
Multimodal Vision Transformers
2021–present
INRIA
2 Papers
Behavior Analysis using Forced Attention
Human behavior understanding requires looking at minute details in the large context of a scene containing multiple input modalities. It is necessary as it allows the design of more human-like machines. While transformer approaches have shown great improvements, they face multiple challenges such as lack of data or background noise. To tackle these, we introduce the Forced Attention (FAt) Transformer which utilizes forced attention with a modified backbone for input encoding and a use of additional inputs.
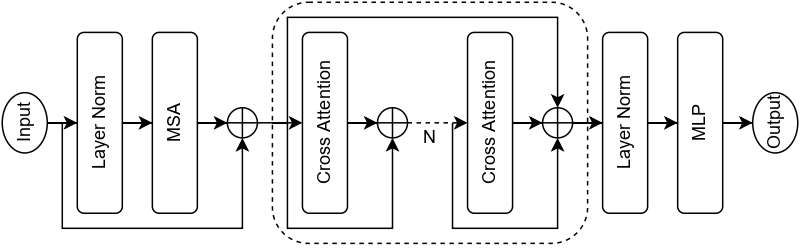
Multiple input modalities have their own branches for processing before they are combined together using cross-attention. There are sequential cross-attention layers with full frame, audio and transcript.
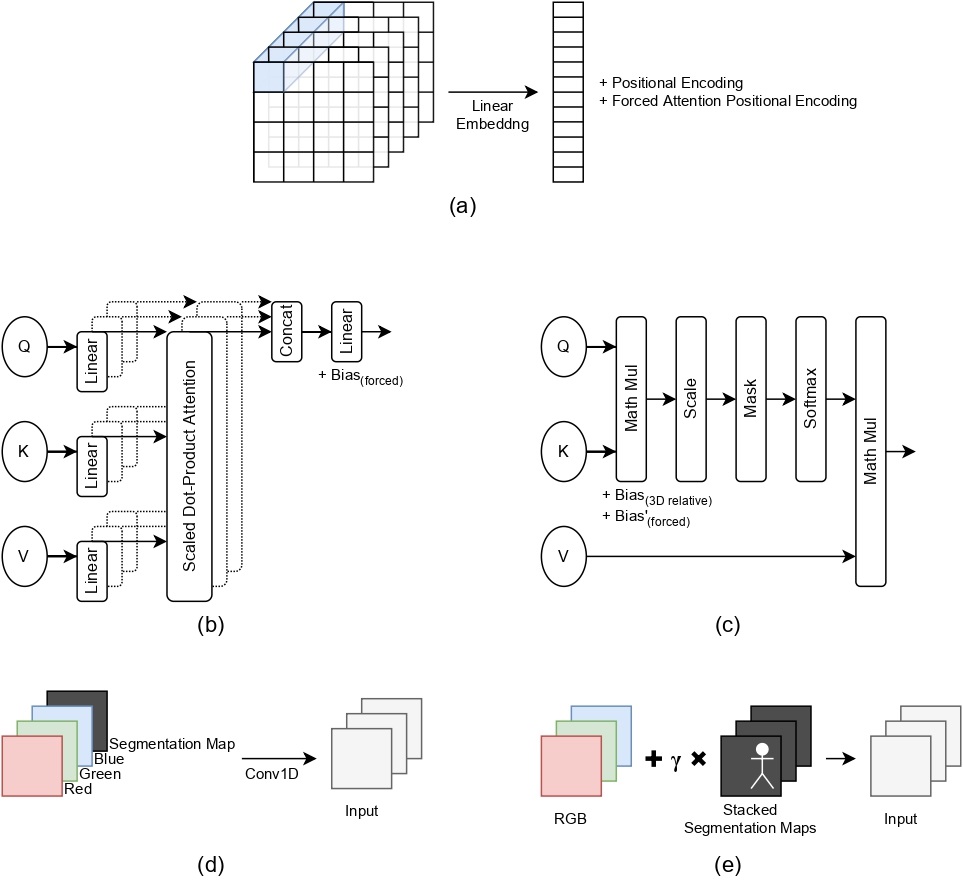
We provide the spatial localization of the target person via a segmentation map to the network, thereby forcing the network to not attend to the background. Since the background might have important information, we observe that the network learn to assign attention to parts in the background that are also relevant to the provided background. In addition to improving the performance on different tasks and inputs, the modification requires less time and memory resources. We study five ways of providing the model with segmentation maps: (a) adding an additional positional encoding to the input with the original. (b) adding a bias to the last linear layer of multi-head self attention module. (c) adding a bias similar to 3D relative bias. (d) concatenating as an additional channel to raw input and then being reduced back to original shape using Conv1D. (e) adding a segmentation map to each channel of the input.
