



Next: Conclusions
et perspectives Previous: État
de l'art
Sous-sections
Solution à base de contexte
Comme nous venons de le voir, l'élaboration d'un système
capable de gérer efficacement des séquences d'images pour
le suivi de personnes ou la représentation de scènes repose
sur une division préalable des problèmes. Cette séparation
des différents problèmes nous est imposée (cf. section
1.) par l'introduction, dans les traitements, d'algorithmes capables de
résoudre certains problèmes particuliers. Nous allons voir
dans cette section, que la résolution des problèmes évoqués
dans la section 1 requiert non seulement une classification claire des
difficultés et une subdivision des taches, mais aussi un apport
de connaissances externes. C'est sur cette idée que repose une nouvelle
solution logicielle, élaborée durant le stage, dont le fondement
est l'apport de connaissance divisible en deux points que sont l'information
externe concernant les humains et l'information externe concernant la scène
3D.
Nous verrons dans un premier temps une solution réalisée
en 1996, dans le cadre du projet ESPRIT PASSWORD dont l'architecture fut
le point de départ de la réalisation du stage. Ensuite, nous
détaillerons cette réalisation ainsi que les différents
modèle de connaissances externes qu'elle utilise.
Le logiciel de départ
Nous allons, dans ce qui suit, décrire le système opérationnel
de traitement de séquences d'images pour le suivi de personnes qui
est à la base des réalisations actuelles. Ce système
constitue un point de départ en matière d'architecture logicielle
et en matière de sensibilité aux changement de contexte (cf.figure ![[*]](cross_ref_motif.gif) )
.
)
.
Figure: la détection par seuillage paramétré
![\includegraphics[width=14cm]{images/img_proc.eps}](img_proc.jpg)
|
La détection
La technique utilisée pour l'extraction de régions d'intérêt
est la méthode de combinaison d'images avec image de référence.
Après une phase de seuillage paramétré (cf.figure )
et une série de filtrages (érosion et dilatation), chacune
des images fournit un ensemble de régions de taille et de caractéristiques
très diverses.
La reconnaissance
L'étape de reconnaissance utilise un modèle d'objets basé
sur l'apparence définie dans le plan image 2D par deux degrés
de liberté non-contraints que sont la hauteur et la largeur. L'algorithme
décidant de l'existence d'un objet consiste en un appariement global
des régions. Les techniques utilisées pour recomposer les
régions d'intérêt sont basées sur deux critères:
Deux régions dont les boites englobantes se recouvrent sont fusionnées.
Les régions faiblement éloignées sur l'axe vertical
sont aussi fusionnées. Cette technique a pour but de lutter contre
les problèmes de seuillage trop contraint ainsi que les problèmes
d'occultations statiques partielles.
L'appariement temporel
La méthode de suivi se base sur un critère de recouvrement.
Deux régions de deux images consécutives sont considérées
comme provenant du même objet si il existe un recouvrement spatial
entre les deux. Il en résulte un graphe temporel G(S, A) des objets
de la scène où S constitue l'ensemble des objets détectés
à chaque image et A l'ensemble des filiations entre les détections
au cours du temps. Cette filiation mettant en évidence la correspondance
d'un objet de la scène entre deux images consécutives. Cette
représentation très intéressante constitue un des
points forts du système.
Les conclusions
Après avoir détaillé l'architecture de ce logiciel
à travers la division classique des problèmes exposés
dans la section 2, nous allons analyser ses lacunes à travers la
grille de lecture présentée dans la section 1. Les problèmes
d'incertitudes, tout d'abord, sont globalement gérés par
un savant paramétrage. Le choix d'un <<bon>> paramètre
lors des phases de dilatation et d'érosion permet de minimiser l'influence
du bruit inhérent aux images. Le choix d'un <<bon>> paramètre
lors de la phase de seuillage de l'image de différence permet aussi
de réduire l'effet des ombrages sur le sol. Malheureusement, ce
paramètre de seuillage intervient aussi dans la résolution
des problèmes liés à l'incertitude objet. Un seuil
élevé (30 sur 255) réduit l'effet des ombres mais
augmente l'incertitude de la détection des objets eux-meme. Inversement,
un seuil bas (15 ou 20 sur 255) donne une détection nette des objets
mobiles mais rend le système très sensible aux ombres. Globalement,
le problème d'incertitude est contraint par l'utilisation d'un paramètre
<<aveugle>> réglé de façon externe. De plus,
l'utilisation de paramètre diminue l'adaptabilité du logiciel,
dans le sens où seule l'expertise de spécialistes en vision
permet de définir de tels seuils.
Les règles de fusion des régions mobiles (proximité
des régions) sont une tentative de gestion des problèmes
d'occultations statiques applicables dans des cas de scènes très
précises. Cette hypothèse est valide, si les objets de la
scène évoluent dans le même plan avec une caméra
respectant une certaine distance (une dizaine de mètres) et une
certaine inclinaison (environ 45 degrés) par rapport au plan de
référence de la scène. Dans les autres cas les règles
de fusion ne sont pas très robustes. Les occultations dynamiques
ne sont absolument pas gérées.
Les problèmes de suivi sont contingentés par l'utilisation
du critère de recouvrement spatial. Si deux régions de deux
images consécutives ont des pixels communs alors ils sont considérés
comme provenant du même objet. Ce critère est valide dans
une séquence d'images avec une fréquence d'acquisition d'image
suffisante si l'on considère des personnes marchant normalement.
Expérimentalement, ce critère se révèle suffisant
pour des scènes peu encombrées, constituées de personnes
indépendantes. Dans le cas de scènes encombrées le
graphe d'appariement temporel devient rapidement inexploitable. L'existence
de groupe de gens ne peut être traitée par ce critère
dans la mesure où plusieurs objets partagent fréquemment
le même espace du plan image. Les problèmes de mélange
et d'éclatement de pistes sont parmi les plus lourds handicaps de
ce système.
Pour résumer, le défaut majeur du système est
sa faible adaptabilité au changement de scènes. Il est clair,
que certaines des orientations prises sont basées sur des hypothèses
contextuelles (réparation des occultations statiques par exemple).
La non-utilisation de modèle d'objet, bien qu'elle fournisse un
résultat non biaisé, est aussi problématique dans
le sens où les résultats obtenus sont difficilement qualifiables
rendant particulièrement difficile l'étape de suivi (Lorsqu'un
éclatement de piste est observé, par exemple, il est difficile
de décider si il est légitime ou non). Il s'impose alors
de relier ces hypothèses à un cadre précis à
partir duquel puisse être qualifiées ces connaissances. De
façon générique, ce cadre correspond à celui
de connaissances contextuelles. Nous allons donc dans la suite détailler
l'organisation de telles connaissances utilisables par un système
informatique capable de résoudre plus efficacement les problèmes
de ce logiciel.
Les contributions
La suite constitue la contribution du stage a l'élaboration d'un
système de traitement de séquences d'image adaptatif et robuste.
Nous avons montrer plus avant la nécessité d'introduire de
l'information contextuelle dans les traitements. Nous verrons dans un premier
point quelques définitions de ce que nous appellerons par la suite
le contexte, puis nous détaillerons le nouveau système.
Le contexte statique
[Strat, 1993] décrit les différents
niveaux informations engagées dans le traitement de séquences
d'images. L'auteur distingue trois niveaux: les connaissances principales,
l'information contextuelle et l'information factuelle. Les connaissances
principales sont toujours valides, ne changent pas selon l'application
et durant le processus. L'information contextuelle est invariante durant
le processus, mais varie en fonction de l'application. Les informations
factuelles, enfin, varient non-seulement à chaque application mais
aussi durant les traitements. Dans [Bremond,
1997] on trouve une définition plus formelle de la notion de
contexte. Selon l'auteur, peut être considérée comme
information de contexte, toute information qui :
-

-
(1) conserve ses valeurs constantes durant le processus.
-
-
(2) ne conserve pas forcément ses valeurs constantes d'un processus
à un autre.
Nous prendrons dans la suite, cette définition comme référence.
En termes logiciels les données qui vérifient ces critères
correspondent à deux notions. La première constitue la généralisation
de ce que l'on cherche à reconnaître, c'est à dire
des humains. Un modèle d'humain s'impose donc. La seconde notion
qui remplit les critères contextuels correspond au décor
dans lequel on cherche à reconnaître quelque chose. Cette
notion sera appelée << contexte statique>>.
