Our aim is to find a real-time collision detection method that allows us to take the whole tool into account instead of just considering its extremity. Detecting a collision between two objects basically consists in testing if the volume of the first one (ie. the tool, which has quite a simple shape), intersects the second one. This process is very close to a scene visualization process: in the latter, the user specifies a viewing volume (or frustum), characterized by the location, orientation and projection of a camera; then, the first part of the visualization process consists in clipping all the scene polygons according to this frustum, in order to render only the intersection between the scene objects and the viewing volume. Specialized graphics hardware usually performs this very efficiently.
Thus, the basic idea of our method is to specify a viewing volume corresponding to the tool shape (or alternatively to the volume covered by the tool between two consecutive time steps). We use the hardware to ``render'' the main object (the organ) relatively to this ``camera''. If nothing is visible, then there is no collision. Otherwise we can get the part of the object that the tool intersects.
Several problems occur: firstly, the tool shape is not as simple as usual viewing volumes. Secondly, we don't want to get an image, but we need meaningful information instead. More precisely, we would like to know which object faces are involves in a collision, and at which coordinates. The OpenGLgraphic library provides features that will allow us to model our problem in these terms. We review them in the next sections.
The most common frustum provided by OpenGLare those defined by an orthographic camera and by a perspective camera. In both cases, viewing volumes are hexahedra, respectively a box and a truncated pyramid, specified by six scalar values (see Figure 2).
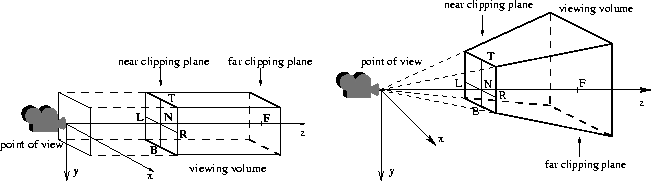 |
Moreover, the user may add extra clipping planes for further restricting of the viewing volume, using glClipPlane(). All the versions of OpenGLcan treat at least six extra planes, so the viewing volume can be set to a dodecahedron. However, we must keep in mind that efficiency decreases each time an extra clipping plane is added.
The regular visualization process is divided into a geometrical part and a rasterization part. The geometrical part converts all the coordinates of the scene polygons into the camera coordinate system, clips all the faces relatively to the viewing volume, and achieves the orthographic or the perspective projection in order to get screen coordinates. The rasterization part transforms the remaining 2D triangles into pixels, taking care of the depth by using a Z-buffer in addition to the color buffer.
Computing the first part of the process is sufficient for the applications that only require meaningful informations about visible parts of the scene. A typical example is the picking feature in 3D interaction: a 3D modeler needs to know which object or face is just below the mouse, in order to operate on it when the user clicks. If several objects project on the same pixel, it can be useful to know each of them. In 3D paint systems, the program rather needs to know the texture coordinate corresponding to the pixel which is below the mouse.
OpenGLprovides two picking modes, that may be selected alternatively to the usual rendering mode GL_RENDER thanks to the function glRenderMode(). For these two modes, no rasterization is performed. Moreover, costly operations such as lighting are usually turned off. The picking modes differ from the informations they give back: