ProbDB is composed of the following components (see the architecture in Figure 1):
- Query parser
- it is responsible for separating the probabilistic parts of the query from the ordinary ones. Let Q be the query given by the user, the parser divides it to two parts: 1) Q'Ā: the subquery that can be evaluated by a deterministic DBMSĀ; 2) Q"Ā: the parts of the query that need special probabilistic algorithms for being evaluated.
- Query reformulator
- this component reformulates the subquery Q' to a query which can be executed by the underlying deterministic DBMS over the data stored in the database. It needs the metadata of the probabilistic tables in order to translate each relation of Q' into one or more probabilistic relations in the database.
- Deterministic DBMS
- this is an ordinary (deterministic) relational database management system that given the reformulated Q' (denoted by R(Q')), executes it over the probabilistic tables, and returns the results to the component that evaluates the probabilistic parts of the query. In the current version of ProbDB, we use PostgreSQL as deterministic DBMS.
- Probabilistic evaluator
- The inputs of this component are the intermediate data generated by the DBMS and the query Q". According to the probabilistic expressions in Q", the component chooses the appropriate algorithms and runs them over the intermediate results, and returns the final results to the user.
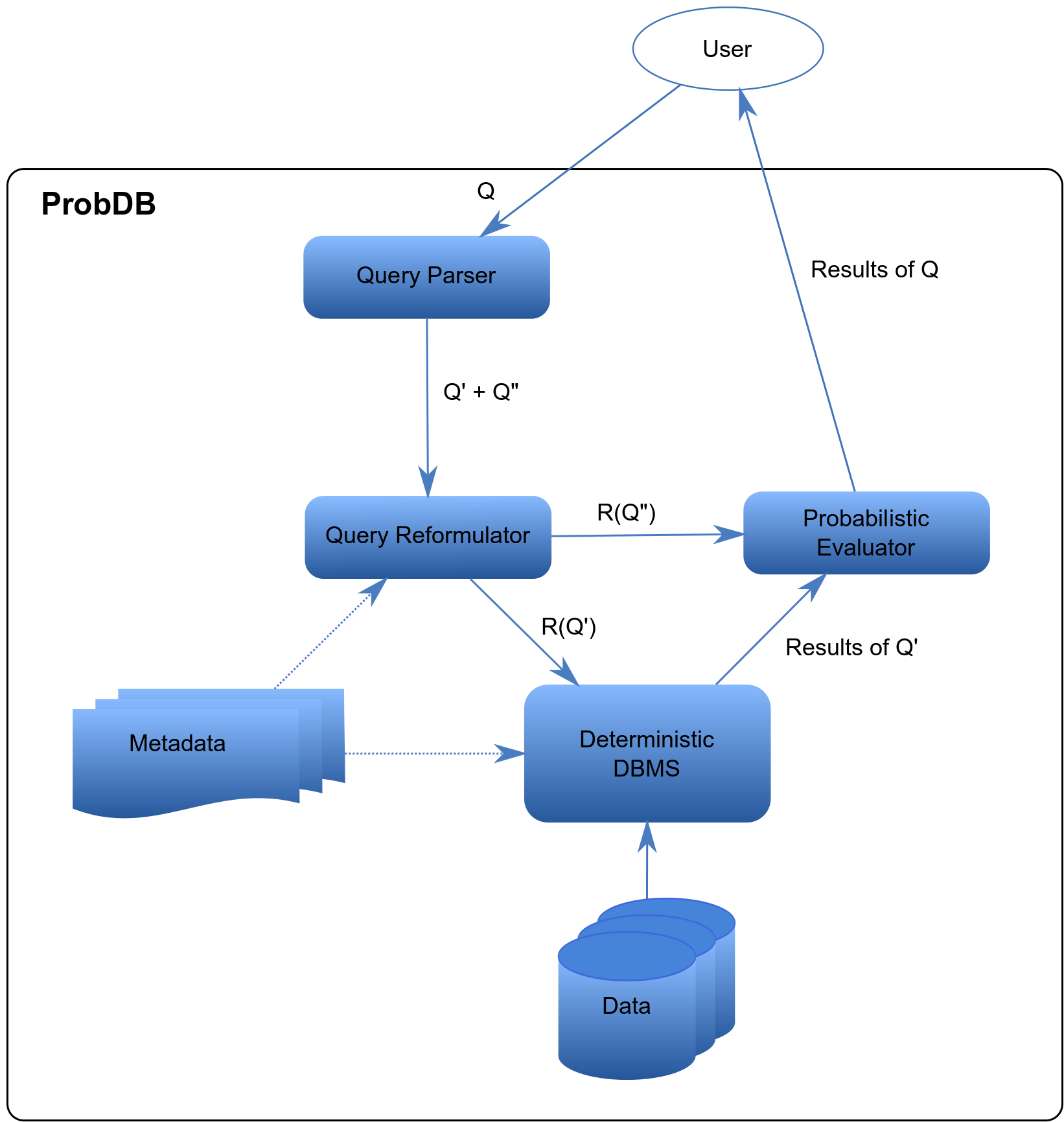
Figure 1
