|
AxIS Software
From its creation, AxIS has developed several softwares validated experimentally on various applications (in Java, C++ or/and Perl):
Data Preprocessing
- AWLH (AxIS Web Log House) for preprocessing Web logss
- the SOM library (in C++)
Data Mining and Web Usage Mining
- AxISLogMiner Preprocessing and Sequential Pattern Extraction with low support (C&D and D&D)
- SMDS, SCDS and ICDS, three clustering softwares for mining sequential patterns in data
streams
- Cluster&Divide and Divide&Cluster, two methods for extracting Sequential Patterns with
Low Support from Web logs from AxisLogMiner
- ATWUEDA (Axis Tool for Web Usage Evolving Data Analysis)
- Clustering and Classification Toolbox (intranet access On-line Tools )
- The SODAS 2 software
Building Recommender Systems (Java)
- CBR*Tools, an Object-Oriented Software Library for Case-Based Reasoning
- Broadway*Tools: a library based on CBR*Tools and on our recommendation computation approach called the "Broawday approach". Broadway*tools supports the designer in developping Broadway-based systems for supporting information
retrieval on the web or inside a Web site.,
Other software
- K-MADe, Kernel of Model for Activity Description environment
- CLF for generating efficient parsers
- Bibadmin for the management of a collection of
publications
AWLH is issued from AxISlogminer preprocessing software which implements the mult-site log preprocessing
methodology developed by D. Tanasa in his thesis for Web Usage Mining (WUM). In the context of
the Eiffel project (2008-2009), we isolated and redesigned the core of AxISlogMiner preprocessing tool (we
called it AWLH) composed of a set of tools for pre-processing web log files. AWLH can extract and structure
log files from severalWeb servers using different input format. The web log files are cleaned as usually before
to be used by data mining methods, as they contain many noisy entries (for example, robots bring a lot of noise
in the analysis of user behaviour then it is important in this case to identify robot requests). The data are stored
within a database whose model has been improved.
Now the current version of our Web log processing offers:
Processing of several log files from several servers
Support of several input formats (CLF, ECLF, IIS, custom, ...)
Incremental pre-processing
Java API to help integration of AWLH in external application
For recording the click actions by a user in a real time, we developed in 2009 a tool based on an open source
project called "OpenSymphony ClickStream" for capturing Web user actions. For capturing and structuring
data issued from annotated documents inside discussion forums, an extended version of AWLH has been
developed.
Publications : TASANA 2004 thesis
- AxISLogMiner
A Software Tool for Preprocessing and Mining Data for Intersites Web Usage Mining
|
AxISLogMiner is a software application (written in Java) that
implements our preprocessing methodology for Web Usage Mining and two methods for extractiong sequential patterns with low support (cf. Tanasa's thesis in 2005).
The application uses Perl modules for the operations carried on the log file such as: log files join, log cleaning, robot requests filtering and session/visit/episode identification. To
store the preprocessed log file in our relational model, we used JDBC with Java. Since
Tanasa'thesis, we extensed this software with the ability of recording the keywords em-
ployed by users in search engines to find the browsed pages. Now we are in the process of
integrating different codes developed for some specific research or contractual works inside
AxIslogMiner and improve the modularity of the code.
Publications : Tanasa's thesis
As a result of Marascu's thesis (2007-2009), a collection of softwares have been developed for knowledge
discovery and security in data streams (cf. our 2009 annual report for more details on WOD, the outlier
detection method and GEAR an implementation of the history management strategy).
Three clustering methods for mining sequential patterns (Java) in data streams have been developped in
Java by A. Marascu during her thesis [91]. The softwares take batches of data in the format "Client-Date-
Item" and provide clusters of sequences and their centroids in the form of an approximate sequential pattern
calculated with an alignment technique.
SMDS compares the sequences to each others with a complexity of O(n2).
SCDS is an improvement of SMDS, where the complexity is enhanced from O(n2) to O(n:m) with
n the number of navigations and m the number of clusters.
ICDS is a modification of SCDS. The principle is to keep the clusters' centroids from one batch to
another..
This year, the Java code of SMDS has been integrated in the MIDAS demonstrator [68].(cf. 7.2.2) and a C++
version [61] has been implemented for the CRE contract with Orange Labs with a visualisation module (in
Java) . SMDS has been applied on data issued from mobile Orange portal.
Publications : Marascu 2009 Ph. D. thesis
Two methods for extracting sequential patterns with low support have been developed by D. Tanasa in his thesis
in collaboration with F. Masseglia and B. Trousse : Cluster&Divide and Divide&Discover,
.
See Chapter 3 of Tanasa's PhD document for more details on these two methods and on a framework for
developing methods for extracting sequential patterns with low support.
