


Par historique, nous entendons seulement faire le point sur ce que représentent les perfecto-présents dans la littérature, tant en diachronie qu´en synchronie.
Nous parlons d´ancêtres des modaux car beaucoup d´entres eux sont devenus des verbes modaux en anglais contemporain. Selon les différents auteurs ou grammairiens, le statut des perfecto-présents reste le même. Nous allons faire un bref récapitulatif de ce qui a été écrit ; nous commençons par des auteurs français, puis anglo-saxons.
Fernand Mossé dit des perfecto-présents que « ce sont des verbes mixtes à alternances vocaliques qui rentrent presque tous dans les classes connues de verbes forts » (Mossé (1945) : 118). André Tellier avait décidé
(...) d´entreprendre cette étude sémantique et syntaxique en prenant [les perfecto-présents] non comme des vocables isolés mais comme les éléments d´un ensemble (...) (Tellier (1962) : 10).
Alistair Campbell, dans sa grammaire du vieil-anglais, ajoute, en parlant des différentes classes de verbes :
There is also a class of verbs known as the preterite-présent verbs : they are not numerous, but most of them are very common (Campbell (1959) : 295, §726) (note: ➳).
Ensuite, Cynthia Allen considère qu´une classe, et catégorie, pour les verbes modaux n´a pas lieu d´être
There is no justification for including the category ``modal´´ in the grammar of Old English unless it can be demonstrated that modal verbs behave differently from other verbs (Allen (1975) : 92) (note: ➳).
Ian Roberts fait le parallèle entre le vieil-anglais, le moyen-anglais et l´anglais contemporain :
(...) modals were formerly much closer in distribution to main verbs than they are in present-day English.
(...) we assume that at least some of the premodals [les perfecto-présents] were θ-assigning verbs base-generated in V. Since we have no evidence that a given premodal was not base-generated in V, we extend this account to all premodals. So we treat the ME [and OE (note: ➳)] premodals as a class as main verbs with sentential complements (...) ([59] : 310-3) (note: ➳).
Enfin Anthony Warner conclut :
In OE, all [the preterite-presents] shared major properties with the rest of the class of verbs, and were clearly to be identified as members of this class ([72] : 97) (note: ➳).
(...) the ancestors of today´s modals and other auxiliaries share a range of properties with verbs throughout Old and Middle English. And though some of these properties (like the possession of a distinct subjunctive inflection) weaken, other develop. Thus, there is evidence that these words continue to be rather closely related to verbs even in late ME (Idem : 102) (note: ➳).
De toutes les citations que nous venons de mentionner, il faut retenir que, jusqu´à présent, les perfecto-présents ont toujours été considérés comme étant des verbes, tout comme les verbes forts et faibles (note: ➳).
Avant d´aller plus loin, donnons la définition des perfecto-présents de [45] : 118.
On appelle verbes perfecto-présents un certain nombre de verbes qui ont la forme d´un parfait indo-européen et la valeur sémantique d´un présent.
Il ajoute :
On sait que le parfait en indo-européen exprimait souvent l´état résultant de l´achèvement ou de la `perfection´ d´une action, donc un état présent : `j´ai vu´ donc `je sais´ (gr. o), `j´ai eu présent à l´esprit´ donc `je me souviens´ (lat. memini). C´est le cas des perfecto-présents du germanique. Mais, dans le système du verbe, ces parfaits à sens de présent étaient isolés. On leur a constitué une conjugaison plus ou moins complète avec un prétérit faible sans voyelle prédésinentielle, mais avec un participe passé fort (Idem).
Les perfecto-présents présentent donc des traits des verbes forts – absence de suffixe pour les formes prétérites et opposition de la voyelle radicale entre le présent et le passé – et des verbes faibles – ajout d´un suffixe dental au prétérit. A cette classe de verbes, nous pouvons ajouter le verbe anomal WILLAN. Un verbe anomal est un verbe athématique en *-mi, c´est-à-dire que la désinence est directement ajoutée à la racine, sans l´ajout d´une voyelle thématique. En indo-européen, et plus tard en germanique, les terminaisons de la première personne du singulier du présent de l´indicatif étaient *-mi, comme le grec - `je suis´ ; en gotique, nous avons i-m et en vieil-anglais bio-m `je suis´ (note: ➳). La structure de ces verbes est donc : racine + terminaisons (cas, nombre, genre, personne), alors que les verbes thématiques présentent la structure : racine + voyelle thématique + terminaisons.