Figure: Les scènes
![\includegraphics[width=13cm]{images/img_scenes.eps}](img_scenes.jpg)
|
En pratique, le contexte statique se définit par un ensemble
de référentiels et un ensemble d'objets. Les objets sont
ceux de la scène réelle considérés comme fixes
(cf. figure ).
Les référentiels sont ceux impliqués dans les traitements;
on trouve au minimum le référentiel image 2D et le référentiel
scène 3D. Les connaissances contextuelles sont alors organisées
autour de ces deux thèmes avec tous les processus de mise en correspondance
souhaitable. Les processus minimum sont les mécanismes de passage
d'un référentiel à un autre et aussi les correspondances
des objets réels dans les divers référentiels. L'existence
d'une telle organisation apporte la possibilité d'obtenir des informations
supplémentaires sur les objets mobiles dans les autres référentiels
que celui de l'image 2D.
En pratique, il est alors possible d'obtenir des mesures 3D et des
localisations 3D des objets mobiles permettant l'utilisation de modèles
non directement liés à l'application échappant ainsi
au problème de paramétrisation. La connaissance des mesures
3D peut être utilisée pour les calculs de distances réelles
dans la scène, pour les objets mobiles ou statiques. Des informations
d'entrée sortie de personne dans la scène peuvent être
définies de façon robuste et utilisées de façon
stable pour les étapes de reconnaissance et de suivi. L'évaluation
de contexte locaux [] rendue possible par l'existence du contexte statique
facilite le traitement des occultations partielles dynamiques et statiques.
Cette structuration de l'information contextuelle des scènes
permet d'améliorer les possibilités du système au
niveau de la robustesse des traitements, comme nous venons de le voir,
mais aussi au niveau, de l'adaptabilité des traitements. Le regroupement
de l'ensemble des informations de même nature utiles à plusieurs
niveaux des traitements diminue la sensibilité du système
au changement de cadre. Si l'on souhaite changer la caméra de place
pour une même scène seul le plan image va changer. Si l'on
souhaite rajouter un caméra dans une scène existante, il
suffit de rajouter un référentiel image à l'ensemble
de ceux déjà existants. Si un objet considéré
fixe dans la scène est modifié, il suffit alors de changer
ses propriétés et ses correspondances dans l'ensemble du
contexte. L'unification des informations de même nature, concernant
le contexte, permet d'augmenter la robustesse et l'adaptabilité
d'un système de traitement de séquences d'images.
L'instanciation du contexte statique dans le système réalisé
durant le stage est constituée de trois référentiels:
un 3D de la scène, un 2D de l'image, un 2D du sol. Le premier est
utilisé pour les mesures 3D de l'étape de reconnaissance.
Le second est la base de l'étape de détection et le troisième
durant l'étape d'appariement temporel. L'utilisation d'un modèle
de caméra sténopée [Robert,
1993] permet d'obtenir les matrices de passage en coordonnées
linéaires homogènes du référentiel 3D à
un référentiel 2D. Une hypothèse supplémentaire,
dite du point bas, permet d'évaluer les mesures 3D d'un objet 2D
de l'image. Le principe est de prendre le point bas d'une région
mobile comme appartenant au plan du sol de la scène.
Les contraintes fortes de l'emploi de contexte statique sont les
problèmes de calibration de la caméra ainsi que les problèmes
d'acquisition de l'information contextuelle, lourde à mettre en
oeuvre. L'hypothèse du point bas n'est pas forcément valide
si les problèmes d'ombrage ne sont pas résolus.
La solution proposée, comprenant un module gérant les
informations contextuelles, va être détaillé dans la
suite de ce document en reprenant l'architecture détaillé
dans la seconde section (cf. figure ).
Figure: Une solution à base d'informations contextuelles
![\includegraphics[width=12cm]{images/img_trait_hist.eps}](img_trait_hist.jpg)
|
Figure: La distribution des valeurs prises par les paramètres
du modèle humain
![\includegraphics[width=6cm]{images/humo_haut.eps}](humo_larg.jpg) ![\includegraphics[width=6cm]{images/humo_haut.eps}](humo_haut.jpg)
|
Figure: La distribution des valeurs prises par les paramètres
combinés hauteur et largeur
![\includegraphics[width=6cm]{images/humo_larg-haut.eps}](humo_larg-haut.jpg)
|
La détection
Un module spécialisé a été réalisé,
intégrant la plupart des méthodes de la famille de combinaison
d'images (voir sous-section ).