Publications : TASANA 2005 thesis
ATWUEDA for Web Usage Evolving Data Analysis was developed by A. Da Silva in her thesis . It
is available at INRIA's gforce website: http://gforge.inria.fr/projects/atwueda/. A. Da Silva presented part of
her work in a working research group at CNAM-Paris.
This tool was developed in Java and uses the JRI library in order to allow the application of R functions
in the Java environment. R is a programming language and software environment for statistical computing
(http://www.r-project.org/. The ATWUEDA tools is able to read data from a cross table in a MySQL database,
split the data according to the user specifications (in logical or temporal windows) and then apply the approach
proposed in the Da Silva's thesis in order to detect changes in dynamic environment. The proposed approach
characterizes the changes undergone by the usage groups (e.g. appearance, disappearance, fusion and split)
at each timestamp. Graphics are generated for each analysed window, exhibiting statistics that characterizes
changing points over time.
Publications : DA SILVA 2009 thesis
- CBR*Tools
An Object-Oriented Software Library for Case-Based Reasoning
|
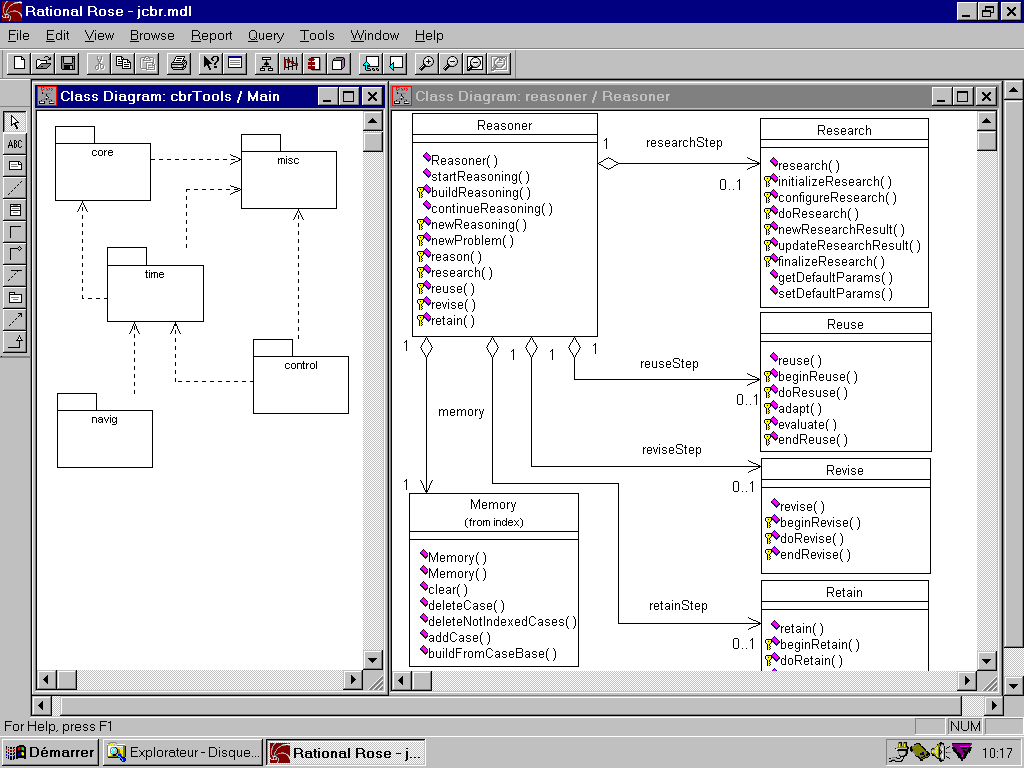
CBR*Tools is an object-oriented software library for Case-Based Reasoning (CBR).
It provides a basic reusable CBR framework that supports the development of CBR applications.
It can be especially used for problems addressing behavorial situation retrieval and indexation.
CBR*Tools consists of three packages, namely, the core, time, and
navigation package.
The library is specified with the UMT notation (Rose Rational) and written in Java. Click on the
icon (on the right hand side), to get a full image of the system's main user interface.
For a short description (only in french)
For a more complete description (french, english)
Publications : INRIA report 1997, CIKM97, ..., PH-D Thesis 1998 (in french)
,
Different applications using the CBR*Tools library are currently under construction in order to support:
- Plant nutrition control in collaboration with INRA Sophia-Antipolis.
