|
|
On rappelle que l’on dénombre un total d’environ 62 millions de requêtes sur 3 mois (cf. tableau 2.1 p. 406), dont dix millions de requêtes distinctes pour la procédure Nett1 et 8,6 millions pour la procédure Nett2.
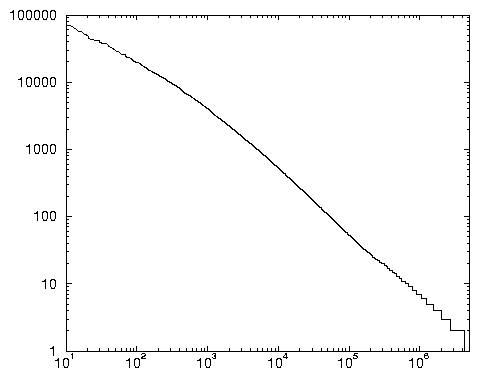
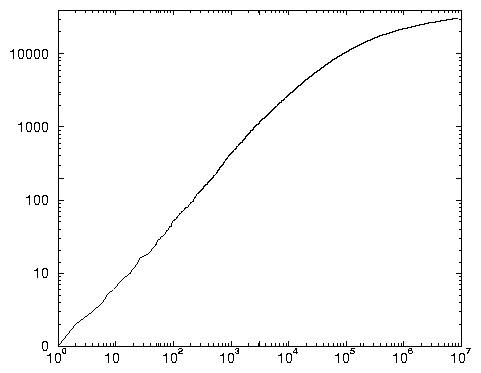
Les deux procédures donnent les mêmes résultats en matière de distribution rang-fréquence des requêtes. Aussi le graphique 2.5 se limite-t-il aux résultats de la procédure Nett2, et pour les requêtes dont les rangs sont compris entre 10 et 4 500 000 30.
|
|
Ce graphique, qui met en évidence une exceptionnelle conformité avec la loi de Zipf, appelle divers commentaires. Tout d’abord, les requêtes semblent distribuées suivant trois régimes: Les 1000 premières, signalées par une portion de graphe en zig-zag dans la représentation log-log. Leur fréquence s’étale entre 284 462 (sexe, seule à dépasser 100 000 occurrences) et 4042 (dijon). Celles de rang supérieur à 300 000, signalées par une portion de graphe en escalier, preuve qu’elles sont très nombreuses à apparaître peu fréquemment (entre une et 20 occurrences, la 300 001e étant « hypnose contre harcelement »). Mais ces requêtes constituent plus de 96 % des requêtes distinctes et pèsent 37 % des occurrences du total 31. Ces importantes proportions prouvent, encore plus qu’avec les mots, que les évènements rares ne peuvent être éliminés de l’étude, même si leur masse les rendra particulièrement difficiles à analyser.
Enfin, le régime intermédiaire des requêtes de rangs compris entre 1001 et 300 000, qui se distingue par une remarquable linéarité de la courbe. Nous remarquons que la pente des requêtes de ce second groupe est la même que celle des requêtes de fréquences très faibles. Sa mesure précise amène à proposer les deux équations symétriques suivantes:
|
Ainsi, les requêtes, certes simplifiées, ont un comportement inattendu: que ce soit avec la première ou la seconde procédure, elles obéissent à des lois de puissance mieux que ne le font les mots du lexique 32.
La comparaison des deux tableaux 2.8 et 2.9 rappelle que les deux procédures donnent des résultats équivalents, contrairement aux mots, et on remarque un réel tassement de la distribution cumulée par rapport à celle du vocabulaire: les 1000 premières requêtes ne « pèsent » qu’environ 17 % du total. Et, quelle que soit la méthode employée, il faut atteindre le rang 100 000 pour obtenir des résultats analogues aux mille premiers mots. Par exemple, avec la procédure Nett2, les requêtes apparaissant au plus 20 fois (soit en moyenne une fois tous les quatre jours 33, ont un poids total conséquent, qui dépasse celui des 10 000 premières requêtes: ici, nous ne pouvons nier l’importance des requêtes rares.
