| Prev | Part VI. Advanced Chapter 35. ProActive Peer-to-Peer Infrastructure |  | Next |
| Prev | Part VI. Advanced Chapter 35. ProActive Peer-to-Peer Infrastructure | | Next |
Computational Peer-To-Peer (P2P) is becoming a key execution environment. The potential of 100,000 nodes interconnected to execute a single application is rather appealing, especially for Grid computing. Mimicking data P2P, one could start a computation that no failure would ever be able to stop (and maybe nobody).
The ProActive P2P aims to use spare CPU cycles from organization's or institution's desktop workstations.
This short document explains how to create a simple computational P2P network. This network is a dynamic JVMs network which works like computational nodes.
The P2P infrastructure works as an overlay network. It works with a P2P Service which is a peer which in turn is in computational node. The P2P Service is implemented with a ProActive Runtime and few Active Objects. The next figure shows an example of a network of hosts where some JVMs are running and several of them are running the P2P Service.
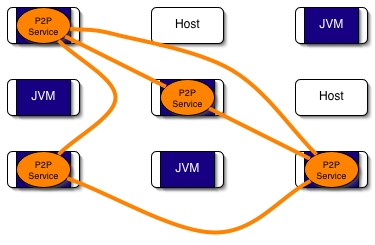
Example of a ProActive P2P infrastructure.
Figure 35.1. A network of hosts with some running the P2P Service
When the P2P infrastructure is running, it is very easy to obtain some nodes (JVMs). The next section describes how to use it.
Further research information is available at http://www-sop.inria.fr/oasis/Alexandre.Di_Costanzo/AdC/Publications.html.
The goals of this work are to use sparse CPU cycles from institutions' desktop workstations combined with grids and clusters. Desktop workstations are not available all the time for sharing computation times with different users other than the workstation owner. Grids and clusters have the same problem as normal users don't want to share their usage time.
Managing different sorts of resources (grids, clusters, desktop workstations) as a single network of resources with a high instability between them needs a fully decentralized and dynamic approach.
Therefore, P2P is a good solution for sharing a dynamic JVM network, where JVMs are the shared resources. Thereby, the P2P Infrastructure is a P2P network which shares JVMs for computation. This infrastructure is completely self-organized and fully configurable.
Before going on to consider the P2P infrastructure, it's important to define what Peer-to-Peer is.
There are a lot of P2P definitions, many of them are similar to other distributed infrastructures, such as Grid, client / server, etc. There are 2 better definitions which describe really P2P well:
From Peer-to-Peer Harnessing the Power of Disruptive Technologies (edited by Andy Oram):
'[...] P2P is a class of applications that take advantage of resources - available at the edges of the Internet [...]'
And from A Definition of Peer-to-Peer Networking for the Classification of Peer-to-Peer Architectures and Applications (Rdiger Schollmeier - P2P'01):
'[...] Peers are accessible by other peers directly [...] Any arbitrary chosen peer can be removed from the network without fault [...]'
P2P's focus on sharing, decentralization, instability and fault tolerance.
A fresh (or new) peer which would like to join the P2P network, will encounter a serious bootstrapping problem or first contact problem: 'How can it connect to the P2P network?'
A solution for that is to use a specific protocol. ProActive provides an interface for a network-centric services protocol which is named JINI. JINI can be used for discovering services in a dynamic computing environment, such as a fresh peer which would like to join a P2P network. This protocol is perfectly adapted to solve the bootstrapping problem. However, there is a serious drawback for using a protocol such as JINI as peer discovering protocol. JINI is limited to working only in the same sub-network. That means JINI doesn't pass through firewalls or NAT and can't be considered to be used for Internet.
Therefore, a different solution for the bootstrapping problem was chosen. The solution for ProActive first contact P2P is inspired from Data P2P Networks. This solution is based on real life , i.e. when a person wants to join a community, this person has to first know another person who is already a member of the community. After the first person has contacted the community member, the new person is introduced to all the community members.
The ProActive P2P bootstrapping protocol works as follows:
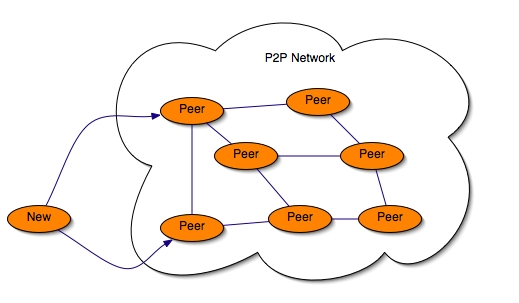
A fresh peer has a list of 'server' addresses. These are peers which have a high potential to be available and to be in the P2P network, they are in a certain way the P2P network core.
