|
|
One continues the presentation of examples started in chapter Examples - 1. First one considers in Multiprocessing examples which benefit from multiprocessing.
Section Direct Access considers the masking
optimization included in the Direct implementation. Finally,
section Prey-Predator Demo describes the code of an
embedded system which runs on a platform with very limited resources
(the GBA of Nintendo).
In this section, one considers examples in which the presence of
several processors clearly improves the computation efficiency.
8.1.1 Producer/Consumer
Let us return to the producers/consumers example of Producers/Consumers and let us suppose that the actual processing
of values is made by some thread-safe C function (a re-entrant
function that can be called simultaneously by more than one kernel
thread). Thus, each processing thread instance of the process module can unlink from the scheduler during the computation
of the result, and re-link to it to return the result. Then, several
instances of process can be simultaneously unlinked and
running on distinct processors which would certainly speed-up the
overall computation. The process module becomes:
module native process ()
local int v;
while (1) do
while (buffer->length == 0) do
await (new_input);
if (buffer->length == 0) then cooperate; end
end
if ((local(v) = get (buffer)) == 0) then return; end
unlink;
< call of a thread-safe C function >
link (implicit_scheduler ());
{local(v)--;}
put (buffer,local(v));
generate (new_input);
end
end module
In this case, to benefit from multiprocessor machines, one basically
has to define the process module as native.
8.1.2 Lucky Prime Numbers
One now considers the production of lucky prime numbers defined in
Lucky Prime Numbers. The system is decomposed in
two uncoupled sub-systems, one for producing prime numbers and one for
lucky numbers, that can be run by distinct kernel threads on distinct
processors. The sub-systems naturally correspond to schedulers. As
the two sub-systems do not share the same instants, result produced
have to be stored elsewhere. For this purpose, one uses two fifo
channels (of type channel_t defined in Data-Flow Programming). Finally, a comparison thread is defined
which goes between schedulers to detect equal values and output them.
scheduler_t lucky_sched, prime_sched;
event_t lucky_go, prime_go;
channel_t lucky_result, prime_result;
8.1.2.1 Compare
One uses a macro which extract values from a channel chan as
much as possible, until a value greater than the one in hold is
encountered. Moreover, a value equal to hold is output:
#define COMP(chan,go) \
{local(sw) = 0;} \
while (!local(sw)) do \
GET(chan,go) \
{\
int n = extract (chan);\
if (n == local(hold)) output (n);\
if (local(hold) <= n) {\
local(hold) = n;\
local(sw) = 1;\
}\
}\
end
The module that cyclically goes from one scheduler to the other and
compares values is defined by:
module compare ()
local int hold, int sw;
while (1) do
link (lucky_sched);
COMP(lucky_result,lucky_go);
link (prime_sched);
COMP(prime_result,prime_go);
end
end module
8.1.2.2 Main
The system produces prime numbers in the channel prime_result,
lucky numbers in lucky_result, and it creates an instance of
compare in the implicit scheduler:
module main (int argc, char **argv)
{
lucky_sched = scheduler_create ();
lucky_go = event_create_in (lucky_sched);
lucky_result = init_channel ();
scheduler_start (lucky_sched);
producer_create_in (lucky_sched,lucky_go);
filter_create_in (lucky_sched,lucky_filtering,1,lucky_go,lucky_result);
prime_sched = scheduler_create ();
prime_go = event_create_in (prime_sched);
prime_result = init_channel ();
scheduler_start (prime_sched);
producer_create_in (prime_sched,prime_go);
filter_create_in (prime_sched,prime_filtering,1,prime_go,prime_result);
compare_create ();
}
end module
The filter module has been slightly changed to store
produced values in a channel instead of, as previously, generating
them. Note that the scheduler in which the instance of compare is created is actually irrelevant; the instance could
be as well created in any of the two schedulers lucky_sched
or prime_sched.
8.1.2.3 Results
One executes the previous program on a SMP (Symetric Multi
Processor) bi-processor machine made of 2 PIII 1Ghz processors
running on Linux 2.20 with 512Mb memory. One uses the implementation
based on FairThreads to produce the first 300 lucky-prime numbers. The
previous program is compared with a variant in which there is only one
scheduler (both lucky_sched and prime_sched are
mapped to the implicit scheduler). The time taken by the initial
system with 2 schedulers is 10.5s, while it is 19.2s with the variant
with a single scheduler. This shows that the presence of two
processors is fully exploited by the program.
One now illustrates the efficiency of the masking technique used in
the Direct implementation to get a constant time access to the next thread.
Best Case
One first considers an example in which the gain of direct access is
maximal. The considered system is made of two active threads and of a
large number of inactive threads, which thus can be masked. First,
one defines a module blocked which just awaits an event and
terminates:
module blocked (event_t event)
await (local(event));
end module
The module active prints a certain number of times a message
and then exits the program:
module active (char *s)
repeat (CYCLES) do
printf ("%s ",local(s));
cooperate;
end
end module
Finally, the system one creates two active threads and a
large number of threads blocked on the same event:
module main ()
{
int i;
event_t go = event_create ();
active_create ("1");
for (i = 0; i < THREADS; i++) blocked_create (go);
active_create ("2");
}
end module
At the beginning of the second instant, the linked list of
the implicit scheduler contains THREADS+2 elements. All but
the active threads are registered in the waiting list of the event
go during the second instant. Then, at the beginning of the
third instant, linked contains only the 2 active threads,
the other ones being masked. Thus execution of the system do not
depend any more of the THREADS number of blocked threads,
and can be extremely fast as only 2 threads are run from that moment.
To give an idea, it takes about 0.7 seconds to run the program on a
PIII 850Mhz with 256M of memory with THREADS equals to
100000 and CYCLES equals to 100. With CYCLES
equals to 1000, the time becomes 0.9s. This is not surprising as CPU
is mainly consumed during the second instant.
Note that, without the masking technique implemented by Direct one
should get about 6s for CYCLES equals to 100 but 57s for
CYCLES equals to 1000!
Worst Case
Now let us consider the worst case for the masking technique, when
threads are actually masked and unmasked at each instant. One changes
blocked to get a cyclic behavior:
module blocked (event_t event)
while (1) do
await (local(event));
cooperate;
end
end module
Then, one generates the triggering event go at each instant.
Now, in the same previous conditions THREADS equals to
100000 and CYCLES equals to 100, the time becomes 27s with
the masking technique and 26s without it. With CYCLES equals
to 1000, the time is 4m29s with masking and 4m6s without. Thus, in
this case, the masking approach leads to a loss of efficency (actually a
small one). Of course, intermediate results can be obtained which
depend on the frequency of generations of go.
Sieve for Prime Numbers
From the rather academic previous examples, one sees that the gain
increases as there are more and more threads that are rarely
awaken. In real situations the gain is of course less important than
the one of the best case. This is the case with the sieve of Sieve Examples for producing prime numbers. For producing
the 3000 first prime numbers with the making technique it takes 13.7s
and without it 17.4s. For producing 5000 prime numbers, it takes 38s
with masking and 1m without it. For 10000 numbers and masking: 2m37s
and without masking: 4m24s. Thus, in this example the gain obtained by
using masking is significant.
One describes the main parts of the code of a demo of a small
preys-predators system implemented for the GameBoy Advance
(GBA) platform of Nintendo.
A predator moves using the arrow keys. Preys are running away from
predators and are killed when a predator is sufficiently close to
them. New preys are automatically created. A predator is put in an
automatic chasing mode with key 'a' and returns in the manual mode
with 'b'. More predators can be created with 'l', and more preys with
'r'. Here is a screenshot of the demo running on the VisualBoyAdvance
emulator.
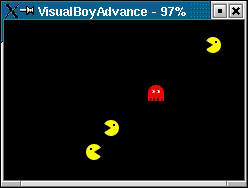 The predator is the ghost and the preys are the pacmans. This demo is
available at the Web site http://www.gbadev.org.
The predator is the ghost and the preys are the pacmans. This demo is
available at the Web site http://www.gbadev.org.
8.3.1 Sprites
One calls sprites the basic moving graphical objects to which
reactive behaviors are associated. Sprites are in limited number in
the GBA (actually, 128). The type of sprites sprite_t is:
typedef struct
{
s16 x;
s16 y;
s16 sx;
s16 sy;
u8 index;
thread_t *behaviors;
u8 behav_num;
event_t destroy;
u8 dead;
}
struct_sprite_t, *sprite_t;
The types s16 and u8 are integer types (actually,
signed 16 bits, and unsigned 8 bits). Fields x and y are the sprite coordinates. sx and sy define
the speed vector of the sprite. index is the index of the
sprite in the table where sprites are stored. behaviors is
an array of threads in elementary behaviors of the
sprite can be stored. The size of behaviors is stored in
behav_num. The event destroy is used to signal the
destruction of the sprite. Finally, the boolean dead is used
to note that the sprite is destroyed.
Destruction
Destruction of a sprite is performed using the following module destroy_sprite:
module destroy_sprite (sprite_t s)
{
int i;
sprite_t s = local(s);
for (i=0;i<s->behav_num;i++) stop (s->behaviors[i]);
}
cooperate;
{
int i;
sprite_t s = local(s);
suppress_sprite (s->index);
for (i=0;i<s->behav_num;i++) thread_deallocate (s->behaviors[i]);
event_deallocate (s->destroy);
free (s->behaviors);
free (s);
thread_deallocate (self ());
}
end module
First, all components of behaviors are stopped. Then, at the
next instant, they are deallocated (by thread_deallocate)
with the sprite structure itself. Finally, the executing thread
(returned by self) is deallocated.
Because of the cooperate, threads are actually stopped at
instant N+1, and are deallocated at instant N+2 (remember thar calls
to stop and to thread_deallocate produce orders
which are not immediately processed, but are delayed to the next
instant).
8.3.2 Keyboard
Basically, keys are converted into events. The function create_key_events creates the 8 events needed:
void create_key_events (void)
{
a_pressed = event_create ();
b_pressed = event_create ();
up_pressed = event_create ();
down_pressed = event_create ();
left_pressed = event_create ();
right_pressed = event_create ();
r_pressed = event_create ();
l_pressed = event_create ();
}
The purpose of the module key_handler is to convert at each
instant, the key press (obtained through the function pressed_key) into the corresponding events (remark that several
keys can be simultaneously processed).
module key_handler ()
while (1) do
{
if (pressed_key (KEY_A)) generate (a_pressed);
if (pressed_key (KEY_B)) generate (b_pressed);
if (pressed_key (KEY_UP)) generate (up_pressed);
if (pressed_key (KEY_DOWN)) generate (down_pressed);
if (pressed_key (KEY_LEFT)) generate (left_pressed);
if (pressed_key (KEY_RIGHT)) generate (right_pressed);
if (pressed_key (KEY_R)) generate (r_pressed);
if (pressed_key (KEY_L)) generate (l_pressed);
}
cooperate;
end
end module
The module key_processing associates a callback (of type
void (*callback_t) ()) to a key. 10 instants are passed when
a key press is detected, in order to give enough time for the key to
be released.
module key_processing (event_t key_pressed,callback_t callback)
while(1) do
await (local(key_pressed));
{
local(callback) ();
}
repeat (10) do cooperate; end
end
end module
8.3.3 Elementary Behaviors
One describes several elementary behaviors which will be used by
sprites: inertia, moves in the 4 directions, and collision.
Inertia
A sprite gets an inertial behavior with the inertia module,
in which the sprite given in parameter increments at each instant its
coordinates according to its speed.
module inertia (sprite_t s)
while (1) do
{
sprite_t s = local(s);
s->x += s->sx/INERTIA_FACTOR;
s->y += s->sy/INERTIA_FACTOR;
}
cooperate;
end
end module
Moves
With the module move_right, a sprite moves when the event
right_pressed is present:
void go_right (sprite_t s,s16 dist)
{
s->x += dist;
if (s->x > MAX_BORDER_X) s->x = MAX_BORDER_X;
}
module move_right (sprite_t s,int dist)
while (1) do
await (right_pressed);
go_right (local(s),local(dist))
cooperate;
end
end module
Similar modules are defined for the 3 other directions.
Collisions
A function which performs elementary collision between two sprites is
first defined:
static void collision (sprite_t s1,sprite_t s2)
{
u16 dx = s2->x - s1->x;
u16 dy = s2->y - s1->y;
if (dist2 (s1,s2) > min_collision) return;
s1->sx = -s1->sx;
s1->sy = -s1->sy;
if (dx>0) go_left (s1,dx); else go_right (s1,-dx);
if (dy>0) go_up (s1,dy); else go_down (s1,-dy);
}
Then, the collision behavior of a sprite is described in the module
collide. Collision detection is related to a special event
which is generated by all sprites subject to collision. This event is
generated by all these sprites, at each instant.
module collide (sprite_t me,event_t collide_evt)
local sprite_t other, int i, int exit;
while (1) do
{
local(i) = 0;
local(exit) = 0;
}
generate_value(local(collide_evt), (void*)local(me));
while(!local(exit)) do
get_value (local(collide_evt),local(i), (void**)&local(other));
{
if (return_code () == OK) {
if (local(me) != local(other)) collision (local(me),local(other));
local(i)++;
} else {
local(exit) = 1;
}
}
end
end module
The body of the module collide is an infinite loop in which
the collision event collide_evt is generated at each
instant. The sprite which generates the event is passed as value to
the generate_value function. Then, all generations of collide_evt are considered in turn, and the function collide is called for all (except of course itself) the generated
values, that are the other sprites. The return code becomes different
from OK (more precisely: ENEXT) when all the sprites are
processed. This is detected at the next instant, and there is thus no
need of an explicit cooperate to prevent the loop to be
instantaneous.
Actually, the collision function implements a very basic
algorithm which leads to some unrealistic moves; it can of course
be replaced by more realistic (but more expensive!) collision
treatments. Moreover, each sprite considers all others sprites, at
each instant which is inefficient (complexity in the square of the
number of sprites). The algorithm could certainly also be improved in
this respect.
8.3.4 Predators
The basic behavior of a predator is defined as the module predator:
module predator (sprite_t me,event_t pred_evt,event_t prey_evt)
local sprite_t other, sprite_t closest,
int min, int i, int finished;
while (1) do
{
local(i) = 0;
local(finished) = 0;
local(min) = predator_visibility;
generate_value (local(pred_evt), (void*)local(me));
}
while (!local(finished)) do
get_value (local(prey_evt),local(i), (void**)&local(other));
if (local(me)->dead) then return; end
{
if (return_code () == OK) {
int d2 = dist2 (local(me),local(other));
if (local(me) != local(other) && d2 < local(min)) {
local(min) = d2;
local(closest) = local(other);
}
local(i)++;
} else {
local(finished) = 1;
if (local(min) < predator_visibility && !local(closest)->dead)
chase (local(me),local(closest));
}
}
end
end
end module
At each instant, the event pred_evt is generated by each
predator. It is a valued generation, in which the sprite is passed as
value. Then, all values associated to the event prey_event
are considered in turn. When a new value is available, one tests if
the sprite is dead (it could have been killed just before); the
behavior returns if it is the case. Otherwise, the return code is
considered:
- if it is OK, then
other denotes the other
sprite. The distance to it is computed (actually, the square of it,
returned by dist2), and if the other sprite is distinct from
the sprite and closer than the one in the field closest,
then closest is changed.
- otherwise, the closest prey is chased, provided it can be seen
by the predator (according to the global variable
predator_visibility) and provided it is still alive (according to
its death field). The destroy event of the prey is
generated when it is killed.