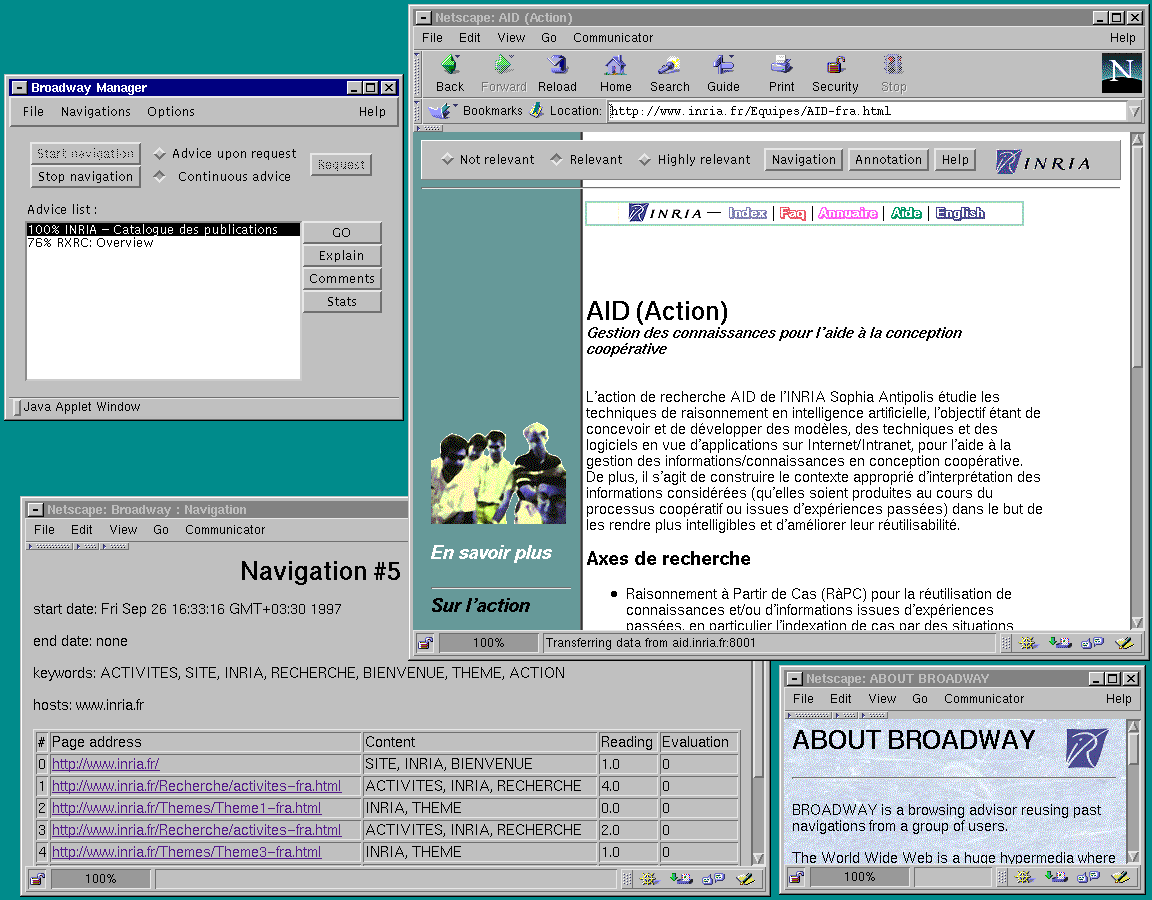
- Navigation on internet : BROADWAY-Web (ex Broawday-V1) is a case-based system
for supporting navigation on internet which is based on the http server called
Jigsaw (W3C) (written in Java) and the CBR*Tools library. The first version
of BROADWAY-Web will be avalaible soon.
- Argumentation in collective decision making
(see ICCBR'97 on HERMES)
- Query reformulation in the context of a meta search
engine in collaborationn with XRCE : BeCBKB
- e-behaviour project (2001-2003) (INRIA & UNSA): supporting navigation inside INRIA RA clone site (2001). Reuse of past visual and non visual behaviours. Visual data are issued from a eye tracking system.
- Others applications for supporting Navigation inside a
Web site (BROADWAY-PREDICT) )
Some information about our first Broadway-based application : Broadway-Web
Broadway-Web is a WWW browsing advisor reusing past navigations from a group of users : it follows a gorup of users during their navigations on the WWW (proxy-based architecture) and advise them by displaying a list of potentially relevant
documents to visit next. Click on the
icon (on the right hand side), to get a full image of the system's main user interface. Broadway uses case-based reasoning to reuse precise experiences derived from past navigations with a time-extended situation assessment : the advice are based mainly on similarity of ordered sequence of past accessed documents. In addition, the dynamic of the WWW is addresses in the reuse step and with a specific method for case forgetting.
Broadway-Web is written in Java using the Jigsaw proxy (W3C consortium) and CBR*Tools. It will be soon running on the Web. Click here for the slides of UK-CBR97 presentation.
For more information,
check out
the Broadway-Web pages.
Publications : UKCBR97 [ps.Z][html][Slides], Be-CBKB , Broadway-PREDICT
A Web interface developed in C++ and running on our Apache internal Web server.is available for the
following methods: SCluster, Div, Cdis, CCClust.
