ProbDB is built on top of a classical Database management system. It adds probabilistic functionalities to the DBMS that are transparent to the user. Instead of directly modifying the DBMS and adding "native" possibilities to it, we have chosen to use Java to access the database, and thus to be able to change the used DBMS with a slight programming effort. In its current version, the prototype uses a PosgreSQL database, but could easily be adapted to work on a MySQL database for instance.
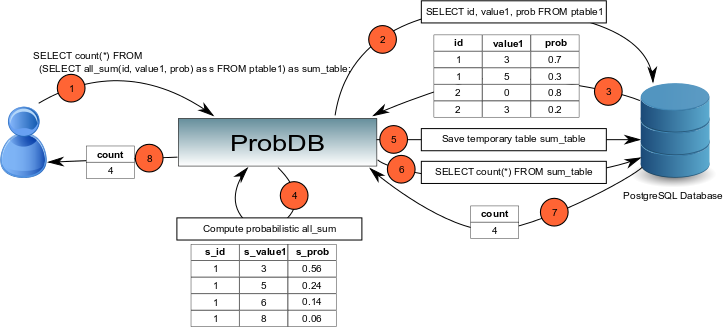
When the user send a query to ProbDB, the query is analysed and probabilistic keywords are extracted. The engine then send classical queries to the DBMS and applies the probabilistic functions to the intermediate results, and can send more queries to the DBMS depending on the initial query. Once the initial query is entirely processed, the final result is sent to the user.
For needs of homogeneity, the different probabilistic operations are processed under the tuple-level model with mutual exclusions. In the next section, we describe the internal model of a probabilistic database, then we run a query on a small instance.
Prototype Architecture
When a user submits a query to ProbDB, the query is processed in order to determine what is the probabilistic par of it. The picture below shows the execution steps for a probabilistic query on ptable1.