L´approche que nous avons de ces verbes va être différente, car nous les considérons comme des verbes modaux, et ce dès la période vieil-anglaise (nous affinerons notre analyse plus loin dans la thèse).
La théorie du langage, quel que soit ce langage, a pour but de caractériser les états des langues et un état initial de la faculté du langage : ce sont les tâches de l´adéquation descriptive (descriptive adequacy) et de l´adéquation explicative (explanatory adequacy). La grammaire universelle (GU) est la théorie de l´état initial du langage, et les différentes grammaires sont les théories concernant les états des différentes langues. La faculté de langage (Faculty of Language) est la composante du cerveau humain qui traite le langage (l´état initial de cette composante est déterminé génétiquement et consiste en un ensemble de propriétés (traits), et en un petit nombre de paramètres aux valeurs non marquées). Ce que l´on appelle langage est le système cognitif qui engrange les informations concernant les sons, le sens et l´organisation structurale d´une langue particulière. Une langue L fournit des informations aux systèmes de performance à travers les niveaux d´interface (PHON/SEM), qui ne sont pas les systèmes externes (conceptuel/intentionnel, sensori-moteur). L est l´ensemble des expressions EXP qui chacune contient une composante phonétique et une autre sémantique : EXP=<PHON, SEM> ([10] : 3). PHON représente les instructions destinées aux systèmes sensorimoteurs, quant à SEM, elle représente celles qui le sont aux systèmes de pensée. Les systèmes sensorimoteurs ont besoin de certaines informations présentées sous une forme bien particulière : dans un ordre temporel, selon une structure prosodique et syllabique ou selon certaines propriétés et relations phonétiques. Les systèmes de pensées, quant à eux, nécessitent des informations à propos d´unités qu´ils peuvent interpréter et les relations entre structure argumentale et propriétés scopales : ce sont des tableaux de traits sémantiques, des structures événementielles ou quantificationnelles, ...
Nous avons mentionné qu´une langue était un ensemble de différentes expressions, en d´autres termes, L est un système computationnel où chaque expression est composée d´un ou plusieurs items lexicaux. A chaque item lexical correspond un certain nombre de traits (phonologiques, morphologiques, sémantiques et syntaxiques) ; ceux-ci peuvent être interprétables, c´est-à-dire possédant un contenu sémantique, ou ininterprétables. La computation d´une expression EXP converge au niveau de l´interface (PHON ou SEM) si celle-ci est lisible par SEM ou PHON, c´est-à-dire EXP n´est faite que d´éléments interprétables par les systèmes externes au niveau de l´interface, lesquels éléments sont organisés afin que ces systèmes puissent les utiliser. Si une expression EXP ne satisfait pas à ces conditions, la computation s´effondre au niveau de l´interface.
Pour générer des expressions EXP, la grammaire universelle rend disponible un ensemble {F} de traits – qui sont des propriétés linguistiques –, et des opérations CHL – la procédure computationnelle du langage humain – qui accèdent à F, et génèrent ainsi des expressions ([10] : 12). L´acquisition d´une langue implique donc la sélection de traits {F}, puis la construction d´items lexicaux LEX : chaque dérivation D <PHON,SEM> fait une sélection des éléments de LEX qui sont accessibles par D. Une langue L combine alors {F} – un ensemble de propriétés, ou traits – et [F] – un élément du lexique – (plus des paramètres fixés) pour obtenir EXP, les traits, quant à eux, sont introduits au cours de la computation ([10] : 13).
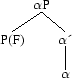
Les opérations de CHL sont la Fusion (Merge) : soient deux objets syntaxiques α et β, α et β vont fusionner pour former un nouvel objet syntaxique K : K=(α, β), l´Accord (Agree) : établissement d´une relation (agreement, case-checking) entre un item lexical α et un trait F dans le domaine de F, et le Mouvement (Move) qui est la somme de la Fusion et de l´Accord : il y a Accord entre α et F, puis Fusion de P(F) (la phase déterminée par F, P est un constituant) à αP (projection qui est dominée par α).