|
|
|
|
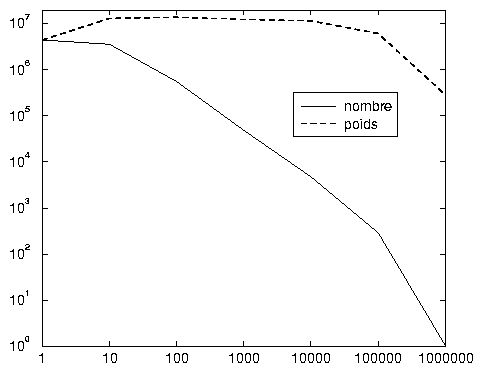
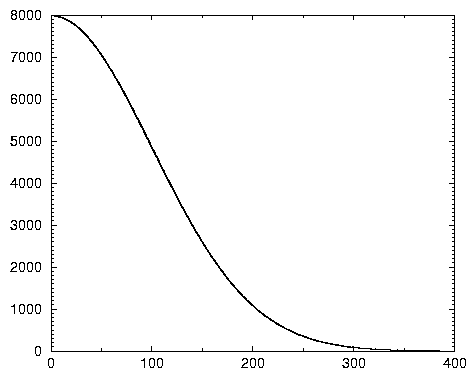
Le graphique 2.6 synthétise ces résultats en mettant en évidence le problème méthodologique que l’on pressent: comment créer un échantillon significatif de ces requêtes, puisque les plages intermédiaires ont toutes des poids analogues? La sagesse inciterait à accepter toutes les requêtes apparaissant entre 2 et 10 000 fois, ce qui correspond hélas à 4 179 698 de requêtes distinctes, pour un poids total de 50 909 962. Se limiter aux requêtes apparaissant entre 11 et 10 000 fois réduit le nombre de requêtes distinctes à 612 844 et leur poids à 37 822 325.
|
|
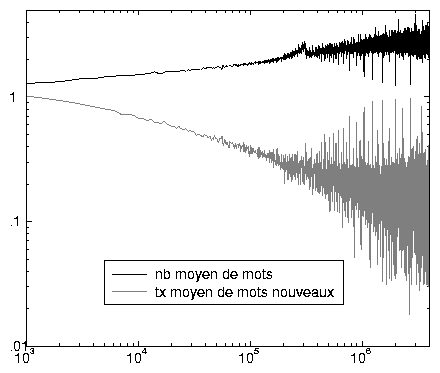
Ce nombre de mots des requêtes s’accroît jusqu’à celles de rang 300 000 (2,8 mots en moyenne) puis « chute momentanément » et reprend son accroissement tout en restant souvent au dessus de 2. Cependant, à partir des requêtes de rang 600 000, on constate de grandes variations de la moyenne, qui parfois descend à 1,2 mots et peut s’élever jusqu’à 4 ou 5, et à partir du rang 2 000 000, cette moyenne dépasse souvent 3 mots.
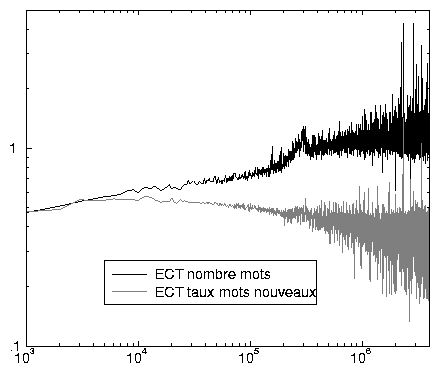
On mesure bien la fiabilité de cette mesure moyenne en considérant l’écart-type (graphique 2.8), particulièrement faible pour les requêtes majoritaires (0,47), dépassant souvent 1 à partir des requêtes de rang supérieur à 300 000: nous sommes assurés de ne rencontrer que des requêtes d’un ou deux mots parmi les 50 000 premières requêtes 35, alors que les requêtes de 4 mots ou plus sont communes pour les rangs dépassant 300 000. À ce seuil, nous retrouvons la brutale variation remarquée dans le graphique 2.7; à partir du rang 1 000 000, moyennes et écarts-types varient grandement.
