
Overview
XML is well suited for the storage of any kind of structured information but there is a lack of standard implementation allowing input/output of data.
Concerning the visualization, an interesting way to proceed is to transform XML documents in formats which can be handled by rendering agents. A very good candidate of such a format is HTML whose syntax is understood by a large set of web browsers. In addition, by using a transformation language like XSLT, it is very easy to transform a XML document into a HTML one.
However, there exists another option which constitutes the answer to the following question. Instead of generating a document which need to be consequently interpreted by an application, why don't generate directly a set of software components capable of displaying themselves specific kind of data. The visualization of a table may then be delegated to a component specialized in the handling of data structured into rows and columns, a portion of a text may be displayed by another specialized component having text layout facilities, etc.
The target software components can be of several different types, available on different platforms and written in different languages. In our project, we chose to generate widely deployed Java Beans components based on the platform independent language Java. This allows users either to develop their own dedicated components or to download ready to use ones. Finding an existing component which fulfill their needs is not a difficult task, considering the number of Java Beans available on the market, ranking from standard graphical swing components to very complex objects like graph renderers, text editors or even spreadsheets.
We said above that we generate Java Beans components. This affirmation is incomplete. We don't directly generate java bytecode but a persistent format for Java Beans components expressed in XML. We use the terms Beans Markup document (or BMdocument in short ) to name such a serialization. The syntax used is very close to the one developed by IBM and known with the acronym BML (Bean Markup Language).
The Ketuk environment includes:
- a XSLT processor which perform the conversion of a XML source document into a BMdocument representation according to the transformation rules expressed in a XSLT script,
- a BMProcessor, responsible for the generation of the Java Beans components described in the BMdocument,
- a XBMapper (XML to Beans Mapper) which reacts to events fired by Java Beans and reflects the potential modification made into the source XML document.
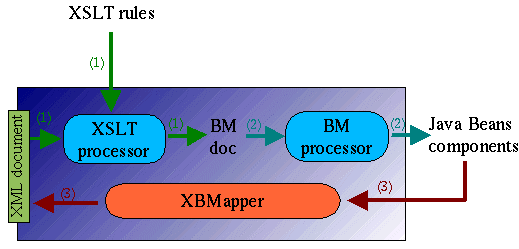
Given a XML document, one has simply to write a XSLT specification and eventually the code of specialized Java Beans to use Ketuk. As highlighted in the sample sales, the XSLT rules are very similar than to ones used to construct a HTML document. In addition, the syntax used to describe BMdocument is very simple and understandable (see the BM document syntax basis section).

Created by Claude Pasquier