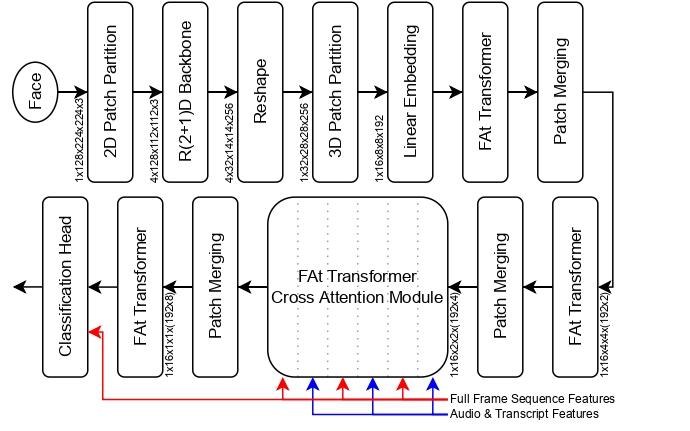
FAt Transformer is practically a model for a generalized feature extraction for tasks concerning social signals and behavior analysis. Our focus is on understanding behavior in videos where people are interacting with each other or talking into the camera which simulates the first person point of view in social interaction. Figure below shows the overall model architecture. Segmentation map is input into each FAt transformer module and is not shown here to reduce complexity.
FAt Transformers are applied to two downstream tasks: personality recognition and body language recognition. We achieve state-of-the-art results for Udiva v0.5, First Impressions v2 and MPIIGroupInteraction datasets. We further provide an extensive ablation study of the proposed architecture.
Personality Recognition using R(2+1)D
Personality computing and affective computing have gained recent interest in many research areas. The datasets for the task generally have multiple modalities like video, audio, language and bio-signals. We propose a flexible model for the task which exploits all available data. The task involves complex relations and, to avoid using a large model for video processing specifically, we propose the use of behaviour encoding which boosts performance with minimal change to the model. Cross-attention using transformers has become popular in recent times and is utilised for fusion of different modalities. Since long term relations may exist, breaking the input into chunks is not desirable, thus the proposed model processes the entire input together.
Our approach uses face crops of the target person and relates it to body language, surroundings and speech using a transformer based architecture. Short-term temporal relations are processed in this way and longer temporal relations are established using LSTM. For transcript analysis, short term temporal relations are not very meaningful so the features for the entire input sequences are extracted using BERT. Late fusion is then finally used for inferring the OCEAN personality traits.
