Research Interests
I mainly work on problems related to the optimization of telecommunication networks using tools from algorithmic, combinatorics, and optimization, and, then by testing the proposed solutions in practice through simulation, emulation or experimentation.
Typically a telecom network is modeled by a graph. A vertex can represent a processor, a router, a radio equipment, a site or a person. An edge corresponds to a connection between the elements represented by the vertices (logical or physical connection). Additional information can be associated with vertices (number of ports, cost of equipment) or edges (weight which corresponds to a length, a cost, a capacity). Various models can be defined according to the application and this modeling is an important task.
A generic and recurring question on network and storage infrastructures is to find the best compromise between where to store data, where to perform the calculations, how much traffic to send in the network and by which route. The objective to be optimized can be quite diverse: minimizing costs, energy consumption, the probability of failures or maximizing user satisfaction? This question has been present throughout the development of telecoms and has come up in different forms during my work.
Machine Learning for Networks
There is a growing trend in telecommunication networks to revisit classic network problems using ML techniques. In the coming years, I plan to focus on how these methods can be used to solve resource placement problems or other network problems such as anomaly detection. I have thus started a course Data mining for networks in the international Ubinet course of the Master of Engineering at the Universite Cote d'Azur where I present how to use graph kernel methods to detect anomalies. The analysis of clustering of very large social networks is also the subject of the PhD of Thibaud Trolliet.
A fundamental problem that appears in this context to use artificial intelligence methods for networks is how to efficiently code telecommunication networks in digital form and how to choose a good set of features. This problem is called graph embedding (GE). Several solutions have been proposed in the literature. One of the ideas, for example, is to try to reproduce the structure of convolution networks that have shown their efficiency for image analysis, by combining information from neighboring nodes and adjacent links in the graph. In Hicham Lesfari's thesis, we started to compare different embeddings of graphs into deep neural networks to solve problems of dynamic allocation of network resources. This is the subject of the ANR-JCJC Artic (ARTificial Intelligence-based Cloud network control) 2019-2022 led by Ramon Aparicio-Pardo with whom I have started a collaboration and in which the new MAASAI team of Inria Sophia Antipolis on machine learning is an integral part.
|
Virtualized Software Defined Networks
Software-defined networking (SDN) has been attracting a growing attention in the networking research community in recent years. SDN is a new networking paradigm that decouples the control plane from the data plane. It provides a flexibility to develop and test new network protocols and policies in real networks, see e.g. the experiment of Google for its inter-datacenter network. Network Function Virtualization (NFV) is an emerging approach in which network functions are no longer executed by proprietary software appliances but instead, can run on generic-purpose servers located in small cloud nodes. Examples of network functions include firewalls, load balancing, content filtering, and deep packet inspection. This technology aims at dealing with the major problems of today’s enterprise middlebox infrastructure, such as cost, capacity rigidity, management complexity, and failures. One of the main advantages of this approach is that Virtual Network Functions (VNFs) can be instantiated and scaled on demand without the need of installing new equipment. These new technologies bear the promise of important cost savings and of new possibilities but introduces new complex problems, which need to be addressed. In particular, how to carry out efficient (dynamic) resource allocations of both paths and virtualized resources? This is the topic of the PhDs of Andrea Tomassilli, Giuseppe di Lena (CIFRE with Orange), and Adrien Gausseran.
