


When using the terms “historical survey”, we intend to sum up what the situation of the preterite-present verbs is from a diachronic and a synchronic point of view.
We use the word ancestors of modal verbs for many of them have become modal verbs in contemporary English. The status of the preterite-presents is the same whoever the different authors or grammarians are. Let us briefly sum up what has been written about them, both by French and Anglo-saxon writers.
About these verbs, Fernand Mossé said that “ce sont des verbes mixtes à alternances vocaliques qui rentrent presque tous dans les classes connues de verbes forts” ((45) ((45)) : 118) (note: ➳). As for André Tellier, he had chosen to
(...) entreprendre cette étude sémantique et syntaxique en prenant [les perfecto-présents] non comme des vocables isolés mais comme les éléments d´un ensemble (...) ((65) ((65)) : 10) (note: ➳).
In his grammar of Old English, dealing with the different classes of verbs, Alistair Campbell added:
There is also a class of verbs known as the preterite-present verbs: they are not numerous, but most of them are very common ((7) ((7)) : 295, 726).
Furthermore, Cynthia Allen considered that there existed no class nor category for modal verbs:
There is no justification for including the category “modal” in the grammar of Old English unless it can be demonstrated that modal verbs behave differently from other verbs ((2) ((2)) : 92).
As for Ian Roberts, he drew a parallel between Old English, Middle English and contemporary English:
(...) modals were formerly much closer in distribution to main verbs than they are in present-day English.
(...) we assume that at least some of the premodals [les perfecto-présents] were θ-assigning verbs base-generated in V. Since we have no evidence that a given premodal was not base-generated in V, we extend this account to all premodals. So we treat the ME [and OE (note: ➳)] premodals as a class as main verbs with sentential complements (...) ([59] : 310-3).
Anthony Warner finally concluded that:
In OE, all [the preterite-presents] shared major properties with the rest of the class of verbs, and were clearly to be identified as members of this class ([72] : 97).
(...) the ancestors of today´s modals and other auxiliaries share a range of properties with verbs throughout Old and Middle English. And though some of these properties (like the possession of a distinct subjunctive inflection) weaken, other develop. Thus, there is evidence that these words continue to be rather closely related to verbs even in late ME (Idem : 102).
Following the quotations that have just been made, one has to remember that the preterite-present verbs have always been considered as verbs so far, the same way we consider strong and weak verbs (note: ➳).
But before going any further, let us give the definition of the term preterito-presents as found in [45] : 118.
On appelle verbes perfecto-présents un certain nombre de verbes qui ont la forme d´un parfait indo-européen et la valeur sémantique d´un présent. (note: ➳)
He further added:
On sait que le parfait en indo-européen exprimait souvent l´état résultant de l´achèvement ou de la `perfection´ d´une action, donc un état présent : `j´ai vu´ donc `je sais´ (gr. o), `j´ai eu présent à l´esprit´ donc `je me souviens´ (lat. memini). C´est le cas des perfecto-présents du germanique. Mais, dans le système du verbe, ces parfaits à sens de présent étaient isolés. On leur a constitué une conjugaison plus ou moins complète avec un prétérit faible sans voyelle prédésinentielle, mais avec un participe passé fort (Idem). (note: ➳)
Preterite-present verbs thus display both the features of strong verbs (lack of suffix and apophony) and of weak verbs (addition of a dental suffix in the past). To this class of verbs should be added the anomal verb WILLAN. An anomal verb is an athematic verb ending in *-mi, meaning the ending is directly added to the root without the addition of a thematic vowel. In the Indo-European language (and later on in Germanic), the endings for the first person singular in the indicative present were *-mi, as in Greek - `I am´ ; in Gothic, we have i-m and in Old English we have bio-m `I am´ (note: ➳).
The (morphological) structure of these verbs is thus: root + endings (case, number, gender, person), whereas thematic verbs display the following structure: root + thematic vowel + endings.
We shall adopt a different approach since we are considering these verbs as modal verbs as early as the Old English period (our analysis shall be refined in the course of this PhD).
Whatever the language, the theory of language aims at characterizing the languages (states) and the share initial state of the faculty of language. These tasks are the descriptive adequacy and the explanatory adequacy. Universal Grammar (UG) is the theory of the initial state of the language, and all the different grammars are the theories dealing with the states of all the different languages.
