One popular robust technique is the so-called M-estimators.
Let ![]() be the residual of the
be the residual of the ![]() datum, the difference
between the
datum, the difference
between the ![]() observation and its fitted value. The standard
least-squares method tries to minimize
observation and its fitted value. The standard
least-squares method tries to minimize ![]() , which is unstable if there
are outliers present in the data. Outlying data give an effect so strong
in the minimization that the parameters thus estimated are
distorted. The M-estimators try to reduce the effect of outliers by
replacing the squared
residuals
, which is unstable if there
are outliers present in the data. Outlying data give an effect so strong
in the minimization that the parameters thus estimated are
distorted. The M-estimators try to reduce the effect of outliers by
replacing the squared
residuals ![]() by another function of the residuals, yielding
by another function of the residuals, yielding
where ![]() is a symmetric, positive-definite function with a unique minimum at
zero, and is chosen to be less increasing than square. Instead of
solving directly this problem, we can implement it as an iterated
reweighted least-squares one. Now let us see how.
is a symmetric, positive-definite function with a unique minimum at
zero, and is chosen to be less increasing than square. Instead of
solving directly this problem, we can implement it as an iterated
reweighted least-squares one. Now let us see how.
Let ![]() be the parameter vector to be
estimated. The M-estimator
of
be the parameter vector to be
estimated. The M-estimator
of ![]() based on the function
based on the function ![]() is the vector
is the vector ![]() which is the solution of the following m equations:
which is the solution of the following m equations:
where the derivative ![]() is called the
influence function.
If now we define a weight function
is called the
influence function.
If now we define a weight function
then Equation (29) becomes
This is exactly the system of equations that we obtain if we solve the following iterated reweighted least-squares problem
where the superscript ![]() indicates the iteration number. The
weight
indicates the iteration number. The
weight ![]() should be recomputed after each iteration in
order to be used in the next iteration.
should be recomputed after each iteration in
order to be used in the next iteration.
The influence function ![]() measures the influence of a datum on
the value of the parameter estimate. For example, for the least-squares with
measures the influence of a datum on
the value of the parameter estimate. For example, for the least-squares with
![]() , the influence function is
, the influence function is ![]() , that is, the influence of
a datum on the estimate increases linearly with the size of its error, which
confirms the non-robusteness of the least-squares estimate.
When an estimator is robust, it may be inferred that the influence of