La gamme principale (Lexical Array, LA par la suite) peut être définie ainsi : la faculté de langage détermine un ensemble {F} de propriétés, ou traits, disponible pour les différentes langues. Puis chaque langue fait une, et une seule, sélection d´un sous-ensemble [F] de {F} et un, et un seul, assemblage d´éléments de [F] : c´est son lexique LEX. LA est alors la seule et unique sélection d´éléments de LEX à laquelle aura accès une dérivation ([8] : 4). Dès lors, nous pouvons affiner ce qui a été dit précédemment. L comporte trois composantes : la syntaxe étroite (narrow syntax) qui organise LA pour que la dérivation D y accède, une composante phonologique Φ qui permet à la dérivation D d´accéder à PHON et une composante sémantique Σ qui permet à la dérivation D d´accéder à SEM (note: ➳). Toute organisation mentionnée devra satisfaire à la « condition du tout compris » (inclusiveness condition) : il n´y a pas d´introduction de nouveaux éléments, mais ré-arrangement de ceux qui existent dans le domaine créé. Revenons aux items lexicaux que nous venons de mentionner. Ils appartiennent à deux types de catégories principales : des catégories substantives et des catégories fonctionnelles. Pour notre analyse à venir, seules ces catégories fonctionnelles nous intéressent, ou plus précisément, les catégories fonctionnelles qui sont au cœur de la langue : ce sont les Core Functional Categories (CFC). Il en existe trois : C, le complémenteur, qui exprime la force et la voix, T qui exprime le temps et la structure événementielle et v, le verbe léger qui est la tête des constructions transitives. Toutes ces CFC peuvent avoir des traits ϕ (genre, nombre et personne), mais pour C et v, ces traits sont obligatoires, ininterprétables, ce qui constitue le cœur des systèmes de « dislocation » (c´est-à-dire mouvement Move) et d´accord casuel (structural) ([10] : 15).
Nous nous placerons dans le nouveau cadre théorique énoncé dans [10], [11] et [8]. Dans le nouveau modèle, chaque dérivation procède par phase. Nous avons dit qu´une phase était une sous-gamme LAi de la gamme lexicale principale LA. A la différence du programme minimaliste ([9]) et de [10], les items lexicaux sont générés totalement fléchis, c´est-à-dire avec des traits qui leur sont attachés et la numération n´existe plus (c´est ce qui différencie le Minimalisme de la Morphologie Distribuée) ; de fait, les traits sont introduits au fur et à mesure de la dérivation, ce qui simplifie grandement les différentes opérations. Ces trois composantes d´une dérivation procèdent de façon cyclique. Une fois la dérivation finie, elle est remise à Φ et Σ grâce à l´opération TRANSFER, qui ne s´applique qu´au niveau de la syntaxe étroite de la dérivation D : celle qui concerne Φ est appelée « Epélation » (Spell-Out(note: ➳)). Sont tranférées des unités (lexicales) qui sont interprétées par Φ et Σ. Il existe deux sortes de phases : des phases fortes, lesquelles sont des cibles potentielles pour tout mouvement et qui peuvent avoir un trait EPP (c´est-à-dire une position SPEC pour accueillir un sujet), et des phases faibles qui ne possèdent pas ces propriétés. Des trois catégories fonctionnelles C, T et v, seules CP et vP sont des phases (fortes) : deux sous-gammes LAi et LAj ont été tirées de LA, l´une comportant un C et l´autre comportant un v. Tant C (sauf le C d´une phrase radicale) que v doivent être sélectionnés. C est sémantiquement sélectionné par une catégorie substantive, et il sélectionne T ; v est sélectionné par une catégorie fonctionnelle, et il sélectionne des éléments verbaux ou des NPs et des DPs (qui constituent alors l´argument externe sous SPEC-v). Une phase est représentée de la manière suivante :
PH=[α [H β]],
où H est la tête de la phase (soit C ou v) et α le bord, la limite de la phase (les éléments contenus dans α peuvent, ou doivent, monter), quant à β, c´est le domaine de H. Seule la limite de la phase sera accessible à quelque opération que ce soit : c´est la « condition d´impénétrabilité de la phase » (Phase Impenetrability Condition [8] : 5).
Dans la représentation (2), nous avons une phase complète. Elle est alors transférée à Φ qui la convertira en PHON, pour que le locuteur puisse l´épeler. Cependant, au niveau de la phase, seul β sera épelé pour permettre à la limite α de PH de bouger : mouvement de tête, mouvement du sujet en SPEC-T et « sortie de secours » (escape hatch) pour les mouvements successifs et cycliques qui peuvent passer par la limite de la phase. Nous avons aussi mentionné que dans une phase une opération de CHL pouvait intervenir : la Fusion, α et β fusionnent pour donner un nouvel objet syntaxique K. Cette opération, dans le nouveau modèle, produit une relation ∈ d´appartenance qui induit une notion de réitération (en théorie, on peut fusionner à l´infini), des relations de dominance et de c-commande (qui ne fonctionne qu´à SEM : la phase est transférée à Σ qui est convertie en SEM). Il est à noter que l´opération Fusion est la plus simple et celle à laquelle on requerra, dans la mesure du possible, avant toute autre.
Le nouvel objet syntaxique obtenu après fusion (la nouvelle unité {α, β}) est considéré comme étant la « projection » d´une tête d´α ou de β. Précédemment (c´est-à-dire avant [10]), toute projection était identifiée par un nouvel élément auquel correspondait un label. Cependant, dans le nouveau modèle, ce fait viole la « condition du tout compris » (inclusiveness condition). Cette nouvelle unité {α, β} sera désormais identifiée soit par α, soit par β qui seront leur label. Ainsi, un label est toujours une tête ([8] : 6). Ainsi, si toute opération est motivée par des labels, il ne peut plus y avoir de relation SPEC-tête ; toute opération motivée par un label LB restera dans son domaine, ce qui garantit une recherche minimale, en accord avec la « thèse du minimalisme le plus fort » (Strongest Minimalist Thesis (SMT)) : il ne peut y avoir d´éléments lexicaux qui ne soient « lisibles » par PHON et SEM ([8] : 3). Dès lors, la relation tête-SPEC n´existe plus, cette relation est devenue une relation tête-tête. Mais, en soi, ce n´est guère important ; ce qui importe c´est la manière dont est satifaite cette relation, et elle est satisfaite par la c-commande locale (recherche minimale dans son domaine minimal ([8] : 12)).
SMT implique que l´opération Fusion est sans contrainte, c´est-à-dire que Fusion est soit interne, soit externe. Quand il y a Fusion externe (external Merge) α et β sont deux objets distincts ; pour la Fusion interne (internal Merge), α fait partie de β, ou vice-versa et elle implique la propriété de « déplacement » : c´est la notion de Mouvement. Quand il y a déplacement à partir de l´intérieur d´α, la condition d´extension appelle la création d´un nouveau SPEC car le déplacement ne peut se faire que vers la limite d´α. A la différence de la Fusion externe, qui est associée à la structure argumentale (ou la structure de base), la Fusion interne peut se faire soit avant, soit après l´Epélation. Quand la Fusion se fait avant S-O, cela implique un mouvement visible, quand elle se fait après Spell-Out, le mouvement est invisible, et l´élément déplacé est épelé in-situ. De plus, la Fusion interne laisse une copie une fois l´élément déplacé : on appelle K la copie de L si K et L sont identiques, sauf que K n´a plus les traits phonologiques de L. En effet, un mouvement visible ou invisible concerne des paires <α, β>, α étant l´élément, contenu dans la limite, c-commandant β, dans lesquelles soit α (mouvement invisible) ou soit β (mouvement visible) perd ses traits phonologiques sous Spell-Out ([8] : 8-9).
En plus de l´utilisation des nouvelles hypothèses de travail de Chomsky, nous aurons aussi recours à la Morphologie Distribuée (Distributed Morphology) énoncée par Morris Halle et Alec Marantz dans [31], [32].
La Morphologie Distribuée se définit de la manière suivante :
C´est la séparation d´éléments terminaux, qui sont impliqués dans la syntaxe, de leurs réalisations phonologiques.
Ces réalisations phonologiques sont gouvernées par des entrées lexicales qui mettent en relation des ensembles de traits morphosyntaxiques avec des ensembles de traits phonologiques. ([31] : 111)
Cette théorie de la Morphologie Distribuée a été instaurée pour mettre en lumière le fait que, contrairement à la notion traditionnelle de la morphologie (les fonctions attribuées au lexique dans les théories précédentes sont distribuées entre différentes composantes de la grammaire : le lexique pur, c´est-à-dire la racine d´un mot à laquelle on ajoute des ensembles de traits grammaticaux, le vocabulaire et l´encyclopédie), elle ne se concentre pas sur une seule composante de la grammaire, mais elle se distribue sur plusieurs composantes. Ainsi, cette théorie prédit que la structure des mots est déterminée par la syntaxe car des opérations syntaxiques combinent des nœuds terminaux pour créer des mots, et ce avant l´insertion lexicale (Vocabulary Insertion). Ces items lexicaux (Vocabulary Items) peuvent tout à fait être sous-spécifiés (c´est-à-dire qu´ils ne possèdent pas tous les traits morphosyntaxiques d´un nœud terminal donné). L´unité de base de la morphologie dans la Morphologie Distribuée est le morphème (qui est un faisceau de traits syntaxiques et sémantiques abstraits) :
L´ordre des opérations morphosyntaxiques est le suivant :
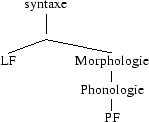
C´est toujours sous forme d´arbres que seront représentés les éléments terminaux dont nous avons précédemment parlés. Ils sont constitués d´ensembles de traits grammaticaux, mais leurs traits phonologiques ne leur seront fournis qu´après insertion lexicale au niveau morphologique (Morphological Structure). Ce niveau morphologique est un niveau de représentation grammaticale régi par ses propres principes et propriétés. Il possède trois propriétés :
L´insertion tardive (Late Insertion) : les nœuds terminaux représentent des complexes de traits sémantiques et syntaxiques, mais où les traits phonologiques manquent systématiquement. Ce manque est comblé lors de l´insertion des items lexicaux.
La sous-spécification (Underspecification) : pour qu´un item lexical soit inséré dans un nœud terminal, les traits qui identifient ce même item doivent être un sous-ensemble de traits que possède le nœud terminal. Il n´est pas besoin qu´il y ait une correspondance parfaite entre les traits de l´item lexical et ceux du nœud terminal. S´il existe une compétition entre plusieurs items pour un seul nœud, l´item qui sera inseré sera celui qui est le plus spécifié, c´est-à-dire, celui dont les traits correspondent le plus aux traits du nœud terminal.
La structure syntaxique hiérarchisée de haut en bas (Syntactic Hierarchical Structure All the Way Down) : les nœuds terminaux où sont insérés les items lexicaux sont organisés sous forme de structures hiérarchiques déterminées par les principes et les opérations qui régissent la syntaxe, comme l´illustre la structure suivante ([32] : 275-78) :
Syntaxe
↓
Morphologie (ajout de morphèmes, Merger,
Fusion, Fission, Impoverishment)
↓
Insertion Lexicale
↓
Règles phonologiques
↓
Spell-Out
Rappelons qu´en syntaxe, les éléments terminaux d´une arborescence sont des complexes de traits grammaticaux, c´est-à-dire des traits sémantiques et syntaxiques. Ces éléments terminaux peuvent être déplacés d´une position (par un mouvement de tête à tête) dans l´arbre et être adjoints à une autre position. En effet, la syntaxe fournit des représentations organisées hiérarchiquement ; l´ordre est déterminé par la morphologie qui linéarise les structures hiérarchiques et qui leur fournit des traits phonologiques (c´est le Vocabulary Insertion). C´est sous cette forme d´arborescence que nous représentons les items lexicaux de la Morphologie Distribuée dans le reste de notre travail. Dans le composant morphologique, des nœuds structuralement contigus peuvent fusionner, tout comme des nœuds terminaux qui sont sœurs peuvent aussi fusionner en un seul et unique nœud. Un nœud donné peut connaître un processus de fission, lequel aboutira à deux nœuds distincts, ou bien, un nœud peut être sujet à un appauvrissement. Ainsi, un nœud peut être modifié par les moyens suivants :
Fusion Partielle (Merger) : ce processus joint deux nœuds terminaux sous un nœud-catégorie (anciennement projection maximale) d´une tête, mais il maintient deux nœuds terminaux indépendants. Lors de l´insertion lexicale, il y a deux items lexicaux sous la tête, un pour chaque nœud terminal qui a été fusionné. De manière générale, la fusion totale joint une tête à la tête de son complément XP.
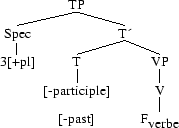
En anglais contemporain, le temps sur le verbe est un exemple de fusion partielle. Prenons « they sleep » : le temps vient se joindre au verbe (lowering), et nous pourrions le représenter ainsi :
Dans un premier temps, nous avons,
puis, une fois la fusion partielle effectuée,
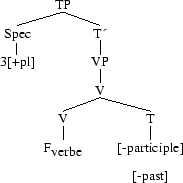
V et T restent deux morphèmes distincts qui ont fusionné sous un seul nœud. Ensuite vient l´insertion lexicale.
Fusion Totale (Fusion) : deux nœuds terminaux qui sont sœurs sous un unique nœud-catégorie fusionnent en un seul nœud. Lors de l´insertion lexicale, l´item lexical inséré doit posséder un sous-ensemble de traits morphosyntaxiques du nœud obtenu, lequel inclut les traits des deux nœuds de départ, avant la fusion totale ([31] : 116).
C´est, par exemple, l´accord et le temps en anglais contemporain. Prenons maintenant ``he sleeps´´ : le -s de la troisième personne du singulier vient s´adjoindre au verbe. Nous avons tout d´abord une fusion partielle : le temps « descend » au verbe,
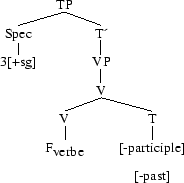
puis, une fusion totale entre le temps et l´accord,
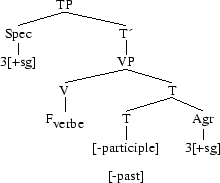
Fission : c´est la création, pendant l´insertion lexicale, de morphèmes supplémentaires par la séparation des traits qui ne sont pas ceux de l´item lexical qui connaît la fission.
Prenons l´exemple de l´hébreu (tiré de Halle 2000). Cette langue possède deux types d´inflections verbales : le perfectif, qui a recours à la suffixation, et l´imperfectif, qui, lui, a recours à la préfixation et à la suffixation. Donnons-en l´illustration avec le verbe « jeter » /zrq/ :
| Perfectif | Sg | Pl | Imperfectif | Sg | Pl | ||
| 1 | zaːraq-ti | zaːraq-nuː | 1 | ʔe-zroq | ni-zroq | ||
| 2m | zaːraq-ta | zEraq-tem | 2m | ti-zroq | ti-zrEq-uː | ||
| 2f | zaːraq-t | zEraq-ten | 2f | ti-zrEq-iː | ti-zroq-naː | ||
| 3m | zaːraq | zaːrq-uː | 3m | yi-zroq | yi-zrEq-uː | ||
| 3f | zaːraq-a | zaːrq-uː | 3f | ti-zroq | ti-zroq-naː |
En hébreu, le temps et l´accord fusionnent en un seul morphème. Le perfectif hébreu n´est pas sujet à la fission. Cependant, pour l´imperfectif, l´insertion lexicale est sujette à la fission car, comme le montre le tableau précédent, les affixes de l´imperfectif sont soit des préfixes, soit des suffixes. Donnons d´abord les traits des différents affixes (i.e. morphèmes) par ordre décroissant, du plus marqué au moins marqué (l´abréviation « Auth » veut dire Author (de l´acte de langage), et « PSE » Participant to the Speech Act) :
| /naː/ ⟷ [-Auth,+fem,+pl] | (suffixe) |
| /n/ ⟷ [+Auth,+pl] | (préfixe) |
| /uː/ ⟷ [-Auth,+pl] | (suffixe) |
| /y/ ⟷ [-PSE,-fem] | (préfixe) |
| /ʔ/ ⟷ [+Auth] | (préfixe) |
| /t/ ⟷ elsewhere (valeur par défaut) | (préfixe) |
Prenons maintenant la forme « yi-zrEq-uː » (3e personne du pluriel masculin). Le morphème 3pl masc a les traits [-PSE,-Auth,-fem,+pl]. Le premier item à choisir est /uː/ [-Auth,+pl]. L´insertion de cet item copie les traits non satisfaits [-PSE,-fem] sur le morphème secondaire. Le préfixe /y/ [-PSE,-fem] est alors inséré, et comme la fission ne peut se produire qu´une seule fois, la dérivation se termine. Ce qui donne : yi-zrEq-uː [-PSE,-Auth,-fem,+pl] → [-PSE,-fem]+[/uː/ ;-Auth,+pl] → [/y/ ;-PSE,-fem]+[/uː/ ;-Auth,+pl].
Appauvrissement (Impoverishment) : un nœud est appauvri lorsqu´il y a effacement d´un (ou de plusieurs) de ses traits.
Prenons la conjugaison de « be » en anglais contemporain (toujours tiré de Halle 2000).