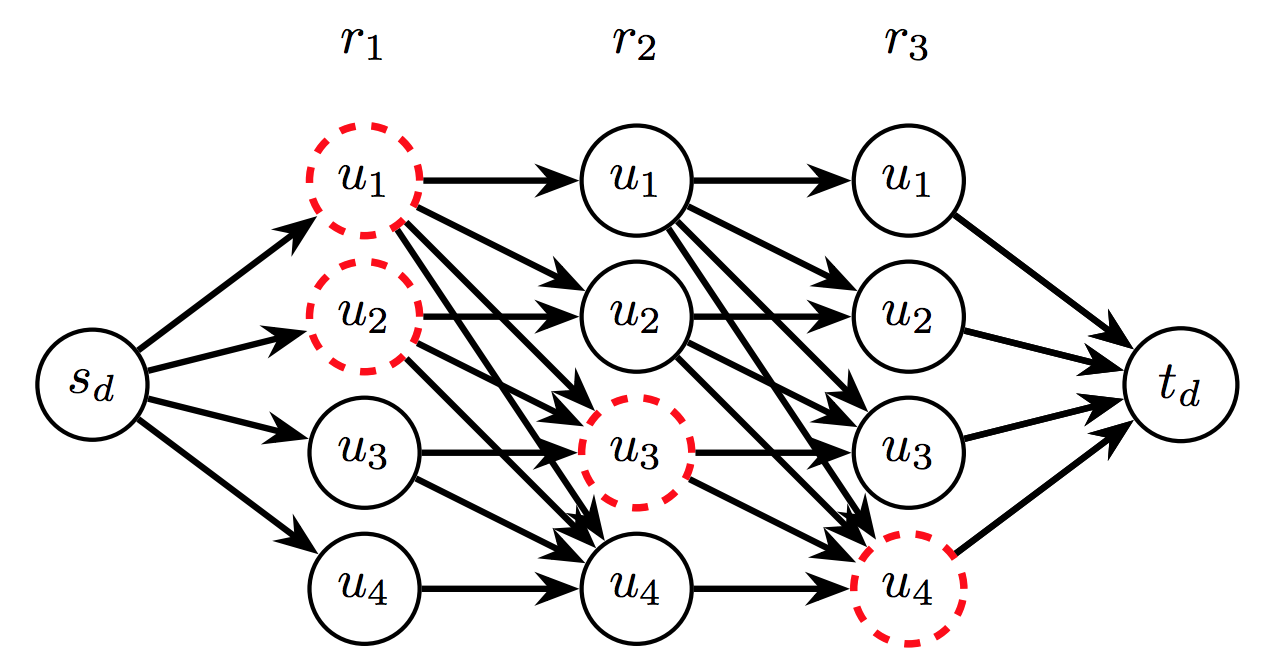
The Virtualized Programmable Networks model enables telecom operators to offer complex and flexible network services. A service is then modeled as a chain of network functions (firewall, compression, parental control, ...) that must be applied sequentially to a data stream. These chains are called Service Function Chains or SFC for short. The problem then is how to route requests and place the virtual network functions of the service function chains through which the requests must pass. My two main works on the subject are the following.
In the first [HJG17,HJG18], we try to find the best compromise between the use of bandwidth and the number of slots to host the network functions. We propose a column generation model for routing and placement of service chains. We are the first to propose an exact model that scales. We show through extensive experimentation that we can optimally solve the problem in less than a minute for networks with up to 65 nodes and 16000 requests. We have also studied the fault tolerance of these systems [THJG18].
In the second [TGHP18], we study the problem of service function placement, which consists in determining on which nodes to locate functions in order to satisfy all service requests, so as to minimize the cost of deployment. We show that the problem can be reduced to a Set Cover problem, even in the case of ordered sequences of network functions. This allowed us to propose the first approximation algorithms with a logarithmic factor, which is the best possible factor.
|
Video streaming systems
Most of the data exchanged over the Internet is video with an estimated share of 82% of all Internet traffic in 2022 [Cisco Visual Networking Index]. It is thus of crucial importance both for Internet Service Provider and for the quality of experience users to develop efficient solutions to distribute video. In live video streaming systems, a source streams a video to a set of clients who want to watch the video in real-time. Streaming video can be done over a classic client/server architecture or a distributed (e.g. peer-to-peer (P2P)) one. Distributed solutions are very efficient for live streaming scenarios in which clients watch the video at the same time. The advantage is that the bandwidth of every user can be used to forward the video to other users, lightening the source load. I studied P2P video streaming systems
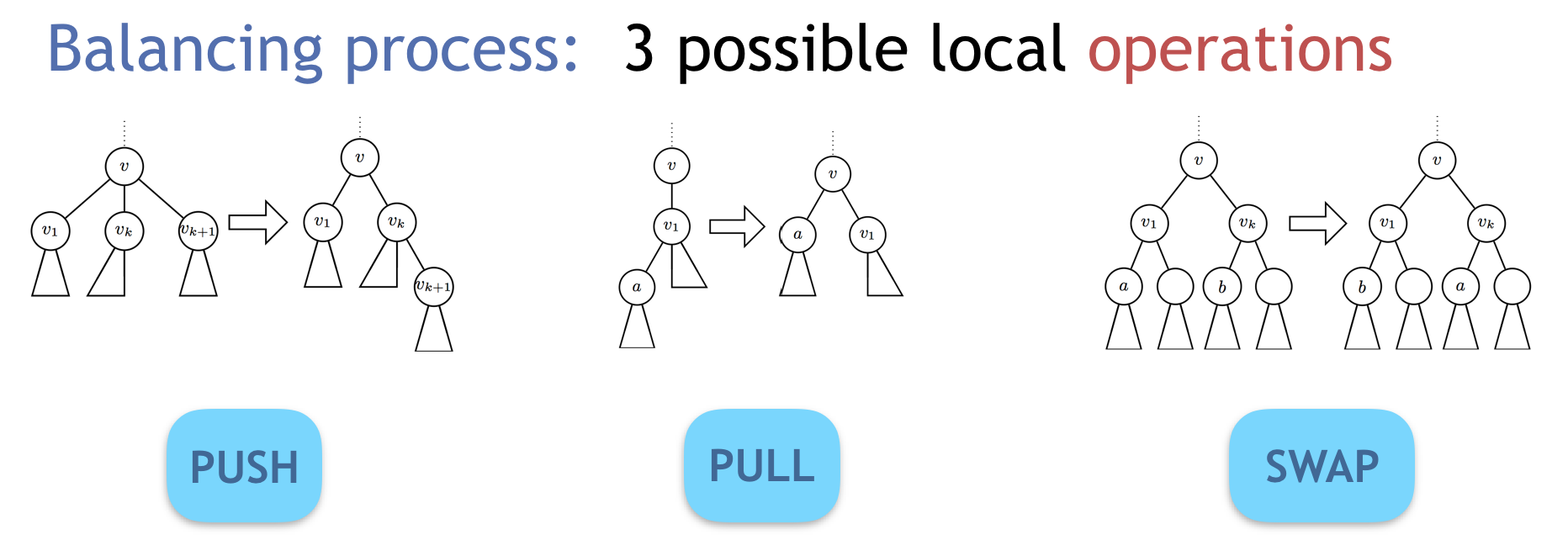
P2P networks are of two types, with structured or unstructured overlays. In the first type, the nodes are organized according to a (or several) logical tree(s), called diffusion tree(s). The source of the video is the root and the video is distributed from the source to the leaves, fathers forwarding the video to their children. In an unstructured overlay, the tree is not explicitly defined: a node having chunks of the video forwards opportunistically these chunks to nodes who miss them. This second type of systems are the most frequently used as they handle very easily churn, i.e., the departure and arrival of users, which are very frequent in live video systems. Frequent churn is the main problem of live distributed streaming system and the main difference from classical multicast systems. Structured overlays have the disadvantage that churn breaks their diffusion trees. However, we have hints that such systems can in fact be very efficient. We propose and analyze several simple local algorithms able to maintain balanced diffusion trees under frequent churn [GMNP13,GH15,GMNP17,THG19].