With this list the fresh peer tries to contact each server. When a server is reached the server is added to ithe fresh peer's list of known peers (acquaintances).
Then the fresh peer knows some servers, it is in the P2P Network and it is no longer a fresh peer, it is a peer of the P2P network.
Furthermore, in the case of the fresh peer not able to contact any servers from the list, the fresh peer will try every TTU (see below, about Time To Update parameter) to re-contact all of them until one or several of them are finally available. At any moment when the peer knows nobody because all of its acquaintances are no longer available, the peer will try to contact all the servers as explained earlier.
An example of a fresh peer which is trying to join a P2P network is shown by the next Figure. The new peer has 2 servers to contact in order to join the existing P2P infrastructure.
The main particularity of a P2P network is the peers high volatility. This results from various attributes which compose P2P:
Peers run on different kinds of computers: desktop workstations, laptops, servers, cluster nodes, etc.
Each peer has a particular configuration: operating system, etc.
Communicating network between peers consists of different speed connections: modem, 100Mb Ethernet, fiber channel, etc.
Peers are not available all the time and not all at the same moment.
Peer latency is not equal for all.
etc.
The result is the instability of the P2P network. But the ProActive P2P infrastructure deals with these problems with transparency.
ProActive P2P infrastructure aims to maintain a created P2P network alive while there are available peers in the network, this is called self-organizing of the P2P network. Because P2P doesn't have exterior entities, such as centralized servers which maintain peer data bases, the P2P network has to be self-organized. That means all peers should be enabled to stay in the P2P network by their own means.
There is a solution which is widely used in data P2P networks; this consists of each peer keeping a list of their neighbors, a peer's neighbor is typically a peer close to it (IP address or geographically).
In the same way, this idea was selected to keep the ProActive P2P infrastructure up. All peers have to maintain a list of acquaintances. At the beginning, when a fresh peer has just joined the P2P infrastructure, it knows only peers from its bootstrapping step (Section 35.2.2.1, “Bootstrapping: First Contact”). However, depending on how long the list of servers is, many of them could be unreachable, unavailable, etc. and the fresh peer ends up knowing a small number of acquaintances. Knowing a small number of acquaintances is a real problem in a dynamic P2P network when all the servers will be unavailable, the fresh peer will be unconnected from the P2P infrastructure.
Therefore, the ProActive P2P infrastructure uses a specific parameter called: Number Of Acquaintances (NOA). This is a minimum size of the list of acquaintances of all peers. The more the peers are highly dynamic, the more NOA should be high. Thereby, a peer must discover new acquaintances through the P2P infrastructure.
In Section 35.2.2.3, “Asking Computational Nodes”, we will see in detail how the message protocol works. For the moment we will just explain briefly the discovering acquaintances process without going into detail about the message protocol.
The peer called 'Alice' has 2 acquaintances resulting from its first contact with the P2P infrastructure and by default NOA is 10 peers. Alice must find at least 8 peers to be able to stay with a certain guarantee inside the infrastructure.
The acquaintance discovering works as follows:
Send an exploring message to all of its acquaintances, and wait for responses from new acquaintances (not peers that have already been contacted peers and not already known peers).
When receiving an exploring message:
Forward the message to acquaintances until the message Time To Live (TTL) reaches 0.
Choose to be or not to be an acquaintance of the asking peer.
In order to not have isolated peers in the infrastructure, all peers registration are symmetric. That means if Alice knows the peer 'Bob', Bod also knows Alice. Hence, when a peer chooses whether to be an acquaintance or not, the peer has to check previously in its own acquaintance list if it doesn't already know the asking peer. Next, if it's an unknown peer, the peer decides with a random function to be an acquaintance or not. With the parameter of agree responses, it is possible to configure the percentage of positive responses to an exploring message. The random function is a temporary solution to solve the flooding problem due to the message protocol (see Section 35.2.2.3, “Asking Computational Nodes”), we are thinking of using a new parameter Maximum Number of Acquaintances and improving the message protocol. For the moment, we don't consider peers IP addresses or geographical location of the peers as an acquaintances criteria.