|
|
De même, le taux de mots nouveaux 36 suit une décroissance quasi logarithmique au début, et retrouve parfois une croissance rapide pour les rangs dépassant 250 000 (environ 27 % de mots nouveaux pour ce rang), en s’approchant parfois de 100 % pour les requêtes de rang supérieur à 1 000 000. Comme pour le nombre moyen de mots, la courbe de l’écart-type permet de confirmer ces analyses réalisées à partir de la moyenne: au-delà du rang 1 000 000, les variations de taille des requêtes peuvent être très importantes.
Nous pressentons donc que les requêtes rares sont celles qui génèrent la richesse lexicale du vocabulaire, celle-ci devant être entendue comme combinaison de mots mal orthographiés, de noms propres et de mots rares qui ne renvoient pas au vocabulaire de la consommation courante, comme par exemple ceux qui sont utilisés dans les requêtes à caractère intellectuel.
|
|
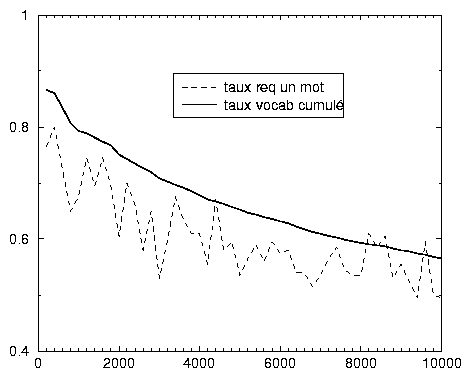
L’indigence du vocabulaire des requêtes majoritaires surprend, mais est confirmée par le graphique 2.9, qui donne, pour les 10 000 premières requêtes regroupées par paquets de 200, le pourcentage de requêtes d’un seul mot, et la taille du vocabulaire cumulé, divisée par le nombre de mots des requêtes qui le génèrent. Nous voyons combien pèsent les requêtes d’un seul mot (toujours plus de 50 % des requêtes, et souvent plus de 70 % pour les 2000 premières), et surtout comment ces requêtes majoritaires contribuent peu à l’enrichissement du vocabulaire: les 10 000 premières, composées au total de 14 335 mots (soit donc 1,4 mots par requête en moyenne), n’en contiennent que 8105 distincts (ce qui explique le taux de 56,5 %, pour ce rang 10 000). Or, ce vocabulaire réduit pèse lourd dans le total des occurrences des mots, puisqu’un mot dans une requête apparaît au moins autant de fois qu’elle 37. En fait, les 1285 mots des 1000 premières requêtes réalisent un total d’occurrences de 13 246 600, impressionnant pour le publicitaire pressé 38, alors que l’internaute qui les adresse au moteur de recherche est quasiment assuré de ne pas obtenir les informations qu’il espère, d’une part parce que sa requête n’est pas assez précise, d’autre part parce que le moteur propose trop de réponses.
En fait, les requêtes majoritaires n’ont pas plus de pertinence que les mots majoritaires, car elles sont très souvent composées d’un seul mot, nécessairement banal. Elles sont tout peu informatives, pour l’analyste comme pour l’internaute: ce dernier risque fort d’avoir du mal à faire son choix parmi les réponses offertes si sa requête se limite à des expressions du type horoscope (rg. 9, 73 071 occ.), corse (rg. 80, 22 682 occ.), islam (rg. 415, 7786 occ.), maison (rg. 550, 6349 occ.), broderie (rg. 671, 5468 occ.), « loterie gratuite » (rg. 910, 4299 occ.), ou encore restaurants (rg. 992, 4059 occ.).
