Methodology
The rationale underlying the datasets of natural language arguments we present is to support the task of understanding, given a huge debate, the kinds of relations between the arguments and their justification status. In an application framework, we can divide such task into two consecutive subtasks, namely (i) the recognition of the semantic relations between couples of arguments in a debate (i.e. if one statement is supporting or attacking another claim), and ii) given all the arguments of a debate, to calculate over the graph of arguments which are the accepted ones.
To reflect this separation into two subtasks, each dataset that we will describe in detail in the following subsections is therefore composed of two layers. Given a set of arguments linked among them (e.g. in a debate):
- we couple each argument with the argument to which it is related (i.e. that it attacks or supports). The first layer of the dataset is therefore composed of couples of arguments (each one labeled with a univocal ID), annotated with the semantic relations linking them (i.e. attack or support);
- starting from the pairs of arguments in the first layer, we then build a bipolar argumentation graph for each of the topic in the dataset. In the second layer of the dataset, we find therefore arguments graphs.
To create the dataset of arguments pairs, we follow the criteria defined and used by the organizers of the Recognizing Textual Entailment challenge. To test the progress of Textual Entailment (TE) systems in a comparable setting, the participants to RTE are provided with datasets composed of pairs of textual snippets (the Text T and the Hypothesis H) involving various levels of entailment reasoning (e.g. lexical, syntactic). The TE systems are required to produce a correct judgment on the given pairs (i.e. to say if the meaning of H can be inferred from the meaning of T). Two kinds of judgments are allowed: two-way (yes or no entailment) or three-way judgment (entailment, contradiction, unknown). To perform the latter, in case there is no entailment between T and H systems must be able to distinguish whether the truth of H is contradicted by T, or remains unknown on the basis of the information contained in T. To correctly judge each single pair inside the RTE datasets, systems are expected to cope both with the different linguistic phenomena involved in TE, and with the complex ways in which they interact. The data available for the RTE challenges are not suitable for our goal, since the pairs are extracted from news and are not linked among each others (i.e. they do not constitute argumentation graphs). However, the task of recognizing semantic relations among pairs of textual fragments is very close to ours, and therefore we follow RTE organizers’ guidelines for the creation of the datasets.
Format
We adopt an XML format, where each pair is identified by a unique ID, and by the task (in our case, argumentation). The element entailment contains the annotated relation of entailment/non entailment between the two arguments in the pair. Differently from RTE dataset, we added the element topic to identify the graph name to which the pair belongs, and an ID to keep track of each text snippet (i.e. each argument). The arguments IDs are unique within each graph.
An example pair from the Debatepedia dataset is as follows:
Debatepedia / ProCon dataset
Our first benchmark of natural language arguments is built on Debatepedia and ProCon, two encyclopedia of pro and con arguments on critical issues. To fill in the first layer of the dataset, we manually selected a set of topics (reported in the table) of Debatepedia/ProCon debates, and for each topic we apply the following procedure:
- the main issue (i.e., the title of the debate in its affirmative form) is considered as the starting argument;
- each user opinion is extracted and considered as an argument;
- since attack and support are binary relations, the arguments are coupled with:
- the starting argument, or
- other arguments in the same discussion to which the most recent argument refers (i.e., when a user opinion supports or attacks an argument previously expressed by another user, we couple the former with the latter), following the chronological order to maintain the dialogue structure;
- the resulting pairs of arguments are then tagged with the appropriate relation, i.e., attack or support Using Debatepedia/ProCon as case study provides us with already annotated arguments (pro means entailment, and con means contradiction), and casts our task as a yes/no entailment task.
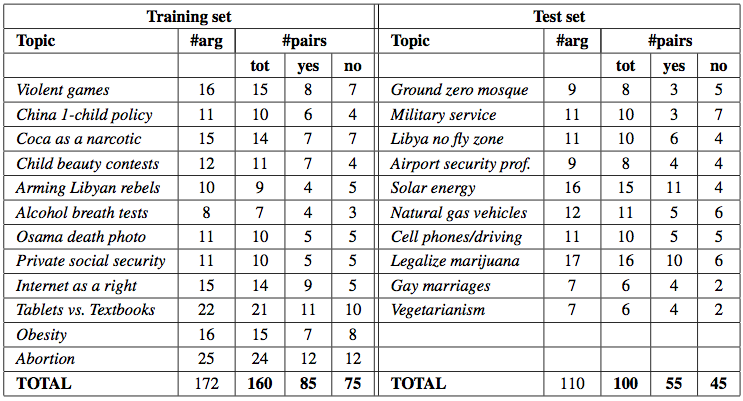
Debatepedia / ProCon dataset
[download (.zip)]
Debatepedia / ProCon graphs (png files - green edges for support, red edges for attack)
[download (.zip)]
260 pairs (140 supports, 120 attacks, 24 bipolar argumentation graphs)
K = 0.7 (2 annotators, 100 pairs)
Debatepedia / ProCon extended dataset (with distinction support/entailment and attack/contradiction)
[download (.zip)]
Debatepedia / ProCon additional attacks dataset
[download (.zip)]
Debatepedia / ProCon additional attacks graphs (png files - green edges for support, red edges for attack)
[download (.zip)]
Twelve Angry Men dataset
Our second benchmark of natural language arguments is built on the script of the play "Twelve Angry Men" (Wikipedia article). The play concerns the deliberations of the jury of a homicide trial. The story begins after closing arguments have been presented in the homicide case. At the beginning, jurors have a nearly unanimous decision of guilty, with a single dissenter of not guilty, who throughout the play sows a seed of reasonable doubt. The play is divided into three acts: the end of each act corresponds to a fixed point in time (i.e. the halfway votes of the jury, before the official one).
For each act, we manually selected the arguments (excluding sentences which cannot be considered as self- contained arguments), and we coupled each argument with the argument it is supporting or attacking in the dialogue flow. In discussions, one character's argument comes after the other (entailing or contradicting one of the arguments previously expressed by another character): therefore, we create our pairs in the graph connecting the former to the latter (more recent arguments are placed as T and the argument with respect to whom we want to detect the relation is placed as H).
Twelve Angry Men dataset
[download (.zip)]
Twelve Angry Men graphs (png files - green edges for support, red edges for attack)
[download (.zip)]
80 pairs (25 supports, 55 attacks, 3 bipolar argumentation graphs)
K = 0.74 (2 annotators, 40 pairs)
Wikipedia dataset
Our third benchmark of natural language arguments is built on two dumps of the English Wikipedia (Wiki 09 dated 6.03.2009, and Wiki 10 dated 12.03.2010), and we focus on the five most revised pages at that time (i.e. George W. Bush, United States, Michael Jackson, Britney Spears, and World War II). We then follow their yearly evolution up to 2012, considering how they have been revised in the next Wikipedia versions (Wiki 11 dated 9.07.2011, and Wiki 12 dated 6.12.2012).
After extracting plain text from the above mentioned pages, for both Wiki 09 and Wiki 10 each document has been sentence-splitted, and the sentences of the two versions have been automatically aligned to create pairs. Then, to measure the similarity between the sentences in each pair, following we adopted the Position Independent Word Error Rate (PER), i.e. a metric based on the calculation of the number of words which differ between a pair of sentences. For our task we extracted only pairs composed by sentences where major editing was carried out (0.2 < PER < 0.6), but still describe the same event. For each pair of extracted sentences, we create the TE pairs setting the revised sentence (from Wiki 10) as T and the original sentence (from Wiki 09) as H. Starting from such pairs composed by the same revised argument, we checked in the more recent Wikipedia versions (i.e. Wiki 11 and Wiki 12) if such arguments have been further modified. If that was the case, we created another T-H pair based on the same assumptions as before, i.e. setting the revised sentence as the T and the older sentence as the H
Wikipedia revision history dataset
[download (.zip)]
Wikipedia graphs (png files - green edges for support, red edges for attack)
[download (.zip)]