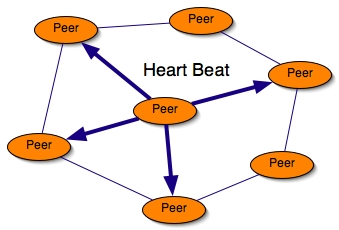
As the P2P infrastructure is a dynamic environment, the list of acquaintances must also be dynamic. Many acquaintances could be unavailable and must be removed of the list. When the size of the list is less than the NOA, the peer has to discover new peers. Therefore, all peers keep their lists up-to-date. That's why a new parameter must be introduced: Time To Update (TTU). The peer must frequency check its own acquaintances' list to remove unavailable peers and discover new peers. To verify the acquaintances availability, the peer send a Heart Beat to all of its acquaintances. The heart beat is sent every TTU.
The next figure shows a peer which is sending a heart beat to all of its acquaintances.
The main goal of this work is to provide an infrastructure for sharing computational nodes (JVMs). Therefore, a resource query mechanism is needed; there are 2 types of resources in this context, thus 2 query types:
Exploring the P2P infrastructure to search new acquaintances.
Asking free computational nodes to deploy distributed applications.
The mechanism is similar to Gnutella's communication system: Breadth-First Search algorithm (BFS). The system is message-based with application-level routing.
All BFS messages must contain this information:
A Unique Universal Message Identifier (UUID): this message identifier is not totally universally unique, it is just unique for the infrastructure;
The Time To Live (TTL) infrastructure parameter, in number of hops;
A reference to the requester peer. The peer waits for responses for nodes or acquaintances.
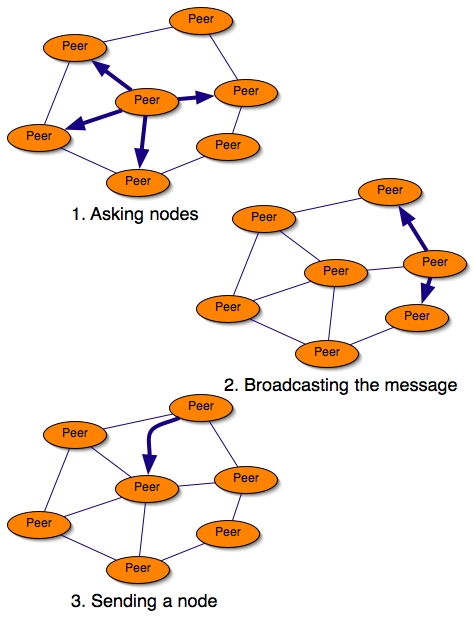
Our BFS inspired version works as follow:
Broadcasting a request message to all of its acquaintances with an UUID, and TTL, and number of asked nodes.
When receiving a message:
Test the message UUID, is it an old message?
Yes, it is: continue;
No, it's not:
Keep the UUID;
I have a free node:
Send the node reference to the caller and waiting an ACK until timeout
if timeout is reached or NACK
continue;
if ACK and asked nodes - 1 > 0 and TTL > 0 then
Broadcast with TTL - 1 and asked nodes -1
continue;
Gnutella's BFS got a lot of justified critics for scaling, bandwidth, etc. It is true this protocol is not good enough but we're working to improve it. We are inquiring into solutions with a not fixed TTL to avoid network flooding.
The next Figure shows briefly the execution of the inspired BFS algorithm:
The P2P infrastructure is implemented with ProActive. Thus the shared resource is not a JVMs but a ProActive node, nodes are like a container which receives work.
The P2P infrastructure is not directly implemented in the ProActive core at the ProActive runtime level because we choose to be above communication protocols, such as RMI, HTTP, Ibis, etc. Therefore, the P2P infrastructure can use RMI or HTTP as communication layer. Hence, the P2P infrastructure is implemented with classic ProActive active objects and especially with ProActive typed group for broadcasting communications between peers due to your inspired BFS.
Using active objects for the implementation is a good mapping with the idea of a peer which is an independent entities that works as a server with a FIFO request queue. The peer is also a client which sends requests to other peers.
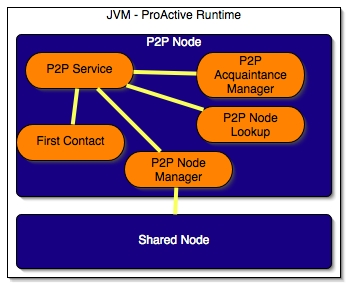
The list of P2P active objects:
P2PService: is the main active object. It serves all register requests or resource queries, such as nodes or acquaintances.
