The aim of this page is to give the basic information to extend the drag-and-drop algorithm to address the mathematical domain of your choice. We describe the basic elements of behavior descriptions drag-and-drop rules. In other pages, we describes the tools provided to add new rules: an interactive editor and an automatic tool to construct the natural rules for some general classes of theorems.
When a drag-and-drop action is requested, the algorithm determines the position where the action is requested from the two positions where the mouse is depressed and released (with the standard settings, these positions appear in pink and green). These positions gives a tree structure which is successively matched against the rules given in a collection. When this matching succeeds, a command is generated by completing a command template coming from the rule with data coming from the designated position. When necessary, a Coq Pattern command is added in front of the command, to make sure that the rewriting will occur only at the position designated by the user. To understand how the matching happens, you need to know a little more about the structure of formulas in CtCoq.
Each drag-and-drop behavior rule comes with the following kinds of data:
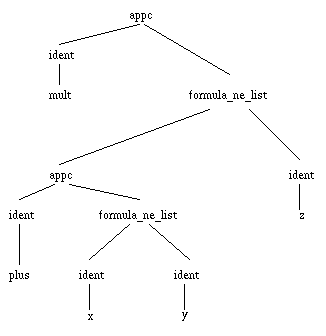
The formulas manipulated when performing rewriting are mostly restricted to identifiers and functions applied to formulas. Thus, almost all the structures we shall consider in this presentation we be composed with only two basic patterns: identifiers (operator ident) and applications of functions to non empty lists of arguments (operators appc and formula_ne_list). For instance, the expression "(x + y) * z" will be represented by the tree-like structure given in figure 1:
Figure 1. The tree structure of a mathematical expression
Trees with appc as head operator always have two children, where the first one is the function and the second is the list of arguments. Trees with formula_ne_list as head operator can have an arbitrary number of children, but at least one. Trees with ident as head operator do not have any children, they simply carry a value which is a name.
The positions in tree structures are designated using paths, which are lists of integers. The first integer represent the rank of the branch you should follow to go from the root of the term towards the designated position. The rest of the list can be interpreted similarly, but taking the corresponding subterm as the new root. For instance, the identifier "x" is designated by the path "(2 1 2 1)", while the identifier "plus" is designated by the path "(2 1 1)".
Patterns are constructed like trees, except that they use an extra kind of operators meta to represent variables that can be instanciated with arbitrary tree structures (meta stands for "meta-variables" to distinguish these from the variables occurring in mathematical formulas, represented by the operator "ident"). For instance, figure 2 gives a pattern that can match the expression "(x + y)" (the sub-expression at path "(2 1)" in our example tree).

Figure 2. A tree pattern
The meta-variables in patterns have names and these names are significant. A meta-variable with the same name occurring at two different positions indicates that the corresponding subterms of the matched tree have to be equal. The names will also be significant to designate data from the matched tree, when transferring data to the constructed command.
For the drag-and-drop rule to be eligible, it is necessary that an ancestor of the positions given by the user "match" the patterns and positions given in the rule.
From the two positions given by the movement of the user, the algorithm then determines the least common ancestor, by looking only at the paths, for instance if the two positions are "x" and "y", with paths "(2 1 2 1)" "(2 1 2 2)" the least common ancestor is also designated by the longest common prefix of the two paths : "(2 1 2)". Very often, the expression that is matched against the pattern given in the drag-and-drop behavior rule is not the least common ancestor, but one of its ancestors, at a distance also recorded in the rule. This is necessary to recognize movements that are not "wide" enough to make sure that the least common ancestor is an ancestor for all the relevant data. For instance, suppose we want to provoke a rewriting with the commutativity of addition when dragging from "x" to "y" in the expression "x + y". In this case, the least common ancestor to "x" and "y" is the structure with "formula_ne_list" as head operator, the structure designated by the path "(2 1 2)", but this structure does not contain the "plus" operator.
Once the pattern matching between the designated position and the rule's pattern succeeds, it is necessary to check that the two positions given by the user's movement also match the initial and last position given in the rule. For positions, matching is represented by the prefix ordering on paths. If "p1" is the path that designates the position where the user pushed down the button of the mouse, and "p2" is the path that designates the position where the user released the mouse, if "Pi" and "Pf" are the paths recorded in the rule as initial path and final path, and if "p" is the path to the common ancestor that is matched against the rule pattern, then the algorithms checks that "p + Pi" is a prefix of "p1" and "p + Pf" is a prefix of "p2".
The command pattern is just another pattern like the one used to match the designated position. Here, meta-variable names are used to designate the expressions found in the designated position. For instance, if the user moved the mouse from "x" to "y" in figure 1 and the rule associates the pattern given in figure 2 and the pattern command given in figure 3, then the generated command will be "Rewrite (plus_commutative x y)".
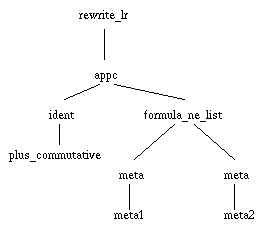
Figure 3. A command pattern.
To complete the command pattern, the tool simply applies to this pattern a substitution obtained during the matching phase. In this respect, the name of variables as they appear in the formula pattern and in the command pattern is very significant.
We provide a procedure to add new theorems in the database. To use this procedure, select a theorem in the Theorems window or a Library window, type Escape-x, then at the prompt type the string "add-in-dad-patterns". This procedure recognizes only some classes of theorems, and associates a specific behavior to each class. Here is a description of the classes: