C O M P L E X N E T W O R K S |
Network science (aka the science of Complex Networks) has emerged in the last ten years as an inter-disciplinary and yet distinct research field, seeking to discover common principles, algorithms and tools that govern networks as different as the Internet, the web, human social networks, gene regulatory networks, the brain, ecosystems, social organizations, transport networks. "How Kevin Bacon cured cancer" is a very nice introductory video to this new science, including interviews to many of the pioneers in this field.
This winter school is the opportunity to learn about the fundamentals of network science, but also to get exposed to ongoing research activities. All the professors are researchers actively working in this field, so they will provide their first hand point of view.
The target audience is made by master students. The participation is guaranteed to the students of the Master 1 International in Computer Science. PhD students from the local PhD schools or from other institutions are welcome to attend. The participation is free of charge, but registration is required (how to register).
This is the fifth edition of this school. Links to previous years: 2014, 2015, 2016, 2017.| Thursday 11/1 | Friday 12/1 | Monday 15/1 | Wednesday 17/1 | Thursday 18/1 | Friday 19/1 | |
| Morning | Epidemics in Complex Networks (part 2) (rooms k1-k2, 8.00-10.00) G. Neglia R&D Networks : Theory and Empirical Evidence (rooms k1-k2, 10.15-12.15) M. Napoletano |
Software tools for Complex Networks analysis (rooms k1-k2, 8.00-12.00) F. Huet |
Random-Walk based algorithms and classification (room 282, 9.00-12.00) K. Avrachenkov |
|||
| Lunch break | ||||||
| Afternoon | Introduction to Complex Networks (rooms k1-k2, 14.00-16.00) G. Neglia Epidemics in Complex Networks (part 1) (rooms k1-k2, 16.15-18.30) G. Neglia |
Navigation in Small Worlds (rooms k1-k2, 14.00-17.00) N. Nisse |
Semantic Web and Linked Data Graphs (room 282, 14.00-17.00) F. Gandon |
Statistical learning on Networks with textual edges: the Enron case (room k1-k2, 14-16) C. Bouveyron Unveiling the structure of social networks: the Twitter case (rooms k1-k2, 16.15-17.45) A. Legout |
Complex Network Analysis for Mobility Modeling (rooms k1-k2, 14.00-15.30) T. Spyropoulos |
Exam (room 282, 14.00-16.00) |
In this lesson we introduce the different definitions of complex networks and we question if network science is really a new science. We look at different topological properties usually present in complex networks (small diameters, high clustering, heavy-tailed degree distribution) and we present some random graph models that can explain how these properties can arise.
Prerequisites: basics of probability, elementary differential equations solving
Slides: Lecture
Some references on random walks: lecture notes from a course taught by Aleksander Mądry, a more advanced survey paper from László Lovász
Back to planning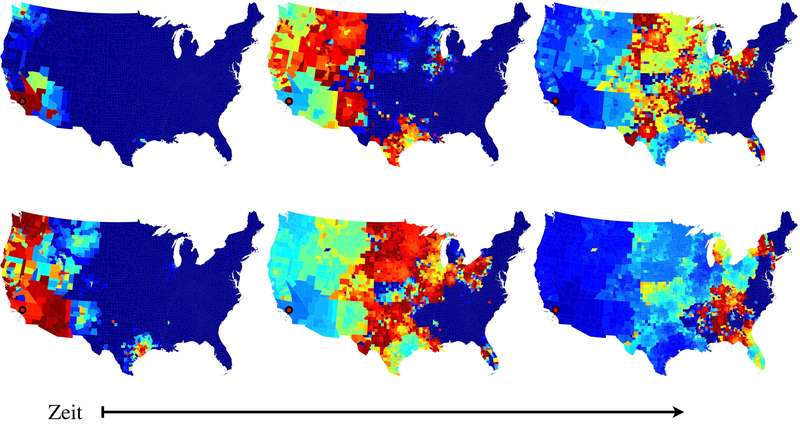
In this lesson we study models proposed for viral phenomena in networks, which include diseases' propagation as well as tweets' cascades or viral marketing. In particular we focus on how the characteristics of complex networks affect epidemics' dynamics.
Prerequisites: basics of probability, elementary differential equations solving
References: Sections 27.1-27.6 of Easley and Kleinberg, Networks, Crowds and Markets (a pre-publication draft of the book is available here) , Sections 9.1-9.2 of Barrat, Barthélemy and Vespignani, Dynamical Processes on Complex Networks. Notes about infection spread in heterogeneous networks [pdf]
Back to planning
Typical questions in the analysis of large complex networks are how large is a network in terms of nodes and links? which nodes are most important/central? the degree distribution follows a power law? if yes, what is the exponent of the power law? how to estimate quickly the clustering coefficient? how to detect quickly principal clusters/communities of the network? All these questions can be answered with the help of the theory of random walks on graphs. In particular, using the theory of random walks on graphs, we can design algorithms with linear or even sublinear complexity. Such light complexity is necessary if we need to deal with networks of billions of nodes and links.
Back to planningAnalyzing complex networks can be done using various software, depending on the type of analysis, the size of the graph and the runtime environment. Choosing the one best adapted to the problem at hand can make a world of difference. The aim of this lecture is to give a broad (but non exhaustive) view of some of the most commonly used frameworks for analyzing complex graph. We will present the various programming models used and focus on three frameworks: Networkx, Giraph, Hadoop. The following topics will be addressed
Slides: Lecture, Practical session
Back to planning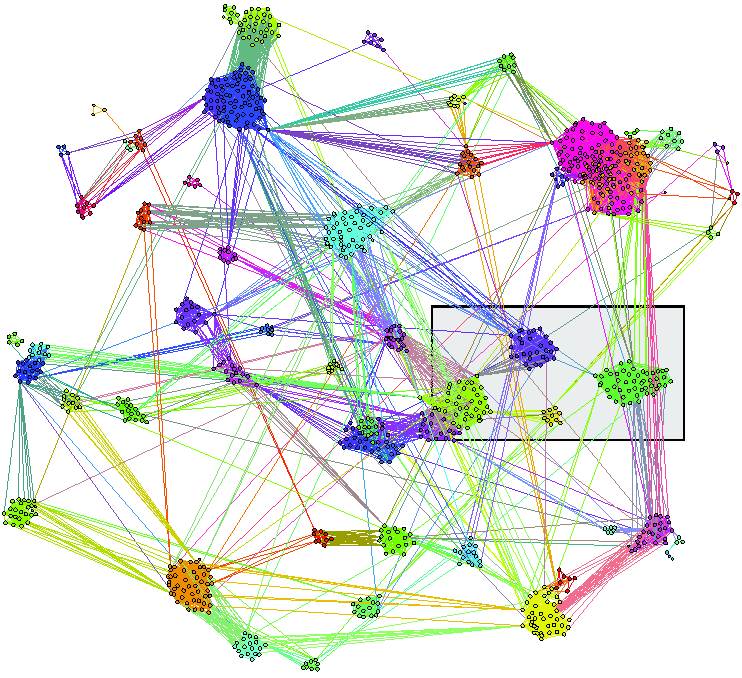
Realistic mobility models are crucial for the simulation of wireless networks, where mobility plays a key role (e.g. device-to-device networking, vehicular networking, etc.). When mobility is driven by social actors (e.g. humans carrying mobile devices, human-driven vehicles, etc.) the underlying social networks of these actors and the locations they are moving between, will significantly affect the observed mobility behaviors. Understanding these (hidden) underlying links can be done by macroscopic analysis of mobility traces using complex/social network analysis, where rather than focusing on micro-time scales and individual interactions, one builds a (complex) graph of node interactions over a larger time scale. Observing the properties of the graph has been shown to lead to better algorithm design, and performance predictions formulas (e.g. of information dissemination) that would otherwise be very difficult to obtain, among other things. This lecture will comprise:
Slides: Lecture
Back to planning
The Milgram experiment (1967) has shown that the "human network" has small diameter and that short paths could be found using only local knowledge. Various theoretical models have been proposed in order to understand this behaviour. Augmenting graphs (Kleinberg 2000) provide an interesting approach for this purpose. An augmenting graph consists of an undirected graph (representing the global knowledge) plus some directed links that are only known locally. We survey some recent results based on the seminal work of Kleinberg. In particular, we show how greedy routing schemes may perform well on these networks. To conclude this talk (if time allows), we will present some algorithms that have recently allowed to compute the diameter of large social networks.
Prerequisites for the lesson: basics of probability, basics of graph theory
Material: Slides, Kleinberg's technical report, 2015 notes
Back to planning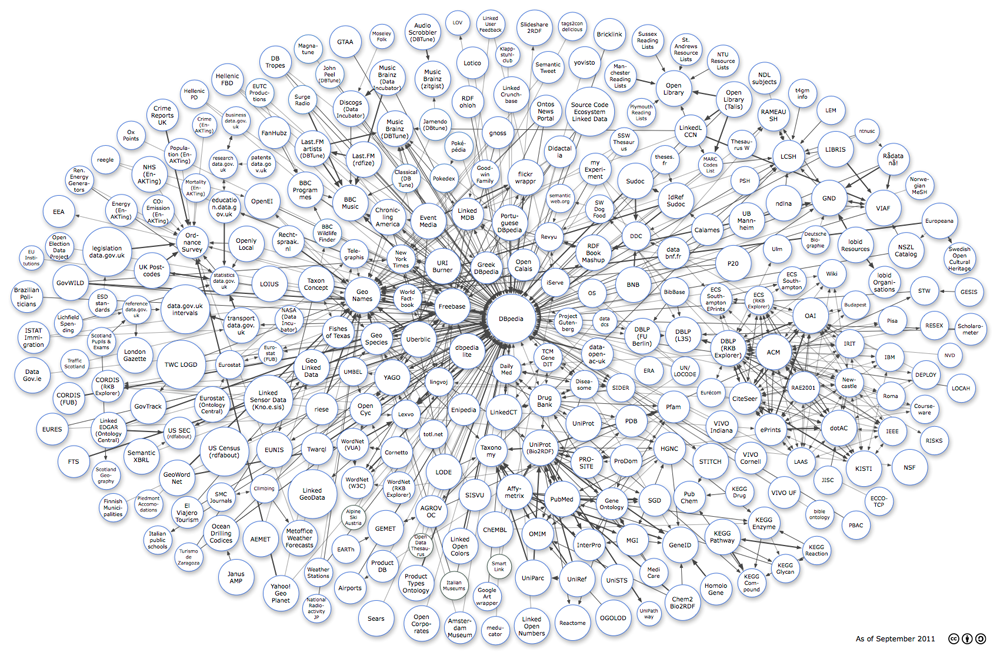 Teacher: Fabien Gandon
Teacher: Fabien Gandon
This course will provide an introduction to the semantic web graph formalisms with both an historical perspective and an explanation based on the web architecture core concepts. We will first introduce RDF as a W3C standard oriented labelled multi-graph model for data linkage on the web. We will then proceed with the SPARQL query and manipulation language for RDF data and RDFS and OWL schema languages to type and reason over RDF data. Applications and practical sessions will use the Corese/KGRAM engine.
Prerequisites:Slides: Lecture
Back to planning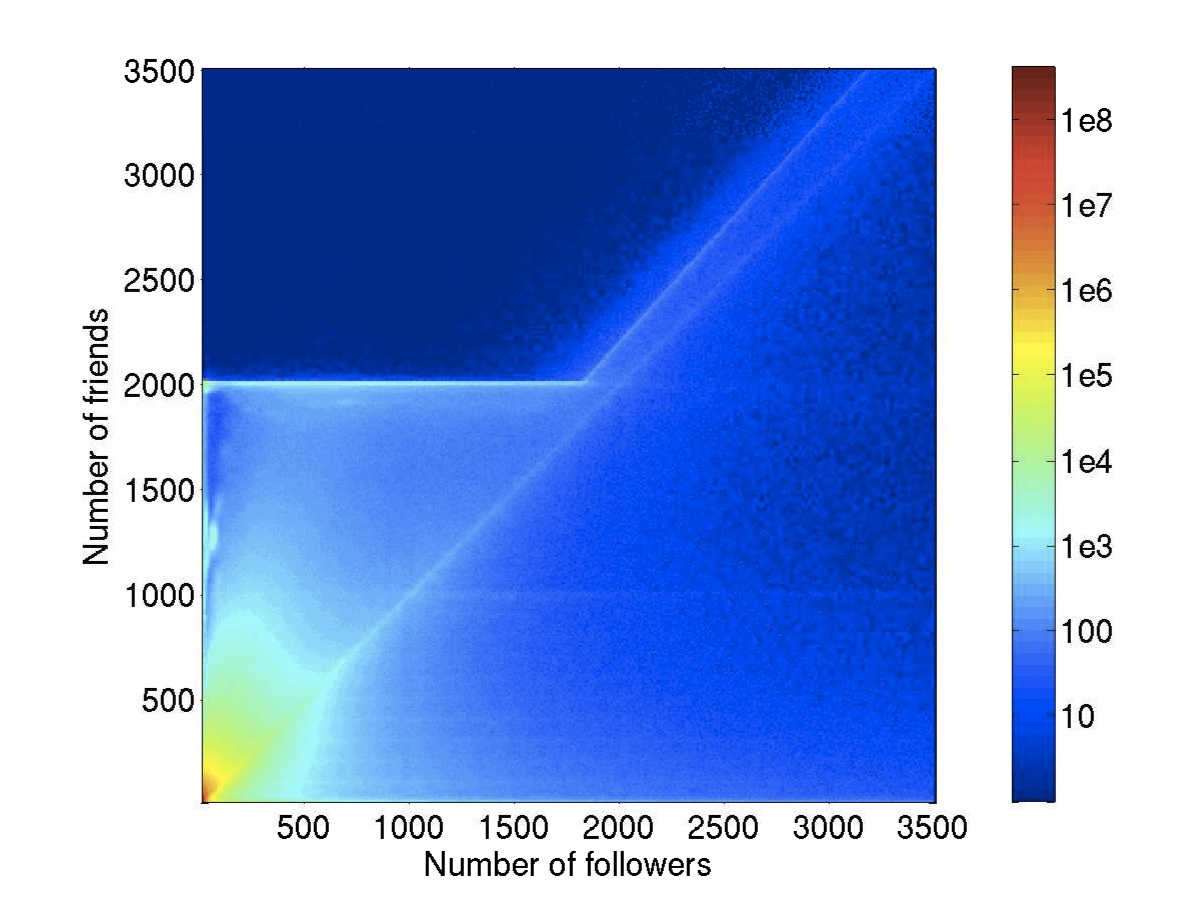 Teacher: Arnaud Legout
Teacher: Arnaud Legout
In this course, we will explore how to practically unveil the inner structure of social networks, and we will discuss its possible applications. We will use as a use case, Twitter, the most popular micro blogging system, with more than 500 millions users. In a first part, we will show how such a large system can be crawled in order to retrieve the full social graph interconnecting Twitter accounts. Then, we will show how to unveil the inner structure of this social graph using. We will discuss both simple theoretical aspects and practical issues. Finally, we will present how to sample a social graphs, discuss the bias of state of the art techniques, and explain how to solve this bias.
Prerequisites: classical computer science background (internet protocols, basic graph theory).