P2PNodeManager: works together with the P2PService, this active object manages one or several shared nodes. It handles the booking node system, see Section 35.3.3, “Sharing Node Mechanism” for more details.
P2PAcquaintanceManager: manages the list of acquaintances and provides group communication, see Section 35.3.2, “ Dynamic Shared ProActive Group”.
P2PNodeLookup: works as a broker when the P2PService asks nodes. All the asking node protocol is inside it. This broker can migrate to a different node to be closer to the deployed application.
FirstContact: it's the bootstrapping object (see Section 35.2.2.1, “Bootstrapping: First Contact”).
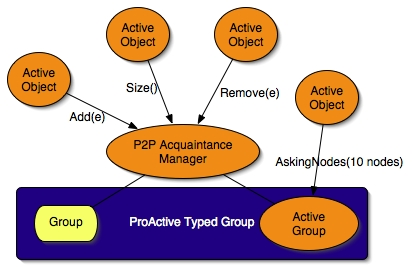
The Figure below shows the connection between all active objects:
All communications between peers use Group communication but for sending a response to a request message, it's a point-to-point communication. Though ProActive communications are asynchronous, it's not really messages which are sent between peers. Nevertheless, it's not a real problem; ProActive is implemented above Java RMI which is RPC and RPC is synchronous. However, ProActive uses future mechanism and Rendez-vous method to turn RPC methods to asynchronous. That means ProActive is asynchronous RPC. Rendez-vous is interesting in your case because it guarantees the method is successfully received by the receiver. With the Heart beat message which is sent a Java exception when an acquaintance is down.
The P2PAcquaintanceManager manages the list of acquaintances, this list is represented by a ProActive typed group of P2PService. This is the point of the next section.
ProActive typed group does not allow access to group elements and make calls from different active objects to the same group is not possible, i.e. a group can not be shared. However, the point of the P2P infrastructure is to broadcast messages to all members on the acquaintance list, ProActive typed group is perfect for doing that. A typed group of P2PService is a good implementation of the acquaintance list design.
But a typed group does not support to be shared by many active objects, especially for making group method calls from different objects, adding / removing / etc. members in the group. For the P2P infrastructure the P2PAcquaintanceManager (PAM) was designed.
The PAM is a standard active object, at its initialization it constructs an empty P2PService group. The PAM provides an access to few group methods, such as removing, adding and group size methods. All other active objects, such as P2PService or P2PNodeLookup, have to use PAM methods to access the group. The PAM works as a server with an FIFO queue behind the group.
That solves the problem of group members accessing but not how other active objects can call methods on the group. The ProActive group API provides a method to active a group that is made possible to get ProActive reference on the group. The PAM actives the group after its creation. P2PService, P2PNodeLookup and all get the group reference from a PAM's getter.
The PAM, during its activity, frequently sends heart beats to remove unavailable peers. The P2PService adds, via the PAM, new discovered acquaintances (P2PService) and the P2PNodeLookup calls group methods to ask nodes to the group reference. The P2PService does also group method calls.
In short, this can be seen in the next Figure:
We just explained how to share a typed group between active objects but that is not solve all the problems. For the moment, the BFS implementation with broadcasting to all acquaintances each time is not perfect due to the message which is always send back to the previous sender. We are working to add member exclusion in a group method call.
The sharing node mechanism is an independent activity from the P2P service. Nodes are the sharing resource of this P2P network. This activity is handled by the P2PNodeManager active object.
At the initialization of the P2PNodeManager (PNM), it has to instantiate the shared resource. By default, it's 1 ProActive nodes by CPUs, for example on a single processor machine the PNM starts 1 node and on a bi-processors machine it starts 2 nodes. It's possible to choose to share only a single node. An another way is to share nodes from an XML deployment descriptor file by specifing the descriptor to the PNM which actives the deployment and gets nodes ready to share.
When the P2P service receives a node request, the request is forwarded (after the BFS broadcast) to the PNM which checks for a free node. In the case of at least 1 free node, the PNM must book the node and send back a reference to the the node to the original request sender. However, the booking remains valid for a predetermined time, this time expires after a configurable timeout. The PNM knows if the node is used or not by testing the active object presence inside the node. Consequently, at the end of the booking time, the PNM kills the node, the node is no longer usable. Though, some applications need empty nodes for a long time before using them, thereby there is a pseudo expand booking time system: creating 'Dummy' active objects in booked nodes for later use. This system is allowed by the P2PNodeLookup.
