Adcock. P-values are random variables. The American Statistician 62.3 (2008).
- Sackrowitz, Harold, and Ester Samuel-Cahn. P values as random variables-expected P values. The American Statistician 53.4 (1999): 326-331.
- B. Phipson and G. Smyth, Permutation P-values should never be zero: calculating exact P-values when permutations are randomly drawn, Statistical Applications in Genetics and Molecular Biology 9(10), 2010.
- J., Wittawat, W. Xu, Z. Szabo, K. Fukumizu, and A. Gretton. A Linear-Time Kernel Goodness-of-Fit Test. NIPS 2017.
- (book) Cover and Thomas, Elements of Information Theory, Wiley, 2006.
- F. Cazals and A. Lheritier, Beyond Two-sample-tests: Localizing Data Discrepancies in High-dimensional Spaces, IEEE/ACM International Conference on Data Science and Advanced Analytics, 2015.
- F. Cazals and D. Mazauric and R. Tetley and R. Watrigant, Comparing two clusterings using matchings between clusters of clusters.
- Mueller and Jaakkola, Principal Differences Analysis: Interpretable Characterization of Differences between Distributions, NeurIPS, 2015.
Close
Class DR
Dimensionality Reduction Algorithms
Summary
Dimensionality reduction methods aim at embedding high-dimensional data in lower-dimensional spaces, while preserving specific properties (pairwise distance, data spread, etc).
- Dimensionality reduction algorithms: criteria and classification
- The Johnson-Lindenstrauss lemma
- Multi-dimensional scaling and principal components analysis
- Isomap, LLE
- t-SNE
- Diffusion maps
Slides
Bibliography
- (book) Lee, John A., and Michel Verleysen. Nonlinear dimensionality reduction. Springer, 2007.
- (book) Sariel Har-Peled. Geometric approximation algorithms. No. 173. American Mathematical Soc., 2011.
- (book) Cox, Trevor F., and Michael AA Cox. Multidimensional scaling. CRC Press, 2000.
- Tenenbaum, Joshua B., Vin De Silva, and John C. Langford. A global geometric framework for nonlinear dimensionality reduction. Science 290.5500 (2000): 2319-2323.
- Roweis, Sam T., and Lawrence K. Saul. "Nonlinear dimensionality reduction by locally linear embedding." Science 290.5500 (2000): 2323-2326.
- Coifman, Ronald R., et al. Geometric diffusions as a tool for harmonic analysis and structure definition of data: Diffusion maps. PNAS (102), 2005.
- Lafon, Stephane, and Ann B. Lee. Diffusion maps and coarse-graining: A unified framework for dimensionality reduction, graph partitioning, and data set parameterization. Pattern Analysis and Machine Intelligence, IEEE Transactions on 28.9 (2006): 1393-1403.
- Dasgupta, Sanjoy, and Anupam Gupta. An elementary proof of a theorem of Johnson and Lindenstrauss. Random Structures and Algorithms 22.1 (2003): 60-65.
- Frédéric Cazals, Frédéric Chazal, and Joachim Giesen. Spectral Techniques to Explore Point Clouds in Euclidean Space, with Applications to Collective Coordinates in Structural Biology. Nonlinear Computational Geometry. Springer New York, 2010. 1-34.
- Diaconis, Persi, Sharad Goel, and Susan Holmes. Horseshoes in multidimensional scaling and local kernel methods. The Annals of Applied Statistics (2008): 777-807.
- (book) Lee, John A., and Michel Verleysen. Nonlinear dimensionality reduction. Springer, 2007.
- R.R. Coifman and S. Lafon and A.B. Lee and M. Maggioni and B. Nadler and F. Warner and S.W. Zucker, Geometric diffusions as a tool for harmonic analysis and structure definition of data: Diffusion maps, PNAS 102, 205.
- S. Lafon and Y. Keller and R.R. Coifman, Data fusion and multi-cue data matching by diffusion maps, IEEE Trans. on Pattern Analysis and Machine Intelligence 28, 2006.
- S. Lafon and A.B. Lee, Diffusion Maps and Coarse-Graining: A Unified Framework for Dimensionality Reduction, Graph Partitioning and Data Set Parameterization, IEEE Trans. on Pattern Analysis and Machine Intelligence 28, 2006.
- Kannan, Ravi and Vempala, Santosh and Vetta, Adrian, On clusterings: Good, bad and spectral, J. of the ACM 51, 2004.
Close
Class TML:I
Topological Machine Learning (I): Statistics and Representations
Summary
The purpose of this class is to explain how persistence diagrams
can be incorporated in standard statistical, machine learning and deep learning
models through the use of representations. We will present some of the most
common statistical inference results and diagram representations and
kernels that have been defined in the literature in recent years, as
well as neural network layers designed for persistence diagrams.
Keywords
Topological Inference, Persistence Diagram Representations: Persistence Image and Persistence Landscape, PersLay Layer for Persistence Diagrams.
Slides,
TD,
solution.
Bibliography
- Chazal, F., Glisse, M., Labruère, C. and Michel, B. Convergence rates for persistence diagram estimation in Topological Data Analysis. In Proc. International Conference on Machine Learning (ICML), 2014.
- Bubenik, P. Statistical Topological Data Analysis using Persistence Landscapes. Journal of Machine Learning Research, 2015.
- Chazal, F. et al. Stochastic convergence of persistence landscapes and silhouettes. Journal of Computational Geometry, 2015.
- Adams, H. et al. Persistence Images: A Stable Vector Representation of Persistent Homology. Journal of Machine Learning Research, 2017.
- Carrière, M., Cuturi, M. and Oudot, S. Sliced Wasserstein kernel for persistence diagrams. In Proc. International Conference on Machine Learning (ICML), 2017.
- Carrière, M., Chazal, F., Ike, Y., Lacombe, T., Royer, M. and Umeda, Y. PersLay: a neural network layer for persistence diagrams and new graph topological signatures. In Proc. International Conference on Artificial Intelligence and Statistics (AISTATS), 2020.
Close
Class TML:A
Topological Machine Learning (II): Guiding ML models
Summary
This class will introduce methods for monitoring and guiding machine learning models with topological descriptors. We will present the ToMATo algorithm that uses 0-dimensional persistence diagrams to guide the groupings of mode-seeking clustering methods. Then, we will define a notion of gradient for persistence diagrams, that allows to differentiate and run gradient descent on persistence computations, and to include persistence diagrams as regularizing loss terms in the training of predictive processes and as constraints for generative models.
Keywords
Mode-Seeking Clustering, ToMATo, Persistence Pairing, Persistence Gradient.
Slides, TD1, TD2.
Bibliography
- Chazal, F., Guibas, L., Oudot, S. and Skraba, P. Persistence-Based Clustering in Riemannian Manifolds. Journal of the ACM, Volume 60, Issue 6, pp. 1-38, 2013.
- Carrière, M., Chazal, F., Glisse, M., Ike, Y., Kannan, H. and Umeda, Y. Optimizing persistent homology based functions. In 38th International Conference on Machine Learning (ICML 2021), volume 139, pages 1294–1303. PMLR, 2021.
- Leygonie, J., Carrière, M., Lacombe, T. and Oudot, S. A gradient sampling algorithm for stratified maps with applications to topological data analysis. Mathematical Programming, 2023.
Close
Location
Classes are happening in room EF.106 at CentraleSupélec (Eiffel building, 3 rue Joliot-Curie, F-91192 Gif-sur-Yvette Cedex, France).
Close
Validation
This course is validated with data science projects.
Close