The module defining a predator sprite is called predator_sprite:
module predator_sprite ()
local thread_t inertia;
{
sprite_t s = new_sprite (0,GHOST);
predator_create (s,pred_evt,prey_evt);
sync_sprite_create (s);
move_right_create (s,pred_run_step);
move_left_create (s,pred_run_step);
move_up_create (s,pred_run_step);
move_down_create (s,pred_run_step);
bounce_on_borders_create (s);
collide_create (s,pred_evt);
local(inertia) = inertia_create (s);
suspend (local(inertia));
}
while (1) do
await (a_pressed);
resume (local(inertia));
cooperate;
await (b_pressed);
suspend (local(inertia));
cooperate;
end
end module
The local variable inertia stores the inertia thread giving
the inertial behavior to the sprite. Initially, inertial is
suspended and the predator is thus immobile. When receving the event
a_pressed, inertia is resumed, and it is suspended
again with b_pressed. Initially, an atomic action is first
executed which performs the following actions:
- A new sprite
s is first created with a
zero speed vector and a ghost aspect.
- An instance of the module
predator is created. The
sprite and the events pred_evt and prey_evt are
passed to it.
- Several threads are created, all of them taking
s as
parameter: an instance of sync_sprite to perform
synchronisation of the sprite with the corresponding entry in the
table of sprites; four instances of move to move the
sprite in the 4 directions, according to 4 corresponding events;
an instance of bounce_on_borders to let the sprite bounce on
the borders of the applet; an instance of collide to let
the sprite collide with other predators.
- Finally, an instance of the module
inertia is created
and assigned to the local variable with the same name. The instance is
immediately suspended, using the suspend function.
Note that the various threads created are not stored in the behaviors field of the sprite. Actually, only inertia
will be accessed after creation, and one use a special local variable
to store it.
8.3.5 Preys
The prey sprite is defined in the module prey_sprite:
module prey_sprite ()
local sprite_t s;
{
sprite_t s = new_sprite (0,PACMAN);
alloc_behaviors (s,5);
s->behaviors[0] = inertia_create (s);
s->behaviors[1] = bounce_on_borders_create (s);
s->behaviors[2] = prey_create (s,pred_evt,prey_evt);
s->behaviors[3] = sync_sprite_create (s);
s->behaviors[4] = collide_create (s,prey_evt);
local(s) = s;
}
await (local(s)->destroy);
run destroy_sprite (local(s));
thread_deallocate (self ());
end module
The overall behavior is made of several components: the specific one,
called prey, an inertia behavior, a bouncing one, a
synchronisation behavior and a collision one. All these elementary
behaviors are stored in behaviors because they must be
destroyed when the prey is killed. The definition of the module prey is very close to the one of predator, with 2
changes: first, the events generated and observed are inverted;
second, the chase function is changed by a function that
make the prey run away from the predator.
After creation of the elementary behaviors, the destroy
event is awaited (let us recall that it is generated when the prey is
killed by the the predator). Then, an instance of the destroy_sprite module is run in order to deallocate the various
behaviors of the prey, and finally the executing thread is
deallocated.
8.3.6 Automatic Creation of Preys
The module automatic automatically creates new preys, after
a while, when there is none in the system.
module automatic (int delay)
local sprite_t other;
while(1) do
get_value (prey_evt,0, (void**)&local(other));
if (return_code () == ENEXT) then
repeat (local(delay)) do cooperate; end
repeat (NUMBER_OF_PREYS) do prey_sprite_create (); end
cooperate;
end
cooperate;
end
end module
At each instant, the event generated by preys (prey_evt) is
observed, using the get_value function. If no value with
index 0 is available, which means that no prey was present during the
previous instant, then new preys are created. Otherwise, the thread
simply cooperates.
8.3.7 Main Program
In the context of the GBA, the main module is called GBA_main.
module GBA_main()
{
prey_evt = event_create ();
pred_evt = event_create ();
create_key_events ();
key_handler_create ();
automatic_create (CREATION_DELAY);
predator_sprite_create ();
key_processing_create (l_pressed,predator_sprite_create);
key_processing_create (r_pressed,prey_sprite_create);
max_pred_speed = 10;
kill_dist2 = 200;
predator_visibility = 40000;
pred_run_step = 2;
max_prey_speed = 30;
prey_visibility = 8000;
prey_run_step = 3;
}
end module
First, the two events generated at each instant by preys and predators
are created. Then, events corresponding to keys are created with an
instance of the module key_handler which convert key presses
into events. An instance of automatic and one of predator_sprite are created. Finally, some global variables are set
to correctly parametrize the demo.
|