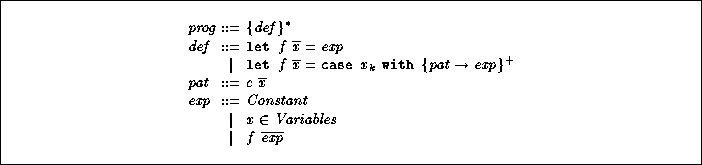To present the basic steps of the FP-to-AG translation in a simple and clear
way, we deliberately restrict ourselves to a sub-class of first order
functional programs![]() , presented in
Figure 2. Notice that nested pattern-matching are not allowed, but
it is easy to split them in several separated functions. Moreover,
if-then-else can be taken into account with Dynamic Attribute
Grammars [30]. We will not develop these points in this article,
but other deforestation formalisms are dealing with similar classes of programs
(cf. HYLO system [26]). The rev and
flat programs given in introduction illustrate our functional language
syntax (Figure 2).
, presented in
Figure 2. Notice that nested pattern-matching are not allowed, but
it is easy to split them in several separated functions. Moreover,
if-then-else can be taken into account with Dynamic Attribute
Grammars [30]. We will not develop these points in this article,
but other deforestation formalisms are dealing with similar classes of programs
(cf. HYLO system [26]). The rev and
flat programs given in introduction illustrate our functional language
syntax (Figure 2).
To bring our attribute grammar notation, presented in Figure 3, closer to functional specifications, algebraic type definitions will be used instead of classical context free grammars [3, 12]. For example, types list and tree are defined as follows:
![]()
A grammar production is represented as a data-type constructor followed by its parameter variables, that is, a pattern (for example: cons head tail).

Figure 3: Attribute grammar notation
Since our transformations take type-checked functional programs as input, this
induces information about the generated attribute grammars. For example, a
distinctive feature of attribute grammars is to characterize two sorts of
attributes: the synthesized ones are computed bottom-up over the
structure and the inherited ones are computed top-down. The sort and the
type of an attribute are directly deduced from the type-checked input
program![]() .
.
Furthermore, the notion of attribute grammar profile is introduced (in
Figure 3, ![]() is the profile of f). It represents
how to call the attribute grammar and allows result and arguments to be
specified. This notion freely extends classical attribute grammars where these
argument specifications were impossible
is the profile of f). It represents
how to call the attribute grammar and allows result and arguments to be
specified. This notion freely extends classical attribute grammars where these
argument specifications were impossible![]() .
.
The occurrence of an attribute a on a pattern variable x is noted x.a. If
an attribute is attached to the constructor of the current pattern, its
occurrence is simply noted a ![]() . For instance,
according to the attribute grammar syntax in Figure 3, the
rev function is defined as follows:
. For instance,
according to the attribute grammar syntax in Figure 3, the
rev function is defined as follows:

In further transformation algorithms, the following notations are used:
|
| Ā: | local definition in an algorithm |
|
| Ā: | a n-tuple |
| x.a = exp | : | semantic rule defining the attribute occurrence x.a |
| : | substitution of x by y | |
|
| : | a set of semantic rules |
|
| : | a pattern with its set of semantic rules |
|
| : | transformation from A into B according to the local context |
|
| Ā: | a term containing e as a sub-expression. |