En consultant la liste des 1000 premières requêtes (paragraphe 4.1 de l’annexe, p. 703), on se convaincra de la quasi impossibilité d’interpréter ces requêtes majoritaires. À la limite, elles témoignent d’une incompréhension du fonctionnement des moteurs de recherche —ou d’un usage ludique, non motivé de ces moteurs— par une partie de la population, qu’on ne peut évaluer, puisque ces statistiques proposent des agrégations brutales: une requête n’est qu’un fragment de session. Là encore, tout raisonnement fondé sur des énonciations agrégées et qui apparaissent majoritaires, sans qu’on se soit donné la peine de vérifier qui les produisait ni comment elles étaient reformulées, n’a aucune validité.
En revanche, nous pouvons à nouveau tenter d’estimer la variété des termes employés à partir de ces requêtes. La faible présence de mots courants, comme flexibilité, ou refus 39 est étonnante. Pour le premier, la fréquence de la première requête le contenant est 343 (rang 15 553). Pour refus, il faut attendre la requête « refus vente », de rang 94 705 (56 occ.). Pour des mots comme comestible, désarmement, malfaçon, perpendiculaire, dont la fréquence dans le lexique est déjà rare, de l’ordre de 100, la fréquence de la première requête les contenant varie entre 46 (« fleurs comestibles », rang 114 361) et 13 (« ethique desarmement », rang 412 185). D’autres mots, comme sophistiqué/e, apparaissent en tout 13 fois (« maquillage sophistique », 4 occ., rang 1 790 689).
Ces exemples confirment l’intuition suivant laquelle le vocabulaire se construit avec les requêtes à faibles fréquences: à se focaliser sur les requêtes majoritaires, on construit une représentation simplifiée, voire méprisante, des internautes.
Pour vérifier cette impression, nous avons réalisé un test à partir du dictionnaire des 39 501 mots courants (ni verbes, ni noms propres) du dictionnaire orthographique de LATEX constitué par Christophe Pythoud 40, qui a été légèrement modifié pour, d’une part, intégrer les mots masculins (la vedette de ce dictionnaire est le féminin), et, d’autre part, obtenir une graphie conforme à la procédure Nett2. Ce dictionnaire contient en définitive 43 422 mots, dont les noms communs et les adjectifs au singulier (masculin et féminin), ainsi qu’au pluriel si ceux-ci sont complexes 41.
|
|
Le graphique 2.10 montre comment l’ensemble de ces mots est épuisé par les requêtes. Nous montrons que les requêtes majoritaires utilisent une infime fraction du vocabulaire de la langue française traditionnelle. Par exemple, les 10 000 premières requêtes, dont on sait qu’elle sont composées de 8105 mots distincts, n’en contiennent que 2000 du dictionnaire choisi. Mais s’il faut attendre la requête de rang 100 000 pour épuiser le quart de ce dictionnaire (10 000 mots), après, la croissance se maintient, même si elle devient logarithmique: les requêtes très rares, de rang supérieur à 637 104, font apparaître autant de mots du dictionnaire, puisque le total cumulé des mots de son lexique passe de 20 000 à 30 927.
Par exemple, voici quelques mots apparaissant dans les requêtes de rang 100 000 à 101 000: diffuseur (648 occ.) 42, elaboration (1235), empirisme (79), epiphyse (65), ermite (153), felibrige (55), brin (271), filetage (303), fontanelle (61), funerarium (91), garrot (115), glissade (167), histamine (103), huchet (145), irrationnel (145), jais (114), kidnapping (78), lithosphere (102), marinade (220), metastase (367), milice (138), mistigri (67), nougatine (93), pessimisme (436), mineralogique (198), pneumocoque (85), funebre (372).
Les requêtes de rang 1 000 000 à 1 001 000 ne sont pas en reste: grâce à elles sont introduits des mots comme: poigne (27 occ.), exclamation (20), point-virgule (14), cyclostome (11), etatique (46).