| am | ⟷ +[+Auth,-pl,+pres,+finite] | 1sg pres |
| i-<z> | ⟷ +[-pl,+pres,+finite] | 3sg pres |
| was | ⟷ +[-pl,+finite] | 1/3sg Pret |
| are | ⟷ +[+pres,+finite] | pres elsewhere |
| were | ⟷ +[+finite] | past elsewhere |
| be | ⟷ | elsewhere |
Puis, regardons comment les items lexicaux sont insérés dans les morphèmes :
[Cop(ule),+vb]+[+PSE,+Auth,-pl,+pres,+finite] (1sg pres)
| am : | +[+Auth,-pl,+pres,+finite] |
[Cop(ule),+vb]+[+PSE,+Auth,+pl,-pre,+finite] (1pl past)
| were : | +[+finite] |
* [Cop(ule),+vb]+[+PSE,-Auth,-pl,-pres,+finite] (2sg past)
| *was : | +[-pl,+finite] |
* [Cop(ule),+vb]+[+PSE,-Auth,-pl,+pres,+finite] (2sg pres)
| *i<z> : | +[-pl,+pres,+finite] |
La règle d´appauvrissement concerne ici les 2es personnes du singulier et du pluriel : c´est le trait [-pl] qui est effacé (en anglais contemporain, nous n´avons plus de désinences marquées pour les 2es personnes (≠ « thou knowst » en anglais élisabéthain)). Donc pour c. et d., nous aurons désormais,
[Cop(ule),+vb]+[+PSE,-Auth, ,-pres,+finite]
[Cop(ule),+vb]+[+PSE,-Auth, ,+pres,+finite]
Après le niveau morphologique, intéressons-nous maintenant à l´insertion lexicale. Comme nous l´avons brièvement exposé, n´importe quel item ne peut pas être inséré n´importe où : dans la théorie de la Morphologie Distribuée, il existe une compétition entre les items lexicaux (ou entrées lexicales) pour l´insertion lexicale. Pour l´insertion dans un nœud donné, les entrées lexicales sont ordonnées par le principe suivant : l´entrée la plus spécifiée, c´est-à-dire celle dont le sous-ensemble de traits morphosyntaxiques s´accordent le mieux avec ceux du nœud dans lequel elle doit être insérée, a priorité sur celles qui le sont moins.
Dans la syntaxe, les ensembles de traits morphosyntaxiques ne viennent pas du lexique, mais du « lexique pur » de la Morphologie Distribuée (les racines atomiques d´une langue plus les faisceaux de traits grammaticaux), et les traits phonologiques ne font pas partie de ces ensembles, ils ne seront réalisés qu´après l´insertion lexicale. C´est pour cette raison que, lors de l´insertion lexicale, une recherche est faite dans le lexique afin de trouver l´item lexical qui s´accorde le mieux avec les traits morphosyntaxiques et sémantiques des différents nœuds terminaux qui existent.
C´est pour cette raison que les items grammaticaux sont en compétition, afin que le meilleur élément soit choisi et inséré. Il existe deux types de compétition :
Insertion contextuellement libre (Context-free Insertion) : nous trouvons des entrées lexicales dont la catégorie (grammaticale) est compatible avec celle de l´élément terminal qui est réalisé phonologiquement et dont les traits sont compatibles avec l´ensemble des traits morphosyntaxiques que la syntaxe et la morphologie ont générés pour cet élément terminal.
Insertion contextuellement dépendante (Context-dependent Insertion) : Halle et Marantz l´appelle aussi l´allomorphie conditionnée (Conditioned Allomorphy). Cette insertion implique un choix parmi plusieurs items lexicaux qui diffèrent par leurs traits phonologiques et par le contexte dans lequel ils sont normalement insérés. Dans ce cas-là, les allomorphes (comme les allomorphes du passé) qui apparaissent dans les contextes les plus complexes et les plus spécifiés ont priorité sur les autres ([31] : 120-23).
Si l´on relie maintenant la Morphologie Distribuée au cadre minimaliste, la lecture de [43] met en relief deux types de morphèmes : les morphèmes fonctionnels et les morphèmes-racine. Les morphèmes fonctionnels se caractérisent par le fait que les traits déterminent complètement leur sens (ils peuvent servir de contextes pour les significations spéciales des morphèmes-racine, mais ils ne peuvent pas eux-mêmes porter de sens particuliers). Ainsi, pour ces morphèmes fonctionnels, les items lexicaux sont purement paradigmatiques, c´est-à-dire qu´ils doivent faire preuve d´un comportement de « blocage » (`blocking´ behaviour) vis-à-vis de certains autres morphèmes (`hit-∅´ bloque `*hit-t-ed´) et de la possibilité d´accéder à des formes phonologiques. Les morphèmes-racine, quant à eux, sont identifiés par leurs formes phonologiques et leurs sens qui sont intimement liés. Ils peuvent avoir de nombreux sens qui sont déterminés contextuellement, mais une seule forme phonologique. De plus, ils peuvent appartenir à des classes sémantiques et posséder des sens particuliers dans des environnements précis. De fait, pour ces morphèmes, les items lexicaux ne sont pas paradigmatiques et n´ont qu´une forme phonologique.
Ainsi, la structure de la grammaire, à la lumière de la Morphologie Distribuée et du programme minimaliste, est la suivante :
La grammaire universelle fournit un ensemble universel de « propriétés », ou traits.
Une langue choisit un sous-ensemble de ces traits qu´elle utilise dans sa grammaire.