The Faculty of Language (FL) is the component of the human brain dealing with language; the initial state of this component is genetically determined and consists of a set of properties (i.e. features) and a small number of parameters with unmarked values. What is called language is then a cognitive system that stores information about sound, meaning and the structural organization of a specific language. A language L provides information to the performance systems, i.e. the “interface levels” (PHON/SEM). L is then the set of expressions EXP containing a phonetic and semantic components: EXP=<PHON, SEM>([10] : 3). PHON represents the instructions for sensorimotor systems, and SEM for systems of thought. Sensorimotor systems need some information under a very specific form: a temporal order, according to a syllabic or prosodic structure, or according to properties and phonetic relations. Systems of thought need information about interpretable units and the relations between argument structure and scope properties. These relations are tables of semantic features, event or quantification structures, ...
Remember that a language is a set of different expressions, i.e. L is a computational system where every expression is made of one or several lexical items. A certain number of (phonological, morphological, semantic and syntactic) features corresponds to a lexical item; they can be interpretable (i.e. with a semantic content) or uninterpretable. The computation of an expression EXP converges at the interface PHON or SEM, is EXP is legible at SEM or PHON. In other words, EXP is made of interpretable elements which are arranged and can be used by the external systems at the interface level. If an expression EXP does not satisfy these conditions, the computation crashes at the interface level.
To generate expressions EXP, Universal Grammar makes available a set {F} of features (linguistic properties) and operations CHL (the computational procedure for human language) that access F and generate expressions ([10]: 12). Then acquiring a language involves the selection of features {F}, the construction of lexical items LEX: each derivation D <PHON, SEM> selects elements from LEX accessible to D. A language L then combines {F} and [F] (to which fixed parameters should be added) to obtain EXP; as for features, they are introduced in the course of the computation ([10]: 13).
The operations of CHL are Merge – let α and β two syntactic objects; α and β merge to form another syntactic object K: K=(α, β); Agree – it establishes a relation (agreement, case-checking) between a lexical item α and a feature F in the domain of F; and Move – it adds up Merge and Agree: there is agreement between α and F, then Merge of P(F) (i.e. the phase determined by F where P is a constituant) to αP (i.e. the projection headed by α.
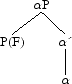
Lexical Array (LA) can then be defined as follows: the faculty of language determines a set {F} of properties (or features) available for all the different languages. Then each language selects one and only one subset [F] of {F} and one and only one assembly of elements of [F] (i.e. its lexicon LEX). LA is then the only selection of elements of LEX to be accessible in a derivation ([8] : 4). We can consequently refine what has just been mentioned. L has three components: narrow syntax which maps LA to a derivation D, a phonological component Φ allowing the derivation D to access PHON and a semantic component Σ which allows D to access SEM (note: ➳). Any mapping will satisfy the inclusiveness condition, introducing no new elements but only rearranging those of the domain. Let us now go back to the lexical items we have just mentioned. They belong to two main categories: substantive and functional categories. For the sake of the analysis to come, we will only be interested in those functional categories which are at the core of language: the core functional categories (CFCs). There are three of them: C expressing force and mood, T expressing tense and event structure, and v the “light verb”, head of transitive constructions. All CFCs can have φ-features (gender, number and person) which are obligatory for T and v. These features are uninterpretable and constitute the core of the system of (structural) Case-agreement and “dislocation” (i.e. Move) ([10] : 15).
The new theoretical framework we shall work within is [10], [11] et [8]. Within this new model, each derivation procedes by phase. We underlined that a phase was a subarray LAi of the main LA. But unlike the Minimalist Program ([9]) and [10], the lexical items are not directly generated fully marked (i.e. with a complete set of features); the features are introduced in the course of the derivation (which highly simplifies the different operations) and numeration does not exist anymore (that is the difference between Minimalism and Distributed Morphology). The three components of a derivation proceed cyclically. Once the derivation is over, it is tranferred to Φ and Σ (through the operation TRANSFER) at the level of narrow syntax. The derivation dealing with Φ is called Spell-Out. Then lexical units are transferred and interpretated by Φ and Σ. There are two types of phases: strong phases and weak phases. The strong phases are potential targets for any move and they can have an EPP feature (a SPEC to host a subject). As for the weak verbs, they do not possess these properties. Out of the three CFCs, only CP and vP are strong phases: they are subarrays LAi (with a C) and LAj (with a v). Both C and v must be selected: C is semantically selected by a substantive category, and C selects T; v is selected by a functional category, and it can select verbal elements, or NPs or DPs (external argument under SPEC-v). A phase has the following representation:
PH=[α [H β]],
where H is the head of the phase (either C or v), α the edge, the limit of the phase (the elements within α can or sometimes must raise), and β the domain of H. Only the edge of the phase will be accessible to any operation, it is the Phase Impenetrability Condition ([8] : 5).
In (2), we have a complete phase. It is then transferred to Φ which will convert it into PHON, for the speaker to spell it out. Yet, at the level of the phase, only β will be spelled out to allow the edge α of PH to move: head-movement, subject-movement to SPEC-T and “escape hatch” for successive-cyclic movements through the edge. It has also been mentioned that an operation of CHL could intervene within the phase, namely Merge α and β to form a new syntactic object K. Within this new model, the operation produces a relation ∈ of membership which results in a notion of iterability (on a theoretical ground, one can merge endlessly), in relations of dominance and c-command, which functions at SEM (the phase is transferred to Σ which is converted in SEM). One has to remember that Merge is the simplest operation to be used before any other, as far as possible.
After Merge, the new syntactic object (i.e. the new unit {α, β}) is considered to be the “projection” of a head from α or β. Before [10], any projection was identified by a new element corresponding to a label. Yet, within the new model, this violates the inclusiveness condition. This new unit will now be identified either by α or β. As a consequence, a label is always a head ([8] : 6). If any operation is driven by labels, then the relation SPEC-head cannot exist anymore; every operation driven by a label LB will keep to its domain, guaranteeing minimal search in accord with the Strongest Minimalist Thesis (SMT). No elements cannot be “legible” by PHON and SEM ([8] : 3). From now on, the head-SPEC relation does not exist at all, it has become a head-head relation. But, per se, that is unimportant. What is important is the way the relation is satisfied: through local c-command (minimal search within its minimal domain ([8] : 12)).
SMT entails that Merge is uncontrained, i.e. Merge is either internal or external. Under external Merge, α and β are two separate objects; under internal Merge, α is part of β, or β is part of α, yielding the property of “displacement”: it is the notion of Move. When there is a displacement from α, the extension condition yields the creation of a new SPEC because displacement can only be done to the edge of α. Unlike external Merge associated to the argument (or base-) structure, internal Merge can apply either before or after Spell-Out. When Merge applies before Spell-Out, it yields overt movement, but covert movement after Spell-Out, and the displaced element is spelled out in-situ. Moreover internal Merge leaves a “copy” in place: K is a copy of L if K and L are identical except that K lacks the phonological features of L. Indeed, an overt or covert movement deals with pairs <α, β> (α an edge element c-commanding β) where either α (covert movement) or β (overt movement) loses its phonological features under Spell-Out ([8] : 8-9).
For the sake of our analysis, whe shall also use Morris Halle and Alec Marantz´s Distributed Morphology [31], [32].
Distributed Morphology can be defined as follows:
It is the separation of the terminal elements involved in the syntax from the phonological realization of these elements.
These phonological realizations are governed by lexical (Vocabulary) entries that relate bundles of morphosyntactic features to bundles of phonological features (Halle & Marantz (1993): 111).
This theory of Distributed Morphology has been introduced to highlight the fact that the machinery of what traditionally has been called morphology (the different functions of the lexicon of the preceding theories are distributed among different components of grammar: the “pure lexicon” (i.e. root + bundles of grammatical features), the vocabulary and the encyclopedia) is not concentrated in a single component of the grammar, but rather, it is distributed among several different components. This theory then predicts that the structure of words is determined by syntax since syntactic operations combine terminal nodes to create words before Vocabulary Insertion. These Vocabulary Items can be underspecified (they do not possess all the morphosyntactic features of a given terminal node). The base unit of morphology within this framework is the morpheme constitued of bundles of syntactic and semantic features:
The order of the morphosyntactic operations is the following:
The terminal nodes that have been mentioned will have a tree structure. They are built up out of bundles of grammatical features, but their phonological features will be provided after Vocabulary Insertion at the Morphological Structure. This morphological level is a level of grammatical representation ruled out by its own principles and properties. This level has three of them:
Late Insertion: the terminal nodes are complexes of syntactic and semantic features, but systematically lack all phonological features. They are supplied by the insertion of Vocabulary Items into the terminal nodes.
Underspecification: for a Vocabulary Item to be inserted in a terminal node, its identifying features must be a subset of features at the terminal node. The Item does not need to match every feature specified in the node. If there is a competition between several Items for a terminal node, the Item to be inserted is the most highly specified, i.e. one whose identifying features are a subset of the terminal node.
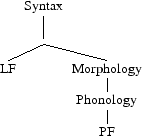
Syntactic Hierarchical Structure All the Way Down: the terminal nodes into which the Vocabulary Items are inserted are organized into hierarchical structures determined by the principles and operations of the syntax, as illustrated by the following structure ([32]: 275-78):
Syntax
↓
Morphology (addition of morphemes, Merger,
Fusion, Fission, Impoverishment)
↓
Vocabulary Insertion
↓
Phonological rules
↓
Spell-Out
Let us recall that in syntax, the terminal elements of a tree are complexes of grammatical features, i.e. semantic and syntactic features. These terminal elements can be moved from a position in the tree (head-to-head movement) and then be adjoined to another position. Syntax supplies hierarchically organized representations; the order is determined by morphology which makes a linearization out of the hierarchical structure and gives them phonological features (i.e. Vocabulary Insertion). We shall represent the lexical Items of Distributed Morphology with trees in the course of our work. Within the morphological component, structurally adjacent nodes can merge, as sister nodes also can into one single node. A given node can undergo two processes: Fission, which will lead to two distinct nodes or Impoverishment. A node can then be modified through the following means:
Merger : it joins two terminal nodes under a category-node of a head (i.e. a “zero-level category”) but the two nodes are still independent. When inserted, there are two lexical Items under the head, one for each terminal node which has been merged. More generally, Merger merges a head of its complement XP.
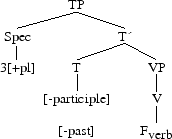
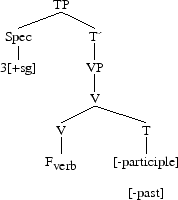
In contemporary English, Tense on the verb is an example of Merger. Let us take “they sleep”: Tense lowers to the verb and we could have the following tree:
The first step is,
then after Merger, we have,
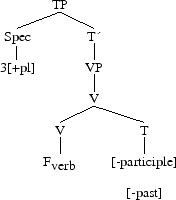
V and T remains as two distinct morphemes which have merged under a single node. Then Vocabulary Insertion takes place.
Fusion: takes two terminal nodes that are sisters under a single category-node and fuses them into a simple node. When inserted, the Vocabulary Item must have a subset of morphosyntactic features of the fused node, including the features from both input terminal nodes ([31]: 116).
Tense and Agreement in contemporary English is an example of Fusion. Let us take “he sleeps”: the third person singular ending -s adjoins to the verb. We first have Merger where Tense lowers to the verb,
then, we have Fusion of Tense and Agreement,
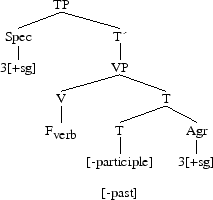
Fission : during Vocabulary Insertion, it creates additional morphemes via splitting off of features that are not the features of the fisioning Vocabulary Item.