Previous versions of the above software have been integrated in the SODAS 2 Software [93] which
was the result of the european project ASSO5 (2001-2004). SODAS 2 software supports the analysis of
multidimensional complex data (numerical and non numerical) coming from databases mainly in statistical
offices and administration using Symbolic Data Analysis [69]. This software is registrated at APP. The latest
executive version of the SODAS 2 software, with its user manual can be downloaded at http://www.info.fundp.
ac.be/asso/sodaslink.htm. See 2009 AxIS annual report for more details of the main contributions of AxIS to
SODAS [79], [105] which have been registered at APP.
- a java library (the somlib) that provides efficient implementations of several SOM
variants, especially those that can handle dissimilarity data
(available on Inria's Gforge server http://gforge.inria.fr/projects/somlib/,
developed by AxIS Rocquencourt and Brieuc Conan-Guez from Universite de Metz).
- a functional Multi-Layer Perceptron library, called FNET, that implements in C++
supervised classification of functional data (developed by AxIS Rocquencourt).
- two partitionning clustering methods on the dissimilarity tables issued from a collaboration between AxIS Rocquencourt team and Recife University, Brazil: CDis and
CCClust. Both are written in C++ and use the SOL developed for SODAS.
- two improved and standalone versions of SODAS modules, SCluster and DIVCLUST (AxIS Rocquencourt).
- a java implementation of the 2-3 AHC (developed by AxIS Sophia Antipolis). The software is available as a Java applet which runs the hierarchies visualisation toolbox
called HCT for Hierarchical Clustering Toolbox).
We developed a Web interface for the following methods: SCluster, Div, Cdis, CCClust.
Such an interface is developed in C++ and runs on our Apache internal Web server.
Publications : Chelcea's thesis (2-3HAC),Conan-Guez's thesis (SOM, FNET), El Golli's Thesis, ...
- SODAS 2
Analysis System of Symbolic Official Data
|
SODAS 2 developed in C++, is the result of
the European project called ASSO (Analysis System of Symbolic data), that
started in January 2001 for 36 months. It supports the analysis of multidimensional
complex data (numerical and non numerical) coming from databases mainly in satistical
offices and administration using Symbolic Data Analysis.
SODAS 2 is an improved version of the SODAS software developed in the previous
SODAS project, following users'requests. This new software is more operational and at-
tractive. It proposes innovative methods and demonstrates that the underlying techniques
meet the needs of statistical offices.
SODAS allows for the analysis of summarised data, called Symbolic Data. The latest
executive version (version 2.50) of the SODAS 2 Software, with its user manual (PDF
format), can be downloaded at ici
The main contributions of AxIS to SODAS are:
-
1. a Symbolic Object Library (SOL) that provides foundation tools, such as data loading and saving, selection, etc .
-
2. a divisive hierarchical clustering method on complex data tables called DIV
- 3. a partitionning clustering method on complex data tables called SCLUST
- 4. a supervised classification tree for symbolic data, called TREE
- 5. a tool for extracting symbolic objects from databases, called DB2SO, jointly developed with EDF
Those contributions have been registered at APP.
The K-MADe tool is intended for people wishing to describe, analyze and formalize the activities of human
operators, of users, in environments (computerized or not), in real or simulated situation; in the field, or in the
laboratory. Although all kinds of profiles of people are possible, this environment is particularly intended for
ergonomics and HCI (Human Computer Interaction) specialists. It has been developed through collaboration
between ://www.lisi.ensma.fr/ and INRIA. A new release has been delivered on november 1st 2010. It
incorporates the findings from the work of Caffiau and al. . Its history, documentation and tool are
available at: http://kmade.sourceforge.net/index.php.
CLF is a toolbox designed to ease the development of efficient parsers in Prolog. It currently contains a couple
of tools. The first one uses Flex to perform lexical analysis and the second is an extension of Prolog DCGs,
to perform syntactical analysis. It allows right recursion, take advantage of hash-coding of prolog
clauses by modern prolog compilers and keep an automatic link to the source code to ease the development of
tools as compilers with accurate error messages.
This toolbox has been used to produce a parser for XML. It has also been used to produce the specification
formalism SeXML. The generated parsers have been intensively used in our team to parse and analyze XML
files, mainly related to our research applied to the Inria annual activity reports.
BibAdmin developed by S. Chelcea (ex-PhD student) is a publication management tool corresponding to
a collection of PHP/MySQL scripts for bibliographic (Bibtex) management over the Web. Publications are
stored in a MySQL database and can be added/edited/modified via a Web interface. It is specially designed
for research teams to easily manage their publications or references and to make their results more visible.
Users can build different private/public bibliographies which can be then used to compile LaTeX documents.
BibAdmin is made available since the end of 2005 under the GNU GPL license on INRIA's GForge server.
Last modified: Mon Nov 19 13:17:40 CET 2007
|