CIFRE with EasybroadcastIn collaboration with Guillaume Urvoy-Keller, I supervise the CIFRE PhD thesis of Zhejiayu Ma. EasyBroadcast is a startup that solves the cost and quality challenges to stream video and audio content over the Internet or enterprise networks with a patented hybrid streaming technology. It was founded in January 2016 in Nantes, France, by Soufiane Rouibia. The technology makes each viewer contribute to the delivery infrastructure by streaming part of the content he is watching to other viewers. This improves the quality of streaming, reducing churn, making viewers spend more time watching content and reducing infrastructure costs and dependancy. Based on its patented technology, EasyBroadcast provides ent-to-end streaming solutions for TV channels, OTT (Over The Top) players and Enterprises. The goal of the PhD thesis of Zhejiayu Ma is to use machine learning methods to improve Easybroadcast solution using machine learning approaches.
 |
Distributed Storage Systems (more here)
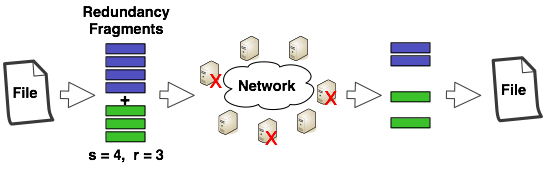
Large scale peer-to-peer systems are foreseen as a way to provide highly reliable data storage at low cost. To achieve high durability, such P2P systems encode the user data in a set of redundant fragments and distribute them among the peers (see Figure 3). This redundancy has to be constantly monitored and maintained by a reconstruction process due to the occurrence of peer failures or departures. Indeed, the system performance depends on many parameters that need to be well tuned, such as the factor of redundancy, the code scheme used, the frequency of data repair and the size of a data block. These parameters impact the amount of resources (e.g., bandwidth, storage space, etc.) needed to obtain a certain reliability (e.g., probability to lose data). On this topic, I co-supervised the PhD of Julian Monteiro. which aimed at providing tools to analyse and predict the performance of large scale data storage systems. Thus, different techniques are studied and applied. They range from formal analysis (using Markov chains and fluid models), simulations, and experimentation (using Grid5000 platform). By comparing to simulations, we show that Markov chain models give correct approximations of the system average behavior, but fails to capture its variations over time. Our main contribution is a new stochastic model based on fluid approximation, that capture the deviations around the mean behavior. We also use queuing models to estimate the repair time under limited bandwidth. We additionally study different ways to distribute fragments (placement strategies), and study a hybrid code that reduces the repair bandwidth consumption. Lastly, we conducted real experimentation on the Grid5000 platform to validate our results.
Recently, in February 2020, I have been invited at CMM in Chili to work on the prototyping of a distributed storage backend for the Vera C. Rubin Observatory. We used Markov chains models to compare different design solutions maximizing the expected data lifetime.
 |
Energy Efficiency (more here)
On this topic, I led the ANR JCJC DIMAGREEN on energy efficiency. The objectives of the project were to introduce and analyze energy-aware network designs and managements in order to increase the life-span of telecommunication hardware and to reduce the energy consumption together with the electricity bill. The project is decomposed into three main tasks:
Task 1: Performance evaluation and Measurements. In order to evaluate the energy utilization of a whole network, the power consumption of the different elements of the network, such as a router, has to be studied. This study will also be the basis to propose specific realistic cost functions for the network devices.
Task 2: Network Design. The power consumption of a network is strongly influenced by its topology. We plan to study several topologies and their influence on the power consumption. Also, where to place the servers and what is the optimal number of servers for a domain are interesting questions. For the design of the networks, we plan to use some of the results on the router power consumption found during Task 1.