The P2PNodeLookup could receive more nodes than it needs, for all additional nodes, the P2PNodeLookup sends a message to all PNMs' nodes to cancel its booking on the node.
The deployed applications have to leave nodes after use. Therefore, the PNM offers a leaving node mechanism that is the application sent a leaving message for a specified node to the PNM which kills all node's active objects by terminating their bodies and kills the node. After that, the PNM creates a new node which is ready for sharing. However, if nodes are deployed by an XML descriptor the PNM does't kill the node, it just terminates all its active objects and re-shares the same node.
The asking node mechanism is allowed by the P2PNodeLookup, this object is active by the P2PService when it receives an asking node request from an application. The P2PNodeLookup (PNL) works as a broker, it could migrate to another place (node, machine, etc.) to be near the application.
The PNL aims to find the number of nodes requested by the application. It uses the BFS to frequently flood the network until it gets all nodes or until the timeout is reached. However, the application can ask to the maximum number of nodes, in that case the PNL asks to nodes until the end of the application. The PNL provides a listener / producer event mechanism which is great for the application which wants to know when a node is found.
Finally, the application kills nodes by the PNL which is in charge of contacting all the PNMs of each node and asks them to leave nodes. The PNMs leave nodes with the same mechanism of the booking timeout.
Lastly, the asking nodes mechanism with the PNL is fully integrated to the ProActive XML deployment descriptor.
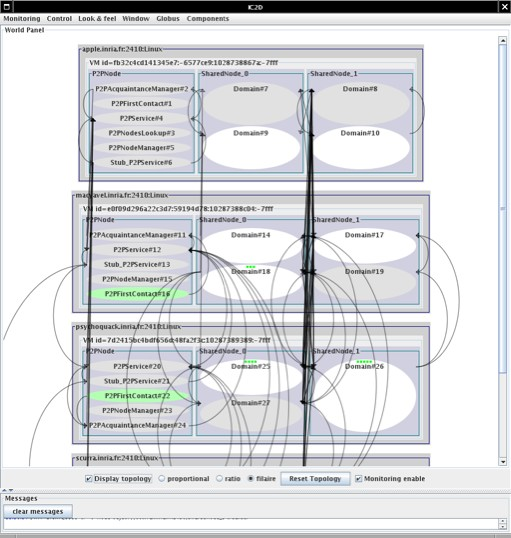
IC2D hides all P2P internal object by default, in order to monitor the infrastructure itself we invite you to check the IC2D documentation Chapter 42, IC2D: Interactive Control and Debugging of Distribution and Eclipse plugin to set the right option.
A screen shot made with IC2D. You can see 3 P2P services which are sharing 2 nodes (bi-processors machines). Inside the nodes there are some active Domain objects from the nBody application which is deployed on this small P2P infrastructure.
The P2P infrastructure is self-organized and configurable. When the infrastructure is running you have nothing to do to keep it up. There are 3 main parameters to configure:
Time To Update (TTU): each peer checks if its known peers are available when TTU expires. By default, its value is 1 minute.
Number Of Acquaintances (NOA): is the minimal number of peers one peer needs to know to keep up the infrastructure. By default, its value is 10 peers.
Time To Live (TTL): in hops for JVMs (node) depth search (acquisition). By default, its value is 5 hops.
All parameter descriptions and the way to change their default values are explained in Section 20.4.3, “ Peer-to-Peer properties ”. Next section shows how to configure the infrastructure when starting the P2P Service with the command line.
The bootstrapping or first contact problem is how a new peer can join the p2p infrastructure. We solved this problem by just specifying one or several addresses of supposed peers which are running in the p2p infrastructure. Next, we will explain how and where you can specify this list of peers.
Now, you just have to start peers. There are two ways to do so:
This method explains how to rapidly launch a simple P2P Service on one host.
ProActive provides a very simple script to start a P2P Service on your local host. The name of this script is startP2PService.
UNIX, GNU/Linux, BSD and MacOsX systems: the script is located in ProActive/scripts/unix/p2p/startP2PService.sh file.
Microsoft Windows system: the script is located in ProActive/p2p/scripts/windows/p2p/startP2PService.bat file.
Before launching this script, you have to specify some parameters to this command:
startP2PService [-acq acquisitionMethod] [-port portNumber] [-s Peer ...] [-f PeersListFile]
-acq acquisitionMethod the ProActive Runtime communication protocol used. Examples: rmi, http, ibis, ... By default it is rmi.