any single observation (datum) is insufficient to yield any
significant offset [18]. There are several constraints that a robust
M-estimator should meet:
, that is, the influence of
a datum on the estimate increases linearly with the size of its error, which
confirms the non-robusteness of the least-squares estimate.
When an estimator is robust, it may be inferred that the influence of
any single observation (datum) is insufficient to yield any
significant offset [18]. There are several constraints that a robust
M-estimator should meet:
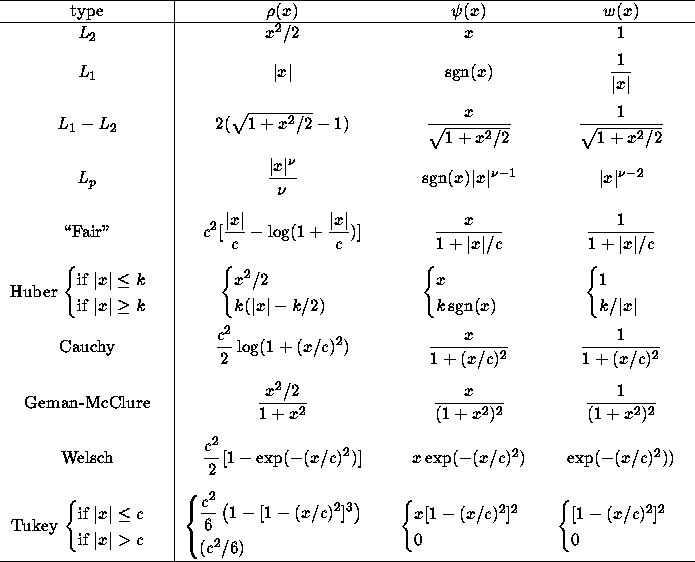
Table 1: A few commonly used M-estimators
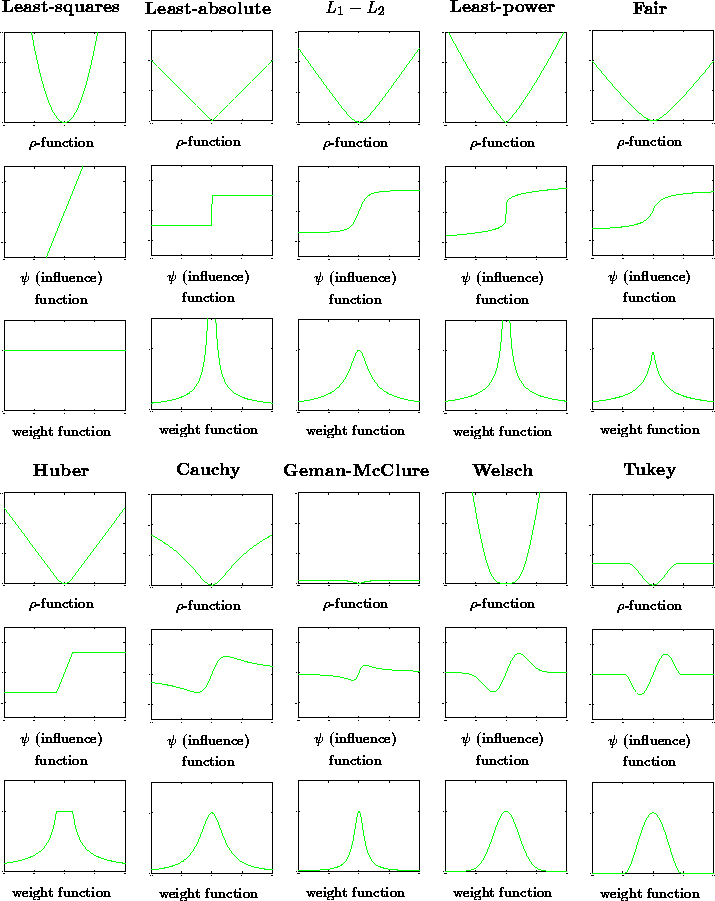
Figure 4: Graphic representations of a few common M-estimators
Briefly we give a few indications of these functions:
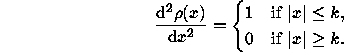
The modification proposed in [18] is the following
The 95% asymptotic efficiency on the standard normal distribution is obtained with the tuning constant c=1.2107.
There still exist many other ![]() -functions, such as Andrew's cosine wave
function. Another commonly used function is the following tri-weight one:
-functions, such as Andrew's cosine wave
function. Another commonly used function is the following tri-weight one:
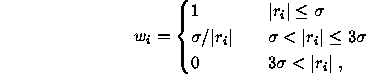
where ![]() is some estimated standard deviation of errors.
is some estimated standard deviation of errors.
It seems difficult to select a ![]() -function for general use without being
rather arbitrary. Following Rey [18], for the location (or regression)
problems, the best choice is the
-function for general use without being
rather arbitrary. Following Rey [18], for the location (or regression)
problems, the best choice is the ![]() in spite of its theoretical non-robustness:
they are quasi-robust. However, it suffers from its computational
difficulties. The second best function is ``Fair'', which can yield nicely
converging computational procedures. Eventually comes the Huber's function (either
original or modified form). All these functions do not eliminate completely the
influence of large gross errors.
in spite of its theoretical non-robustness:
they are quasi-robust. However, it suffers from its computational
difficulties. The second best function is ``Fair'', which can yield nicely
converging computational procedures. Eventually comes the Huber's function (either
original or modified form). All these functions do not eliminate completely the
influence of large gross errors.
The four last functions do not guarantee unicity, but reduce considerably, or even
eliminate completely, the influence of large gross errors. As proposed by
Huber [7], one can start the iteration process with a convex
![]() -function, iterate until convergence, and then apply a few iterations with
one of those non-convex functions to eliminate the effect of large errors.
-function, iterate until convergence, and then apply a few iterations with
one of those non-convex functions to eliminate the effect of large errors.