Task 3: Network Management. This last task is of major importance when the network has already been designed and when we can play mostly only on the routing to save energy. The goal here will be to find energy-aware routing policies that take into account the new characteristics of traffic.
 |
Network Security
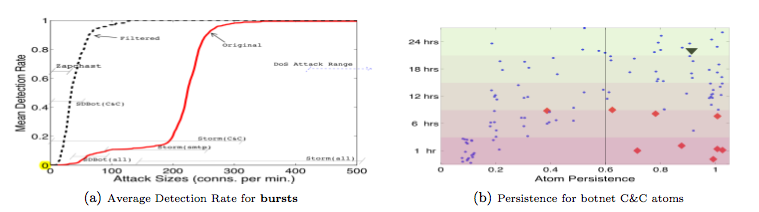
From January 2007 to February 2008, I did a postdoc in the Intel Research Laboratories in Berkeley (US). I worked on methods for providing security to end hosts in typical enterprise environments. The research is focused on making end host security customizable and adaptable by exploring design profiles based on the end host's communication traffic and using these for anomaly detection (see the poster for Intel open house). The first phase consisted of an analysis of various end-host behaviours using a large-scale trace collection of more than 300 corporate machines. The study led a to two publications [GCI+08], [ACG+07] and to two technical reports that are under submission [GCT+07], [GCI+07]. In the current second phase of the project, we are working on new detection algorithms that would be able to face the new threats for networks, e.g. botnets [GCT+08], [BGT+08]. This study led to a patent.
 |
Analysis of Algorithms: Cardinality Estimates (more here).
I obtained a PhD in Computer Science, Telecommunications and Electronics from the University Paris 6: Networks, algorithmics and analytic combinatorics of very large data sets, defense November 29th 2006. My advisors were Philippe Flajolet (INRIA) and Michèle Soria (Paris 6). The jury was also composed by Anne Doucet (Paris 6), Fabrice Guillemin (France Telecom), Christian Lavault (Paris 13) and Jean-Claude Bermond (CNRS).
During my PhD, I worked in the ALGO Project of INRIA Rocquencourt on probabilistic algorithms for estimating the number of distinct elements (or cardinality) of very large data sets. This project is sponsored by the French National Research Agency. I introduced new families of estimates based on order statistics in [Gir05] and [Gir08]. These algorithms attain a precision of C/sqrt(M) using M units of memory to compare with the linear memory of exact algorithms. These estimates were extensively validated with an optimized version of the algorithm (project page). In a joint work with E. Fusy, we adapt these algorithms to monitor data streams [FuGi07]. Applications for such algorithms are numerous in networking area, for example to monitor the traffic of a router or to detect Denial of Service attacks (see [Gir05] and [FuGi07]), as well as in bioinformatics, for example to detect coding regions in DNA (see [Gir06]).
Network Design: Satellites
I am also collaborating with the MASCOTTE Project on fault tolerant networks. The problem was posed by Alcatel Space Industry in order to decrease the launch cost of their satellites. We proposed solutions for small networks in [ABG+06,BGP07]. More generally, these networks correspond to a generalization of selectors. We proved tight linear bounds for large networks and studied a general property of graphs, namely the expansion for subsets of bounded size, in [AGHP08].
Network Design: Backbone Fault Tolerance.
In 2002, during an internship of 6 months in the IP group of the Sprint Laboratories of Research in Burlingame California, I worked on IP protection for backbone networks. We proposed a new algorithm based on Tabu Search Meta-heuristic, to optimally map the IP topology on a fiber infrastructure. The optimal mapping maximizes the robustness of a network by minimizing fiber sharing, while simultaneously maintaining ISP delay requirements. In addition the algorithm takes into consideration constraints that are faced by backbone administrators, such as a shortage of wavelengths or priorities among links (see [GNTD03]). This study led to two patents, of which I am coauthor, for Sprint.
Bioinformatics.
In 2003, during my master, I worked on bioinformatics issues with Mireille Régnier. They are four main steps to sequence a genome: duplicate the DNA, cut it into small pieces, read each of them and reassemble them. One of the most difficult problem during the fourth step is to distinguish between pieces of the numerous nearly identical repeats. We proposed a new algorithm to separate repeats using an analysis with generating functions. The same kind of techniques may be used to find single nucleotide polymorphisms (SNPs) that are crucial, for example, to understand genetic diseases ([Gir03], in French).