| Browsing |
| Home: | Java Fair Threads |
|---|---|
| Previous chapter: | Introduction |
| Next chapter: | Fair Thread Framework |
| Threads |
2.1 Scheduling Strategies 2.2 Existing Threading Frameworks 2.3 Conclusion
| Chapters |
1. Introduction 2. Threads 3. Fair Thread Framework 4. Java FairThreads API 5. Examples 6. Links with Reactive Programming 7. Conclusion
Fig. 1: A Thread
Fig. 2: A Scheduler
Context Switches
When the processor is released by a thread, its execution context has to be saved in order to be able to resume the thread later. This is called a context switch. Context switches basically means to save the program counter and the execution stack associated with the executing thread, then to restore the context of a new thread (usually, some others items must also be saved/restored; for simplicity, we do not consider these).
Threads vs Processes
As opposite to threads, processes have their own private memory space. This implies that communication between processes is more complex than communication between threads, which can directly use shared memory. This also implies that context switches are simpler for threads, since there is no need to save the address space which always remains the same. Because threads context switches need less computing resource than process context switches, threads are sometimes called lightweight processes. Note also that less memory swaps are needed using threads than using processes, as threads do not have their own private memory.
Nondeterminism
The way the scheduler chooses the thread to be executed is usually left unspecified; in this way, implementations are less constrained and, thus, can be more efficient. However, nondeterminism may occurs: with the same input, several distinct outputs are possible, depending on the scheduler choices. A major drawback of nondeterminism is that debugging becomes more complex (for example, faulty executions are more difficult to replay).
| 2.1 Scheduling Strategies |
There are two basic scheduling strategies for chosing the next thread to execute, called cooperative and preemptive.
In the cooperative strategy, the scheduler has no way to force a thread to release the processor. Thus, if the executing thread never releases the processor, then other threads never get a chance to execute. This situation can occur when, for example, the executing thread enters in an infinite loop. It is certainly a bug; however, in a cooperative context, this kind of bug is dramatic as it freezes the whole system. In order to avoid such situations, threads must cooperate with other threads and always release the processor after some time.
In a preemptive strategy, the scheduler can force the executing thread to release the processor, when it decides to do so. Scheduler can use several criteria to withdraw the processor from the thread; one criteria is related to execution time: time slices are allocated to threads, and context switch occurs when the time slice given to an executing thread is expired. Other criteria exist, for example criteria related to priorities; for simplicity, one does not consider these.
Pros and cons for cooperative and preemptive strategies are the following:
Non-cooperative threads
There is no possibility, in the general case, to decide if a thread is cooperative or not (this is an undecidable problem). Thus, thread cooperativeness cannot be checked automatically and is of the programmer's responsability. This is a real problem for cooperative strategies, as presence of a non-cooperative thread can prevent the global system to work properly. On the contrary, presence of non-cooperative threads is not a problem for preemptive strategies, because they can be forced to release the processor.
Reasoning with threads
In a cooperative framework, execution of a thread cannot be interrupted by the scheduler at arbitrary moments. This makes reasonning on programs easier: actually in a cooperative framework, thread execution is atomic as long as the thread does not release the processor. This contrast with preemptive context, where, by default, the scheduler can freely interleave threads instructions.
Reusability
In a preemptive context, traditional sequential programs can be embbeded in threads and run without risk to prevent other threads to execute. Thus, preemptive schedulers are a good point for reusability. On the contrary, a "third-party" sequential program cannot be used just as it is in a cooperative framework, as it could prevent the whole system to progress.
Nondeterminism
Preemptive schedulers are less deterministic than cooperative ones. Actually, both kinds of schedulers have freedom to chose the next thread to execute; however, a preemptive scheduler has additional freedom to preempt or not the currently executing thread; this additional freedom is a supplementary source of nondeterminism.
Data protection
In preemptive frameworks, access to data in the shared address space must be protected because thread switches can occur in the middle of an access. Protection is usually based on use of boolean variables, called locks; a lock is set (taken) by the thread at the beginning of the data use and reset (released) by it at the end; while the lock is taken, other threads willing to access the protected data have to wait for the lock to be released. The test of a lock and its setting must be an atomic action, otherwise the scheduler could withdraw the processor to the thread just in between the test and the setting, leaving the data unprotected. Programmers are thus, in preemptive contexts, highly concerned with data protection. However, deadlocks can occur because of a bad locking strategy (a first thread locks a data needed by a second thread which similarly holds a lock on a data needed by the first). On the contrary, data are not to be protected in a cooperative framework, where threads run atomically. Note that atomicity of test and set actions is automatic; thus, simple boolean variables can be safely used for data protection.
Efficiency
Basically, threads unefficiency comes from context switches. In a preemptive strategy context switches are not under control of the programmer, but of the scheduler; in some cases, the scheduler thus introduces context switches which are not necessary but cannot be avoided by programmers. In a cooperative context, it is the programmer's responsability to introduce cooperation actions in order to obtain threads cooperation. One thus generally considers that cooperative strategies can lead to more efficient executions than preemptive ones.
| 2.2 Existing Threading Frameworks |
Threading systems can be implemented in several ways, depending on the
way kernel resources are used.
On one extreme, there are systems in which user threads are mapped to
kernel threads in a one-to-one way. One get the picture of Figure
One-one-mapping.
One-to-one Mapping
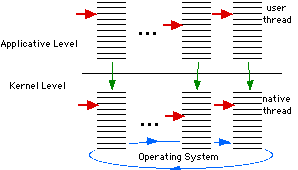
Fig. 3: One-to-One Mapping
Many-to-one Mapping
On the other extreme, all user threads can be mapped on one unique kernel thread. This many-to-one mapping correspond to Figure Many-one-mapping.
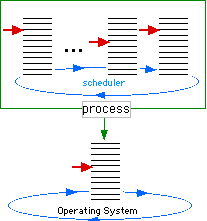
Fig. 4: Many-to-One Mapping
Many-to-many Mapping
There are also intermediate approaches, in which user threads are mapped to several kernel threads. This is the solution proposed by the Solaris system of Sun [4]. In Solaris terminology, user threads are mapped to green thread which are grouped in light weight processes (LWP). LWPs are the units scheduled by the operating system. This many-to-many approach is represented on Figure Many-many-mapping.
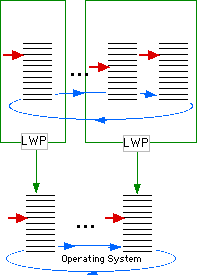
Fig. 5: Many-to-Many Mapping
Thread Libraries and Threads in Languages
A lot of thread libraries exist, for a large number of languages.
Among these is the Pthread library [12] which implements in
C the POSIX standard for threads.
Linux Threads [2] proposes an implementation of POSIX for
Linux. Each Linux thread is a separate Unix process, sharing its
address space with the other threads (using the system call
clone()). Scheduling between threads is handled by the kernel
scheduler, just like scheduling between Unix processes.
Recently, Gnu Portable Threads [8] have been proposed with
portability as main objective; they are purely cooperative threads.
Very few languages introduce threads as first class primitives. The
most well-known is of course Java [6]. Actually, however, Java
basically introduces locks (with the synchronized keyword), and
not directly threads which are available through an API.
The CML language [13] is an other language with threads; it
introduces threads in the functional programming framework of ML. CML
threads are run by a preemptive scheduler.
Java Thread
It is very difficult to design threaded systems which run in the same way on both preemptive and cooperative frameworks. Most of the time, threaded systems do not fulfill this requirement, and are thus not portable. In the context of Java, task is even more difficult because no assumption can be made about the JVM scheduling strategy. No assumption can neither be made on the way the JVM is implemented (process, native thread, or something else). In this situation, programmers have to face a situation where:
- Each thread can be preempted at any time, because scheduling can be preemptive. This implies that data have to be protected by synchronized code, as soon as they can be accessed by two distinct threads. These protections are unnecessary when a cooperative strategy is used.
- Each thread must periodically give up control in order to
cooperate with other threads, because scheduling can be
cooperative. Note that the basic
yield()method for cooperation has a very loose semantics: it does not force a change of processor assignment, but only allows it to take place. Note also thatsleep(long), which forces the executing thread to release processor, is not portable as it depends on the machine execution speed.
| 2.3 Conclusion |
We are faced to the (seemingly contradictory) following needs:
- A preemption mechanism is absolutely necessary for code reuse.
- Thread systems should be as deterministic as possible (in particular, for debugging concerns).
- There should be a way to limit to the minimum the use of deadlock prone constructs such as locks.
- One should have possibility to get fine control over threads execution, for being able to program user-defined scheduling strategies.
- Thread context switchings, even if they are cheaper than processes ones, are rather expensive and memory consuming. It should exist a way to limit them to the strict minimum.