-port portNumber is the port number where the P2P Service will listen. By default it is 2410
-s Peer ... specify addresses of peers which are used to join the P2P infrastructure. Example:
rmi://applepie.proactive.org:8080
-f PeersListFile same of -s but peers are specified in file ServerListFile. One per line.
More options:
-noa NOA in number of host. NOA is the minimal number of peers one peer needs to know to keep up the infrastructure. By default, its value is 10 peers.
-ttu TTU is in minutes. Each peer sends a heart beat to its acquaintances. By default, its value is 1 minute.
-ttl TTL is in hop. TTL represents live time messages in hops of JVMs (node). By default, its value is 5 hops.
-capacity Number_of_Messages is the maximum memory size to stock message UUID. Default value is 1000 messages UUID.
-exploring Percentage is the percentage of agree response when a peer is looking for acquaintances. By default, its value is 66%.
-booking Time in ms it takes while booking a shared node. It's the maximum time in milliseconds to create at least an active object in the shared node. After this time, and if no active objects are created, the shared node will leave and the peer which gets this shared node will be no longer be able to use it. Default is 3 minutes.
-node_acq Time in milliseconds which is the timeout for node acquisition. The default value is 3 minutes.
-lookup Time is the lookup frequency in milliseconds for re-asking nodes. By default, it's value is 30 seconds.
-no_multi_proc_nodes to share only a node. Otherwise, 1 node by CPU that means the p2p service which is running on a bi-pro will share 2 nodes. By default, 1 shared node for 1 CPU.
-xml_path to share nodes from a XML deployment descriptor file. This option takes a file path. By default, no descriptors are specified. That means the P2P Service shares only one local node or one local node by CPUs.
All arguments are optional.
Comment: With the UNIX version of the startP2PService script, the P2P service is persistent and runs like a UNIX nice process. If the JVMs that are running the P2P service stop (for a Java exception) the script re-starts a new one.
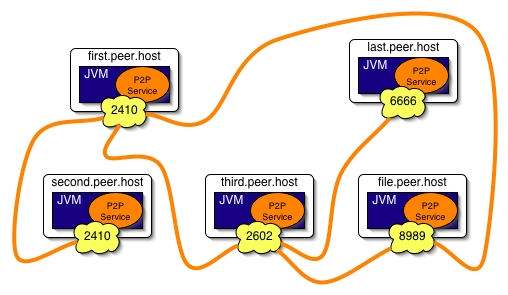
In this illustration, we will explain how to start a first peer and then how new peers can create a P2P network with the first one.
Start the first peer with rmi protocol and listening on port 2410:
first.peer.host$startP2PService.sh -acq rmi -port 2410
Now, start new peers and connect them to the first peer to create a tiny P2P network:
second.peer.host$startP2PService.sh -acq rmi -port 2410 -s rmi://first.peer.host third.peer.host$startP2PService.sh -acq rmi -port 2602 -s rmi://first.peer.host
You could specify a different port number for each peer.
Use a file to specify the addresses of peers:
The file hosts.file:
rmi://first.peer.host:2410 rmi://third.peer.host:2602
file.peer.host$startP2PService.sh -acq rmi -port 8989 -f hosts.file
Lastly, a new peer joins the P2P network:
last.peer.host$startP2PService.sh -acq rmi -port 6666 -s rmi://third.peer.host:2410
The daemon aims to use computers in Peer-to-Peer computations. There will be a Java virtual machine sleeping on your computer and waking up at scheduled times to get some work done.
By default, the JVM is scheduled to wake up during the weekend and during the night. Next, we will explain how to change the schedule. The JVM is running with the lowest priority.
UNIX
Go to the directory: ProActive/compile and run this command:
$ ./build daemon
Before compiling you should change some parameters like the daemon user or the port in the file:
ProActive/p2p/src/common/proactivep2p.h
Ask your system administrator to add the daemon in a crontab or init.d. The process to run is located here:
ProActive/p2p/build/proactivep2p
Microsoft Windows
To compile daemon source (in c++), we don't provide any automatic script, you have to do it yourself. All sources for Windows are in the directory: ProActive/p2p/src/windows. If you use Microsoft Visual Studio, you can find in the src directory the Microsoft VS project files.
After that you are ready to install the daemon with Windows, you just have to run this script:
C:>ProActive\scripts\windows\p2p\Service\install.bat
To remove the daemon:
C:>ProActive\scripts\windows\p2p\Service\remove.bat
Comment: By default the port number of the daemon is 9015.