Et les requêtes de rang supérieur à 8 000 000 —qui n’apparaissent donc qu’une fois— contribuent elles-aussi à l’accroissement du vocabulaire. On passera sur les mots peu connus comme yttrifere ou zoosemiotique pour insister sur les suivants: anarcho-syndicalisme, stakhanoviste, exterieurement, suburbain, suffisance, implicitement, zygomatique. De tels mots sont des hapax puisqu’ils n’émergent qu’avec des requêtes singulières.
Nous avons donc doublement la preuve (avec le test dictionnairique comme avec ces exemples) que sans les requêtes peu fréquentes ou rares, toute une série de mots de la langue disparaîtraient. Or, ces mots rares (par exemple aux fréquences comprises entre 1 et 100 en trois mois) sont essentiels pour comprendre la diversité des questionnements des internautes. Mais leur coût d’extraction dans un contexte qui fait sens est particulièrement élevé, puisque le nombre de requêtes distinctes est cinq fois plus important que la taille du lexique. Le paradoxe que nous presentions se confirme: pour obtenir des résultats pertinents, il faudra oser oublier les requêtes majoritaires et ne s’intéresser qu’aux requêtes rares, complexes, et difficiles à extraire.
Des acronymes d’institutions ou de formations françaises, comme anpe (83 937 occ. au total), bts (76 076), dess (50 173), iut (39 028), iup (32 125), apec (27 908), insee (19 548), iufm (18 773), snes (17 422), cpam (12 481), dea (12 034), hlm (10 293), deug (9023), afpa (8938), capes (8651), smic (5524), cadremploi (5160), chu (5138). On découvre de multiples autres abrévations (pmu, btp, sci, tv, fm, 4x4, tgv, mst, sarl, etc.), d’autres connecteurs (dans, aux, and, sous, etc.), des prénoms, des mots étrangers (sex, free, new, etc.); des noms d’entreprises, françaises ou étrangères: sncf (85 628 occ.), ratp (30 303), tf1 (37 498), fnac (37 401), sagem (36 121), alcatel (31 658), michelin (31 497), degriftour (25 976), bnp (13 539), danone (5810), oreal (5387), aom (5059), axa (5047). Et parmi ceux-ci, nombre de marques et de noms d’automobiles: renault (58 930), bmw (30 740), yamaha (27 614), ferrari (18 778), clio (11949), volkswagen (10 511), 206 (10 062), etc.
Bien sûr des noms d’« artistes » contemporains, et un nombre important de mots touchant à l’informatique et à l’internet. Nous oublierons ici les noms de logiciels, d’entreprises informatiques, de composants téléphoniques, pour ne conserver que les plus connus des protocoles et des formats de fichiers: web (94 278 occ. au total), warez (75 377), download (55 381), http (53 075), linux (46 338), gif (42 578), napster (33 512), javascript (26 976), freeware (26 429), mpeg (24 955), html (23 801), hack (23 155), ftp (21 820), ip (19 460), php (17 279), asp (15 170), unix (14 385), usb (13 314), zip (11 750), icq (11 434), sql (11 230), password (10 458), pdf (10 044), gnutella (8422), irc (8031), intranet (7676), firewall (7082), proxy (6832), routeur (6263), mp4 (5445), scsi (5268), etc.
Notre but n’est pas de faire une liste à la Prévert, mais de mettre en évidence la variété d’un vocabulaire fort usité: ces mots, acronymes, etc., d’origine française ou non, sont souvent connus de tous, et il est fort possible qu’en quelques décennies, notre vocabulaire courant ait doublé du fait de leur multiplication. Mais cela signifie que les références classiques au sujet du vocabulaire (les 22 000 mots de l’œuvre de Victor Hugo, les 1500 mots du Français fondamental) sous-estiment le nombre de mots que nous avons en tête, même si on les retrouve peu dans notre langue écrite. Et pourtant! Il est clair que si nous faisions l’étude de toutes les documentations imprimées, nous découvririons un lexique très important, de l’ordre de plusieurs centaines de milliers de mots.