Let us take the example of Biblical Hebrew from ((27) ((27))). This language has two patterns of verbal inflection: the Perfect conjugation, which uses suffixation, and the Imperfect conjugation, which uses both prefixation and suffixation. This is illustrated with the verb “throw” /zrq/:
| Perfect | Sg | Pl | Imperfect | Sg | Pl | ||
| 1 | zaːraq-ti | zaːraq-nuː | 1 | ʔe-zroq | ni-zroq | ||
| 2m | zaːraq-ta | zEraq-tem | 2m | ti-zroq | ti-zrEq-uː | ||
| 2f | zaːraq-t | zEraq-ten | 2f | ti-zrEq-iː | ti-zroq-naː | ||
| 3m | zaːraq | zaːrq-uː | 3m | yi-zroq | yi-zrEq-uː | ||
| 3f | zaːraq-a | zaːrq-uː | 3f | ti-zroq | ti-zroq-naː |
In Hebrew, Tense and Agreement are fused into a single morpheme. The Hebrew Perfect is not subject to Fision. Yet, it is different in the Hebrew Imperfect since Vocabulary Insertion is subject to Fission because, as the table shows, the affixes are either prefixes or suffixes. Let us first give the features of the different affixes (i.e. morphemes) from the less to the most specified (“Auth” stands for Author (of the language act) and “PSE” for Participant to the Speech Act):
| /naː/ ⟷ [-Auth,+fem,+pl] | (suffix) |
| /n/ ⟷ [+Auth,+pl] | (prefix) |
| /uː/ ⟷ [-Auth,+pl] | (suffix) |
| /y/ ⟷ [-PSE,-fem] | (prefix) |
| /ʔ/ ⟷ [+Auth] | (prefix) |
| /t/ ⟷ elsewhere (defaul valuet) | (prefix) |
Let us now take the form “yi-zrEq-uː” (3rd person plural masculine). The morpheme 3pl masc has the features [-PSE,-Auth,-fem,+pl]. The first Item to be chosen is /uː/ [-Auth,+pl]. The insertion of this item copies the unmatched features onto the subsidiary morpheme. The prefix /y/ [-PSE,-fem] is then inserted , and since only one iteration of Fission is admitted, the derivation comes to an end. We the have: yi-zrEq-uː [-PSE,-Auth,-fem,+pl] → [-PSE,-fem]+[/uː/;-Auth,+pl] → [/y/;-PSE,-fem]+[/uː/;-Auth,+pl].
a node is impoverished when one (or more) feature is deleted (stil from (27) (27)).
| am | ⟷ +[+Auth,-pl,+pres,+finite] | 1sg pres |
| i-<z> | ⟷ +[-pl,+pres,+finite] | 3sg pres |
| was | ⟷ +[-pl,+finite] | 1/3sg Pret |
| are | ⟷ +[+pres,+finite] | pres elsewhere |
| were | ⟷ +[+finite] | past elsewhere |
| be | ⟷ | elsewhere |
Then, let us have a look on how lexical Items are inserted into the morphemes:
[Cop(ule),+vb]+[+PSE,+Auth,-pl,+pres,+finite] (1sg pres)
| am: | +[+Auth,-pl,+pres,+finite] |
[Cop(ule),+vb]+[+PSE,+Auth,+pl,-pre,+finite] (1pl past)
| were: | +[+finite] |
* [Cop(ule),+vb]+[+PSE,-Auth,-pl,-pres,+finite] (2sg past)
| *was: | +[-pl,+finite] |
* [Cop(ule),+vb]+[+PSE,-Auth,-pl,+pres,+finite] (2sg pres)
| *i<z>: | +[-pl,+pres,+finite] |
The Impoverishment rule deals here with 2nd persons singular and plural: the feature [-pl] is deleted (≠ “thou knowst” in Early Modern English)). Then for c. and d., we have,
[Cop(ule),+vb]+[+PSE,-Auth, ,-pres,+finite]
[Cop(ule),+vb]+[+PSE,-Auth, ,+pres,+finite]
After the morphological level, let us focus on Vocabulary Insertion. As we briefly explained, an Item cannot be inserted anywhere: with the Distributed Morphology theory, there is a competition between lexical items. To insert an item into a given node, the lexical entries are ordered: from the most specified (i.e. the subset of morphological features matches the node it must be inserted into) to the less specified.
In the syntax, the bundles of morphosyntactic features do not come from the lexicon but from the Vocabulary of Distributed Morphology (the atomic roots of a language plus the bundles of grammatical features). Moreover, the phonological features are not part of these bundles, they are realized after Vocabulary Insertion. This is why the Vocabulary is searched to find the Vocabulary Item which matches the semantic and morphosyntactic features of all the different terminal nodes that exist.
Grammatical Items thus compete so that the best element is chosen and inserted. There are two types of competition:
Context-free Insertion: we find the Vocabulary entries whose category is compatible with the category of the terminal element being phonologically realized and whose features are compatible with the set of morphological features that the syntax and morphology have generated on this terminal element.
Context-dependent Insertion: Halle & Marantz calls it Conditioned Allomorphy. It involves a choice among alternative Vocabulary Items that differ in their stated insertion contexts and phonological features. The choice among competing allomorphs is determined by precedence to the allomorph appearing in the most complex, most highly specified context over allomorphs appearing in less complex contexts ([31]: 120-23) .
If we now link Distributed Morphology to the Minimalist framework, [43]´s reading focuses on two types of morphemes: functional morphemes and root-mophemes. The characteristic of the functional morphemes is that its features totally determine its meaning (they can serve as contexts for the specific meaning of root-morphemes, but they cannot bear specific meanings in themselves). Then, for these functional morphemes, lexical Items are purely paradigmatic, i.e. they must display a blocking behaviour towards some other morphemes (“hit-∅” blocks "*hit-t-ed"), and they must have the possibility to access phonological forms. As for the root-morphemes, they are identified with their phonological forms and meaning which are closely linked. They can have numerous meanings contextually determined, but only one phonological form. Moreover, they can belong to semantic classes and have specific meanings in specific environments. Then , for these morphemes, the lexical Items are not paradigmatic and they have only one phonological form.
The structure of grammar is then, according to Distributed Morphology and the Minimalist Program:
Universal Grammar provides a universal bundle of “properties”, or features.
A language chooses a subset of features to use in its grammar.
That same language then chooses a subset of this subset for syntax computational system and decides the way to gather the chosen features into the terminal nodes of syntax.
Finally, these morphemes only have relevant features for the computational system (i.e. morphosyntactic features), and have neither phonological features nor morphophonological ones. In other words, before Vocabulary Insertion, the morphological component brackets the structure formed by syntax again.
The use of Distrubuted Morphology in our work will allow us to better understand how clitcs are treated (specially n´t, ´ll, ´ld, ´d in Early Modern English), or to explain (to a certain extent) the loss of V to T (to C) movement.
The accomplishment of this PhD would not have been possible without some important tools: annotated electronic corpora (two for Old English, one for Middle English and one for Early Middle English.
The Old English corpora are The York-Helsinki Parsed Corpus of Old English Poetry ((52) ((52))) and The York-Toronto-Helsinki Parsed Corpus of Old English Prose ((67) ((67))), for a total of 1,500,000 words; the Middle English corpus (prose and poetry) is The Penn-Helsinki Parsed Corpus of Middle English, second edition ((37) (37)), for a total of 1,300,000 words and the Early Middle English corpus (both prose and poetry) is The Penn-Helsinki Parsed Corpus of Early Modern English ((36), for a total of 1,800,000 words. Every corpus is annotated which makes the research quick and easy. And to use these corpora as best as one should, the software CorpusSearch ([57]) has been used.
As far as the translations are concerned, they are ours, except when mentioned.
Finally, the text editor LaTeX (voir [60] et [22]) was used to write this PhD.
To analyze the syntactic evolution of modal verbs, we put forward three main hypotheses:
As early as the Old English period, a syntactic position for preterite-present verbs exists which is different from the one for strong and weak verbs.
Epistemic modals exist in Old English; then we assume two syntactic positions for modals: one for root modals and one for epistemic modals.
As early as Old English, epistemic and root modals are raising verbs
This PhD is to be read as a history of the English language: as an introduction, the theoretical frameworks have been outlined (Chomsky´s new hypotheses, the phases, and Halle and Marantz´s Distributed Morphology.
The first chapter introduces the reader to the syntax of Old English as known in the literature, and to the preterite-present verbs. This chapter then moves on to the approach we are assuming concerning modal verbs: we highlight what their semantic, morphological, phonological and syntactic charateristics are, as opposed to the other types of verbs.
The second chapter is about Middle English and follows the same pattern as the first one: we deal with the syntax of preterite-present verbs, still in opposition to the other types of verbs, but we mainly focus on the grammaticalisation of these verbs (in parallel with the TO particle or with the loss of subjunctive endings).
The last chapter, about Early Modern English, goes deeper into the analysis usually done about modal verbs and sheds new light on a Distributed Morphology viewpoint.
In the appendices, the reader shall find additional information about OE and ME morphological forms of the preterite-present verbs, but also the anaylsis of a specific modal: AGAN (= OUGHT (TO)).