-
-
(1) Iresultat
= Abs(Diff(I0, It))
-
-
(2) Iresultat
= Max(Abs(Diff(It, It-1)),
Abs(Diff(It+1, It)))
-
-
(3) Iresultat
= Max(Abs(Diff(It, I0)),
Abs(Diff(It+1, It)))
-
-
(4) Iresultat
= Abs(Diff(It+1, It)))
Ceci permet de changer d'instance de cette classe par la modification
d'un simple paramètre. En pratique, les expériences ont été
réalisées par combinaison d'image avec une image de référence
car la possibilité d'avoir une image de référence
nous était donnée sur toutes les séquences d'images.
Les expériences réalisées avec les autres méthodes
donnent un résultat moins intéressant pour les algorithmes
de reconnaissance utilisés dans la suite. Les méthodes (2)
et (4) ont tendance à accroître le nombre des détections
en segmentant une personne en trois ou quatre régions. On peut expliquer
cela par le fait que les objets qui nous intéressent (les personnes)
sont souvent vêtus d'habits unis non-texturés difficiles à
gérer par ces méthodes. De plus ces méthodes ne sont
pas sensibles au personnes immobiles dans la scène, ce qui est parfois
le cas dans nos séquences. Quant à la troisième méthode,
elle réunit les propriétés des méthodes (1)
et (4), surévaluant la aussi le nombre de détection souhaité.
Cette méthode peut être intéressante pour définir
de vastes régions d'intérêt pourvu qu'elle puisse être
couplée avec une méthode de reconnaissance capable de re-sélectionner
parmi ses résultats.
La reconnaissance d'humain
L'accent a été mis sur la reconnaissance de personne.
Pour cela le système utilise un modèle d'objet à trois
paramètres. Le modèle d'objet est défini par sa vitesse,
sa hauteur et sa largeur. (cf. figures ,
et ).
Ces paramètres sont considérés dans le référentiel
3D-scène via le module de contexte statique. En ceci, ce modèle
ne peut pas être considéré comme un modèle d'apparence
mais comme un modèle d'objets réels bien qu'il n'y ait pas
de considération volumique. L'instrument de la reconnaissance est
un traitement par contraintes de ces mesures. On définit une borne
supérieure et une borne inférieure pour chacun des degrés
de liberté. Ainsi durant la phase de reconnaissance, on cherche
à construire de façon itérative une combinaison de
régions dont les mesures 3D ne dépassent pas les bornes supérieures
du modèle. Les combinaisons, dont les mesures sont inférieures
à la borne inférieures sont ensuite filtrées. Quant
au troisième degrés de liberté, nous reviendrons sur
son utilisation dans la section suivante concernant l'appariement temporel.
L'algorithme de reconnaissance (cf. figure )
est donc divisé en deux étapes : une phase de construction
et une phase de filtrage.
Figure: L'algorithme de reconnaissance
 |
Quatre instances de cet algorithmes, différant par le critère
de choix des étapes (C1), (C2) et (F1) ont été utilisées.
-
-
(1) instance basique : (C1), (C2) et (F1) ne sont pas contraints, les régions
sont prises dans un ordre arbitraire fourni par le module de détection.
-
-
(2) <<focus of attention>> : (C1), (C2) et (F1) ne sont pas contraints,
mais l'ensemble des détections est divisé en sous-ensembles
de détections définis dans certaines régions d'intérêt
dans l'image obtenues grâce au suivi.
-
-
(3) ordonnancement global : (C1) est fait en fonction de la position de
la région dans l'image. La région située le plus bas
dans l'image est choisi d'abord.
-
-
(4) ordonnancement relatif : (C2) est fait en fonction du résultat
de (C1). On choisit en (C2) la région la plus proche de celle choisie
par (C1).
Les méthodes basées sur un ordonnancement de l'espace
de recherche sont relativement similaires dans leur approche et dans leurs
résultats. Ces deux méthodes ont l'avantage de fusionner
prioritairement des régions proches les unes des autres. Ceci correspond
à l'intuition que deux régions proches appartiennent plus
facilement au même objet que deux régions éloignées.
Ceci optimise donc la construction des objets mais est assez sensible à
la proximité de deux personnes dans l'image. La méthode basée
sur les <<focus of attention>> a comme avantage de réduire
l'espace de recherche de façon drastique au départ de l'application
de l'algorithme à certaines régions de l'image définies
par les résultats du suivi, mais cette méthode est très
sensible aux pertes de suivi. En effet, si une piste est inopportunément
perdue, alors il n'y aura pas de région d'intérêt associée
et donc pas de construction d'objet à l'étape suivante. L'utilisation
d'un tel algorithme est problématique en soi. Bien que celui-ci
limite l'explosion combinatoire lors de la recherche d'une solution en
acceptant la première solution acceptable par les contraintes du
modèle, il semble que de nombreuses solutions plus intéressantes
échappent à l'algorithme, ce qui est préjudiciable
aux étapes suivantes. L'avantage de ce modèle est l'utilisation
de paramètres n'étant pas liés à l'application
(i.e. les bornes Inf et Sup sont définies
de façon externe.) Ceci augmente donc la robustesse et l'adaptabilité
du système. Les inconvénients sont multiples. Tout d'abord
l'utilisation de mesures générées par le module de
contexte statique rend la décision prise sur la qualification d'un
objet sensible aux erreurs faites par ce module. En pratique, on s'aperçoit
que la calibration joue un rôle prépondérant. Compte
tenu du matériel expérimental, notre modèle est trop
imprécis (cf.figures , ,
et ).
En effet, le seul paramètre convenable est la hauteur pour laquelle
3 % d'erreur nous autorise un intervalle de valeurs égal à [144,
196] (en centimètres), ce qui ne parait pas inexploitable. Le
paramètres moyen est la vitesse (en centimètres par images
à 5 images seconde). Avec trois écarts type 94 % des valeurs
sont traitées. Ce qui autorise 6 % d'erreur de reconnaissance, soit
un intervalle égal à [0, 65]. Ces valeurs ne paraissent
ni inexploitables, ni aberrantes. Toute fois, il aurait été
souhaitable d'obtenir un intervalle plus petit (au moins pour la borne
Sup) pour les besoin du suivi (cf.sous-section ).
En revanche, le paramètres de largeur n'est pas satisfaisant. 4
% d' erreurs nécessite un intervalle égal à [23,
113] ce qui est trop. cette étalements des valeurs s'explique
par un fort écart type (15 centimètres, soit plus d'un quatre
de la moyenne) causé par la non-rigidité des objets á
reconnaître (l'oscillation des bras et des jambes).
Figure: Les statistiques du modèle d'humain
![\includegraphics[width=8cm]{images/anal_num.eps}](anal_num.jpg)
|
Comme le montrent les différents graphiques de données
recueillis à partir de sept cents images, les trois degrés
de liberté associés à notre modèle ont une
trop forte variance pour servir de critère de décision fiable.
Nous verrons dans les perspéctives (sous-section )
des pistes pour palier à ce problème.
L'appariement temporel
Comme nous l'avons vu, les problèmes posés par l'étape
de suivi du logiciel de départ étaient importants. Nous avons
réalisé dans ce logiciel un module de suivi indépendant
qui réalise l'appariement temporel selon différentes politiques.
-
-
(1) méthode basée sur la proportion de recouvrement
-
-
(2) méthode basée sur la similarité des régions
-
-
(3) méthode hybride basée sur (1) et (2)
-
-
(4) méthode basée sur la localisation 3D
La méthode basée sur la proportion de recouvrement consiste
à décider que deux régions proviennent du même
objet si le pourcentage de recouvrement dépasse un certain seuil.
La méthode basée sur la similarité des régions
consiste à décider comme provenant du même objet deux
régions dont les boites englobantes sont semblables. Cette similarité
entre deux boites englobantes est calculée grâce à
une fonction faisant intervenir la largeur et la hauteur des régions.