The daemon is configured with XML files in the ProActive/p2p/config/ directory. To find the correct configuration file, the daemon will first try with a host dependent file: config/proactivep2p.${HOST}.xml for example: config/proactivep2p.camel.inria.fr.xml if the daemon is running on the host named camel.inria.fr.
If this host specific file is not found, the daemon will load config/proactivep2p.xml. This mechanism can be useful to setup a default configuration and have a specific configuration for some hosts.
The reference is the XML Schema called proactivep2p.xsd, shown in Example C.34, “P2P configuration: proactivep2p.xsd”. For those not fluent in XML Schema, here is a description of all markup tags
The root element in <configFile> it contains one or many <p2pconfig> . This latter element can start with a <loadconfig path='path/to/xml'/> it will include the designated XML file. After these file inclusions, you can with <host name='name.domain'> specify which hosts are concerned by the configuration. Then there can be a <configForHost> element containing a configuration for the selected hosts and/or a <default> element if no suitable configuration was already found.
Bear in mind that the XML parser sees a lot of configuration and the first that matches is used and the parsing is finished. This means that the elements we have just seen are tightly linked together. For example if an XML file designated by a <loadconfig> contains a <default> element, then after this file no other element will be evaluated. This is because either a configuration was already found so the parsing stops, or no configuration matched and the <default> does, so the parsing ends.
The proper configuration is contained in a <configForHost> or <default> element. It consists of the scheduled times for work and the hosts where we register ourselves. Here is an example:
<periods>
<period>
<start day='monday' hour='18'
minute='0'/>
<end day='tuesday' hour='6'
minute='0'/>
</period>
<period>
<start day='saturday' hour='0'
minute='0'/>
<end day='monday' hour='6'
minute='0'/>
</period>
</periods>
<register>
<registry url='trinidad.inria.fr'/>
<registry url='amda.inria.fr'/>
<registry url='tranquility.inria.fr'/>
<registry url='psychoquack.inria.fr'/>
</register>In this example we clearly see that the JVM will wake up Monday evening and shut down Tuesday morning. It will also work during the weekend. In the <register> part we put the URL in which we will register ourselves, in the example we used the short form which is equivalent to rmi://host:9301.
The following commands only work with UNIX friendly systems.
Stop the JVM: This command will stop the JVM and will restart it at the next scheduled time, which is the day after:
$ProActive/p2p/build/p2pctl stop [hostname]
Kill the daemon:
$ProActive/p2p/build/p2pctl killdaemon [hostname]
Restart the daemon:
$ProActive/p2p/build/p2pctl restart [hostname]
Test the daemon:
$ProActive/p2p/build/p2pctl alive [hostname]
Flush the daemon logs:
$ProActive/p2p/build/p2pctl flush [hostname]
hostname is the name of the remote host which the daemon command is sent to. This parameter is optional, if the host name is not specified the command is executed on the local host.
Under Windows you could use some littles scripts in ProActive//script/windows/p2p/JVM to do that.
All daemon logs are written in a file. All logs are available in:
ProActive/p2p/build/logs/hostname
You can customize some P2P settings such as:
nodesAsked is the number of nodes you want from the P2P infrastructure. Setting MAX as value is equivalent to an infinite number of nodes. This attribute is required.
acq is the communication protocol that's used to communicate with this P2P Service. All ProActive communication protocols are supported: rmi, http, etc. Default is rmi.
port represents the port number on which to start the P2P Service. Default is 2410. The port is used by the communication protocol.
The NOA Number Of Acquaintances is the minimal number of peers one peer needs to know to keep up the infrastructure. By default, its value is 10 peers.
The TTU Time To Update each peer sends a heart beat to its acquaintances. By default, its value is 1 minute.
The TTL Time To Live represents messages live time in hops of JVMs (node). By default, its value is 5 hops.
multi_proc_nodes is a boolean (use true or false) attribute. When its value is true the P2P service will share 1 node by CPU, if not only one node is shared. By default, its value is true, i.e. 1 node / CPU.
xml_path is used with a XML deployment descriptor path. The P2P Service shares nodes which are deployed by the descriptor. No default nodes are shared.
booking_nodes is a boolean value (true or false). During asking nodes processs there is a timeout, booking timeout is used for obtaining nodes. That means if no active objects are created before the end of the timeout, the node will be free and no longer shared. To avoid the booking timeout, put this attribute at true, obtained nodes will be permanently booked for you. By default, its value is false. See below, for more information about the booking timeout.