Slides: Lecture
Back to planning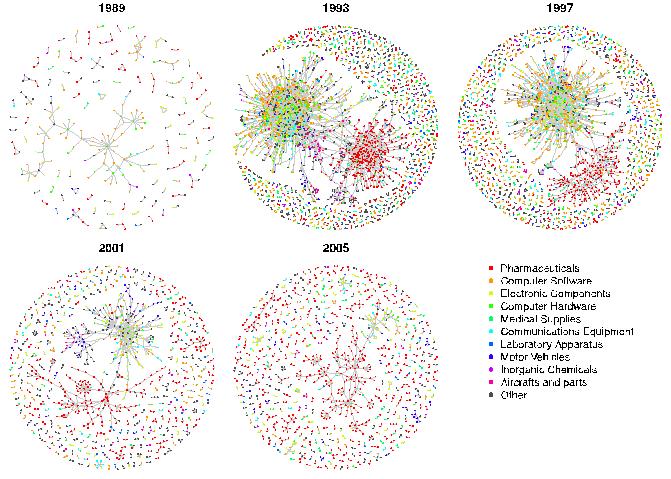 Teacher: Mauro Napoletano
Teacher: Mauro Napoletano
The past decades have witnessed a significant growth in the number of formal and informal R&D collaborations. In addition, several studies have documented the importance of studying how the structure of R&D networks affects the creation and diffusion of creation of knowledge in industries , and how it affects the innovative performance of firms in the network. The lecture will present theoretical models that have been used to study the efficiency of R&D networks, and to study which networks structures emerge when firms choose the partner with whom to collaborate on the basis of economic incentives. Next, it will discuss empirical works that have investigated the properties of empirically observed R&D networks and tested the validity of some of the predictions of theoretical models.
Pre-requisites: basics of linear algebra, calculus, basics of graph theory.
Material: course slides. Further readings will be provided during the lecture
Back to planning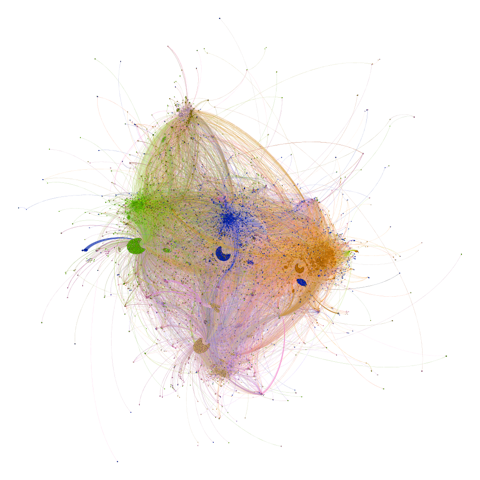 Teacher: Charles Bouveyron
Teacher: Charles Bouveyron
Due to the significant increase of communications between individuals via social media (Facebook, Twitter, Linkedin) or electronic formats (email, web, e-publication) in the past two decades, network analysis has become an unavoidable discipline. Many random graph models have been proposed to extract information from networks based on person-to-person links only, without taking into account information on the contents. In this course, we introduce the stochastic topic block model, a probabilistic model for networks with textual edges. We address here the problem of discovering meaningful clusters of vertices that are coherent from both the network interactions and the text contents. A classification variational expectation-maximization algorithm is proposed to perform inference. Simulated datasets are considered in order to assess the proposed approach and to highlight its main features. Finally, we demonstrate the effectiveness of our methodology on two real-word datasets: a directed communication network and an undirected co-authorship network. Trainees will be able to use the algorithm on their own data through a SAAS platform.
Prerequisites: Basic notions in graph and network theory.
Material: Ecclesiastical network, Enron network
Back to planningThe participation is guaranteed to the students of the Master 1 International in Computer Science. PhD students from the local PhD schools or from other institutions are welcome to attend, but they need to register by sending an email to the school organizer Giovanni Neglia. Participation will be granted to a maximum of 20 students on a first-come, first-served basis. This winter school is recognized by the Ecole Doctorale STIC. Every participant should check the prerequisites and bring his/her own laptop with the required software installed.
BackThe lessons suppose a basic background on probability (some notes are available here), graph theory and internet protocols. The practical sessions require also a knowledge of Python and Java.
Every student should have a laptop with the following software installed: Python (2.x), Java (JDK7 or later), Java Virtual Machine.
BackThe school will be located on the SophiaTech campus. A plan and directions are available here.
Lessons will be given in the r(ooms K1-K2 of Inria's Kahn building or in room 282 of the university building Lucioles (map).
BackThe students of the Master 1 International in Computer Science and of the Master EIT Digital Data Science have to pass an exam in order to get the corresponding credits. The students will have to answer one open-ended question for each of the module of the winter school.
Back![]()