La méthode hybride réunit les conditions des deux méthodes
précédentes soit par un Et logique soit par
un Ou logique. Le point commun de ces méthodes est
l'utilisation des caractéristiques 2D du modèle, la décision
de suivi est prise dans le plan 2D image. Ces méthodes fournissent
un résultat intéressant dans les cas d'objets proches de
la caméra et relativement bien détectés. Ces méthodes
n'utilisant pas d'information 3D sont indépendantes de la qualité
du module de contexte. Par contre, elles n'ont aucun recours pour traiter
les occultations. De plus les objets à traiter n'étant pas
rigides leur variation d'apparence rend les critères d'appariement
2D peu fiables dans le cas général, notamment dans les scènes
encombrées.
La méthode (4) utilise des paramètres 3D du modèle
pour apparier les objets. Cette méthode de suivi est basée
sur l'utilisation d'une matrice d'ambiguité (cf. figures )
que l'on definit de la façon suivante : Soit deux images consécutives
It-1 et It
dans lesquelles on a reconnu respectivement les ensembles d'objets Et-1
= (O0,. .., Oo) et Et=(N0,...,Nn).
On definit une matrice 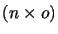 telle que Cij soit le critère d'appariement
temporel entre Oi et Nj.
telle que Cij soit le critère d'appariement
temporel entre Oi et Nj.
-
-
Cij=0 si la distance entre Oi et Nj
est supérieure à la borne Sup du paramètre
vitesse du modèle d'humain.
-
-
Cij=1 si la distance entre Oi et Nj
est inférieure à la borne Sup du paramètre
vitesse du modèle d'humain.
Figure: La distribution des valeurs prises par le paramètre
dynamiques du modèle humain
![\includegraphics[width=6cm]{images/humo_vits.eps}](humo_vits.jpg)
|
La matrice obtenue est une matrice
définie dans (0,1) où la valeur 1 signifie une filiation
entre deux objets. Cette filiation est dite non-ambiguë si à
un objet de It-1 correspond au plus
un objet de It et réciproquement. Tous
les autres cas sont dits ambigus. Cela signifie qu'une matrice idéale
est une matrice telle qu'il existe au plus un 1 sur une ligne et sur une
colonne. Les traitements associés à l'appariement temporel
visent à transformer la matrice obtenue afin de la rendre idéale.
Rendre idéale cette matrice, lever les ambiguïtés, revient
alors à reconnaître des motifs qualifiant certains problèmes.
Par exemple, une colonne Ni de valeurs nulles
signifie que l'objet Ni n'a pas pu être
apparié avec un objet de l'image précédente. Une ligne
Oj de valeurs nulles signifie que cet objet n'a
pas trouvé d'appariement dans l'image courante. De même une
ligne ou une colonne contenant plus de une valeur égale à
1 signifie que l'objet en question peut s'apparier avec plusieurs objets
distincts.
Figure: Matrice d'ambiguité
![\includegraphics[width=10cm]{images/img_matric.eps}](img29.gif)
|
Le suivi n'est pas un problème totalement résolu. Bien
que l'utilisation d'informations contextuelles rende intelligible les problèmes
liés à l'appariement temporel, il est clair qu'un suivi robuste
doit être réalisé à partir d'information 3D.
La figure
illustre ce propos en montrant les résultats comparés des
logiciels avec ou sans module de contexte statique. A gauche, le logiciel
de départ (sans information contextuelle), ne gérant pas
les problèmes d'occultations dynamiques, produit un graphe temporel
inexploitable. A droite, le logiciel utilisant un module d'information
de contexte est capable de résoudre les problèmes d'occultations
dynamiques.
Les conclusions
Nous pouvons maintenant admettre que l'utilisation d'informations contextuelles
ne relève ni du gadget ni d'un raccourci de traitement. Son recours
est essentiel à la qualification de la plupart des problèmes
évoqués dans notre grille de lecture décrite dans
la première et la seconde section. En effet la plupart des difficultés
à résoudre proviennent du manque d'information 3D et d'information
de la scène en général, que se soit sur la nature
des objets qui nous intéressent ou sur le décor, l'environnement
du traitement.
Figure: Comparaison des résultats des logiciels
avec ou sans contexte

Clicker sur chacune des images pour obtenir les versions mpeg (370 Ko)
|
Next: Conclusions
et perspectives Previous: État
de l'art
Nathanael Rota
1998-09-22