With elements acq and port, if a P2P Service is already running with this configuration the descriptor will use this one, if not a new one is started.
In order to get nodes, the peerSet tag will allow you to specify entry point of your P2P Infrastructure.
You can get nodes from the P2P Infrastructure using the ProActive Deployment Descriptor as described above.
In fact you will ask for a certain number of nodes and ProActive will notify a 'listener' (one of your class), every time a new node is available.
ProActiveDescriptor pad = ProActive.getProactiveDescriptor('myP2PXmlDescriptor.xml');
// getting virtual node 'p2pvn' defined in the ProActive Deployement Descriptor
VirtualNode vn = pad.getVirtualNode('p2pvn');
// adding 'this' or anyother class has a listener of the 'NodeCreationEvent'
((VirtualNodeImpl) vn).addNodeCreationEventListener(this);
//activate that virtual node
vn.activate();
As you can see, the class executing this code must implement an interface in order to be notified when a new node is available from the P2P infrastructure.
Basically you will have to implement the interface NodeCreationEventListener that can be found in package org.objectweb.proactive.core.event. For example, this method will be called every time a new host is acquired:
public void nodeCreated(NodeCreationEvent event) { // get the node Node newNode = event.getNode(); // now you can create an active object on your node. }
You should carefully notice that you can be notified at any time, whatever the code you are executing, once you have activated the virtual node.
A short preview of a XML descriptor:
<infrastructure>
<services>
<serviceDefinition id='p2pservice'>
<P2PService nodesAsked='2' acq='rmi'
port='2410' NOA='10' TTU='60000'
TTL='10'>
<peerSet>
<peer>rmi://localhost:3000</peer>
</peerSet>
</P2PService>
</serviceDefinition>
</services>
</infrastructure>
A complete example of file is available, see Example C.35, “P2P configuration: sample_p2p.xml” .
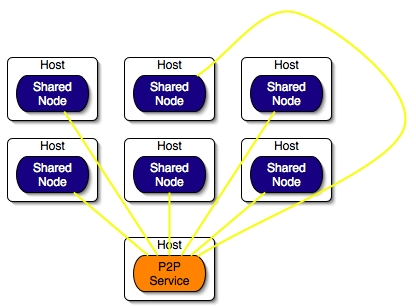
The next figure shows a P2P Service started with a XML deployment descriptor (xml_path attribute). Six nodes are shared on different hosts:
For more information about ProActive XML Deployment Descriptor see the descriptor java doc .
The next little sample of code explains how, from an application, you can start a P2P Service and get nodes:
import org.objectweb.proactive.ProActive; import org.objectweb.proactive.core.ProActiveException; import org.objectweb.proactive.core.mop.ClassNotReifiableException; import org.objectweb.proactive.core.node.Node; import org.objectweb.proactive.core.node.NodeException; import org.objectweb.proactive.core.node.NodeFactory; import org.objectweb.proactive.core.runtime.ProActiveRuntime; import org.objectweb.proactive.core.runtime.RuntimeFactory; import org.objectweb.proactive.p2p.service.P2PService; import org.objectweb.proactive.p2p.service.StartP2PService; import org.objectweb.proactive.p2p.service.node.P2PNodeLookup; ... // This constructor uses a file with address of peers // See the Javadoc to choose different parameters StartP2PService startServiceP2P = new StartP2PService(p2pFile) // Start the P2P Service on the local host startServiceP2P.start(); // Get the reference on the P2P Service P2PService serviceP2P = startServiceP2P.getP2PService(); // By the application's P2P Service ask to the P2P infrastructure // for getting nodes. P2PNodeLookup p2pNodeLookup = p2pService.getNodes(nNodes, virtualNodeName, JobID); // You can migrate the P2P node lookup from the p2p service // to an another node: p2pNodeLookup.moveTo('//localhost/localNode'); // Use method from p2pNodeLookup to get nodes // such as while (! p2pNodeLookup.allArrived()) { Vector arrivedNodes = p2pNodeLookup.getAndRemoveNodes(); // Do something with nodes ... } // Your application ... // End of your program // Free shared nodes p2pNodeLookup.killAllNodes();
Plug technical services (Chapter 26, Technical Service), such as Fault-tolerance schemes or Load Balancing, for each application at the deployment time.
The seminal paper [ CCMPARCO07 ] .
Further research information is available at http://www-sop.inria.fr/oasis/Alexandre.Di_Costanzo/.
© 2001-2007 INRIA Sophia Antipolis All Rights Reserved