

Classification
INTRODUCTION
Nous avons donc transformé l'information niveaux de gris en une
information caractéristique de la texture urbaine. En chaque
pixel nous avons 8 valeurs. Nous ne conservons qu'un seul
paramètre de texture. Nous avons fait une analyse en composantes
principales et nous avons conservé le premier canal.
Au
départ nous pensions conserver la valeur minimale comme
paramètre de texture car:
- Les champs répondent faiblement quelque soit la direction.
- La ville répond fortement dans toutes les directions.
- Les objets orientés répondent faiblement dans la direction dans
laquelle ils sont orientés.
Cependant, en utilisant le réponse minimale beaucoup de pixels situés
à la lisière de la ville étaient mal classés (ceci
correspond à une zone de mélange de texture). Nous verrons à la fin que nous allons utiliser la
réponse minimale comme image de marqueurs afin d'éliminer
les fausses alarmes. Elle nous donne les limites intérieures
de la ville.
Nous
classifions ensuite notre image de paramètre en utilisant une
version modifiée de l'algorithme fuzzy Cmeans qui prend
en compte un terme d'entropie. Le terme fuzzy provient
du fait que chaque pixel
appartient à chacune des classes avec un certain degré noté
uij. L'algorithme fuzzy Cmeans a pour but de
déterminer la matrice U=[uij], appelée matrice de partition.
L'avantage de ce nouvel algorithme est qu'il trouve un nombre de
classes optimal. Le nombre de classe n'est pas connu a priori, ce
qui est le cas avec l'algorithme classique. Certes nous avons un
autre paramètre à fixer (alpha) mais qui dépend moins de l'image
à classifier que le nombre de classes.
FUZZY CMEANS MODIFIE
La classification consiste à minimiser le critère suivant:
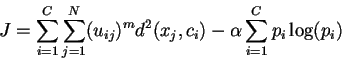
Sous la contrainte suivante:
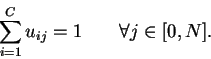
Où:
m caractérise le degré de flou.
C est le nombre de classes.
N est le nombre de pixels.
ci est le vecteur caractéristique de la classe i.
d2(xj,ci) est la distance euclidienne.
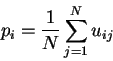 est la probabilité a priori de la classe i.
est la probabilité a priori de la classe i.
ALGORITHME
Nous minimisons le critère J par rapport aux
centroides ci puis, les ci étant fixés,
nous minimisons par rapport aux uij. A chaque
itération nous ne conservons que les classes dont la probabilité
est supérieure à un certain seuil.
Les paramètres à l'étape (n) sont mis à jour de la manière suivante (m=2):
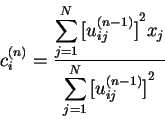
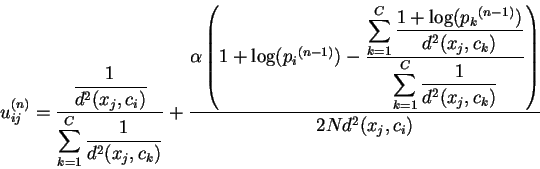
RESULTATS
Les résultats qui suivent montrent l'intérêt d'un tel algorithme qui
ne nécessite pas la connaissance a priori du nombre de
classes. Ainsi, lorsqu'il traite l'image de paramètre d'une zone
non urbaine (colonne de droite) il ne détecte qu'une classe (image f). Au contraire de
l'algorithme classique qui détecte plusieurs classes même dans le
cas où il n'y en a qu'une (image d). Lorsque l'on traite une image
de paramètre dans laquelle existe une zone urbaine on retrouve deux
classes quelque soit l'algorithme utilisé (images c et e).

Last modified: Wed Feb 18 16:58:22 MET 2004