Cette même langue choisit ensuite un sous-ensemble de ce sous-ensemble pour le système computationnel de la syntaxe et décide de la manière de rassembler les traits choisis dans les nœuds terminaux de la syntaxe.
Enfin, ces morphèmes ne contiennent que les traits pertinents au système computationnel de la syntaxe (les traits morphosyntaxiques), et donc ne contiennent ni les traits phonologiques, ni ceux purement morphologiques (qui sont insérés dans la morphophonologie). En d´autres termes, avant l´insertion lexicale, le composant morphologique reparenthèse les structures formées par la syntaxe.
L´utilisation de la Morphologie Distribuée dans notre travail va nous permettre de mieux comprendre le traitement des clitiques (notamment n´t, ´ll, ´ld, ´d en anglais élisabéthain), ou d´expliquer en partie la perte du mouvement de V à T (à C) des verbes.
Les différentes recherches exécutées pour l´accomplissement de cette thèse n´auraient été possibles sans quatre outils importants : un corpus de vieil-anglais, un corpus de moyen-anglais, un corpus d´anglais élisabéthain et un logiciel de recherche pour exploiter ces corpus électroniques. Le corpus VA est The York-Helsinki Parsed Corpus of Old English Poetry (Pintzuk, Leendert (2001)) The York-Toronto-Helsinki Parsed Corpus of Old English Prose (Taylor, Warner, Pintzuk, Beths (2003)), lequel rassemble des textes en prose et vers et comporte un million cinq cent mille mots ; le corpus pour le MA est The Penn-Helsinki Parsed Corpus of Middle English, second edition (Kroch, Taylor 2000), lequel rassemble aussi des textes en prose et vers et qui comporte un million trois cent mille mots, ainsi que The Penn-Helsinki Parsed Corpus of Early Modern English (Kroch, Santorini, Delfs 2004) qui lui comporte un million huit cent mille mots. Ces trois corpus ont la particularité d´être annotés entièrement, ce qui rend bien évidemment les recherches plus faciles. Pour exploiter au mieux ces corpus, et pour rendre plus agréables les recherches, le logiciel CorpusSearch ([57]) a été utilisé, ce qui fut un gain de temps considérable.
Concernant les traductions des exemples cités, ce sont les nôtres, excepté lorsque c´est indiqué.
La rédaction de cette thèse s´est faite avec l´éditeur de texte LaTeX (voir [60] et [22]).
Pour traiter de l´évolution des verbes modaux, nous émettons trois hypothèses principales de travail (d´où découlent d´autres constatations) :
Dès le vieil-anglais, une position syntaxique existe pour les perfecto-présents, différente de celle des verbes forts et faibles.
Les modaux dits épistémiques sont présents en vieil-anglais ; ainsi, il y aurait deux positions distinctes pour les modaux : une position pour les modaux déontiques et une autre pour les modaux épistémiques.
Dès le vieil-anglais, les modaux épistémiques et déontiques sont des verbes de montée.
Le plan que nous suivons se lit comme une histoire de la langue anglaise : dans l´introduction ont été présentés les cadres théoriques dans lesquels nous allons travailler : les nouvelles hypothèses de travail de Chomsky, ainsi que la Morphologie Distribuée énoncée par Halle et Marantz.
Le premier chapitre expose d´abord une introduction à la syntaxe du vieil-anglais telle qu´elle est connue dans la littérature, ainsi qu´une présentation des verbes perfecto-présents. Ce chapitre aborde ensuite l´approche que nous adoptons concernant ce que nous nommons les verbes modaux. Nous montrons leurs caractéristiques sémantiques, morphologiques, phonologiques et syntaxiques, en opposition avec les autres types de verbes.
Dans le second chapitre, traitant du moyen-anglais, le déroulement est sensiblement le même : nous traitons de leur syntaxe (toujours en opposition avec celle des autres verbes), mais l´accent est mis sur la grammaticalisation des verbes perfecto-présents (en parallèle avec la particule TO ou la perte de la désinence pour les formes subjonctives, par exemple).
Le dernier chapitre, qui porte sur l´anglais élisabéthain, appronfondit l´analyse qui est généralement faite des verbes modaux et apporte de nouveaux éclairages d´un point de vue de la Morphologie Distribuée.
Dans les annexes, le lecteur va trouver des compléments d´information sur les formes morphologiques vieil et moyen-anglaises des perfecto-présents (ainsi que sur leur évolution sémantique), mais aussi l´analyse d´un perfecto-présent particulier : AGAN (= OUGHT (TO)).