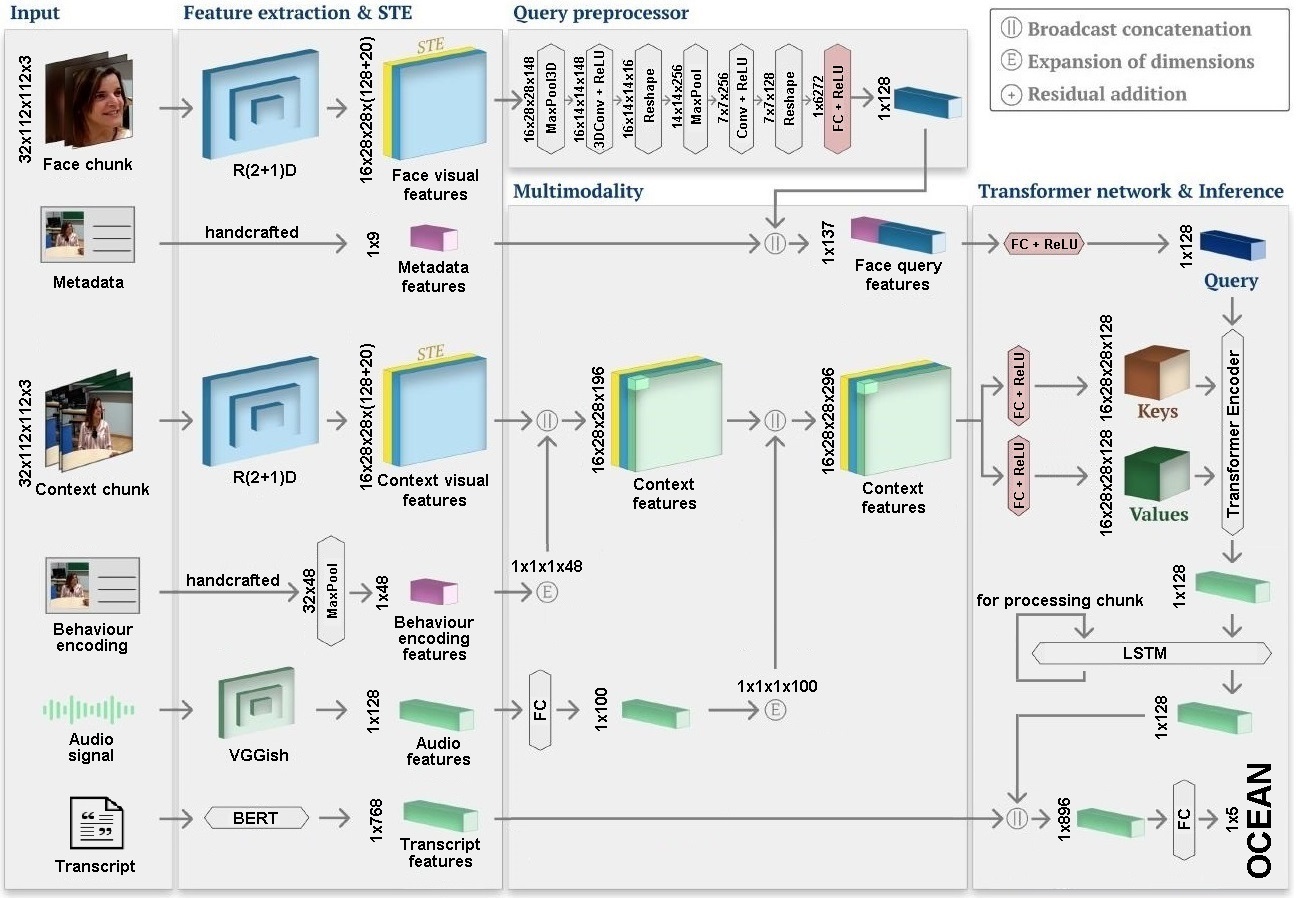
We show that a model for personality recognition will benefit from more modalities and data as input. We further show the effectiveness of all the inputs in the data through ablation studies. We also give our opinion on the trends shown in the ablation studies. Owing to the interdisciplinary nature of the project, there are numerous additions that will further improve performance. From intuition, there are some which might improve performance by a higher margin than others. Using better backbones for feature extraction would be interesting. We use the same ones as in the baseline we choose but there are existing models with better performance for similar tasks that can be utilised. Transformers have been shown to perform better than LSTMs.
The work was published in three conference proceedings.
© Michal Balazia. All Rights Reserved. Designed by HTML Codex