L’étude du lexique, abordée par celle des requêtes, met donc en évidence un Français contemporain bien plus souple et plus varié que celui qui sert de référence dans notre langue écrite. Ce sera un des aspects positifs d’un tel travail que de rappeler ce fait: la multiplication des mots techniques et la grande extension des « noms propres » pose surtout des questions de type linguistique. Le seul intérêt de ces requêtes fréquemment saisies est de nous faire découvrir une nouvelle langue vivante, et pourtant écrite.
Nous avons démontré que les requêtes fréquentes contiennent des mots qui ne sont pas dans les dictionnaires, et que si on recherche de tels mots, il faut alors fouiller les requêtes rares. Entreprise longue et coûteuse. Par ailleurs, il apparaît que les requêtes fréquentes, souvent composées d’un seul mot, banal et polysémique, ne sont pas interprétables. Par exemple, la requête « paris » apparaît 25 496 fois. C’est beaucoup, même si certains pourraient prétendre que cela reste peu au regard du total d’occurrences du mot paris (529 294); pour la requête « bmw », c’est l’inverse qui se produit: recensée 10 478 fois (rang 269), cette brève requête constitue à elle seule 30 % des cas d’apparition du mot bmw. Pour savoir si les internautes s’intéressent aux automobiles ou aux motocyclettes, il faut repérer la seconde requête contenant ce mot (rang 5732: « bmw m3 »), et la troisième (rang 11 061: « moto bmw »). Si l’on se limite aux 10 000 premières requêtes, on perd donc la référence aux deux-roues. De même pour la requête « firewall », qui apparaît 3201 fois (rang 1279), quand dans 45 % des cas, le mot et la requête se confondent. Or, la seconde apparition de ce mot apparaît dans la requête de rang... 36 274 (« firewall linux », 147 occ.), ce qui peut donner à penser soudain que le monde Linux est peut-être moins marginalisé qu’il n’y paraît au sein des visiteurs de Goosta. Mais l’enquêteur qui désire obtenir un panorama des pratiques et des centres d’intérêt des internautes à l’aide des seules 1000 ou 10 000 premières requêtes, doit témoigner, non pas de compétences en sciences humaines, mais d’un réel sens de la divination.
Ce n’est que grâce à une série de raccourcis, d’analogies, faisant appel à une sous-culture linguistique, sociologique et psychologique que l’on peut prétendre affirmer quoi que ce soit sur les « internautes » à partir des requêtes majoritaires. Or, la multiplication de faux raisonnements, et d’implicites est proprement effarante chez la majorité des personnes manifestant un quelconque intérêt pour les requêtes des moteurs de recherche. Ces analyses expéditives ne se rencontrent pas seulement dans les discours, privés ou médiatisés, mais aussi dans des articles à vocation scientifique. Pour mesurer à quel point un mélange de marketing, de pseudo-sociologie, et bien sûr, de présumée cognition tient lieu de démarche scientifique chez les consultants, on pourra se référer à l’article de Stefana Broadbent et Francesco Cara publié à l’occasion du colloque virtuel organisé par la bibliothèque publique d’information (BPI) du musée Georges Pompidou 44.
Reste un autre errement méthodologique, relatif à une autre discipline mal comprise: la statistique. Tout d’abord, l’idée —fortement répandue— que toute distribution statistique suit une loi de Gauss. Quand une telle situation se produit, le phénomène majoritaire correspond au « phénomène moyen », et les autres, s’ils ont un minimum d’importance, se distribuent autour de ce phénomène central. Il est fort possible que l’intérêt pour les premiers mots ou requêtes soit induit par l’idée (fausse, nous l’avons vu) que les distributions de ces objets linguistiques obéiraient à la loi de Gauss: le mode définirait la moyenne, donc la norme.
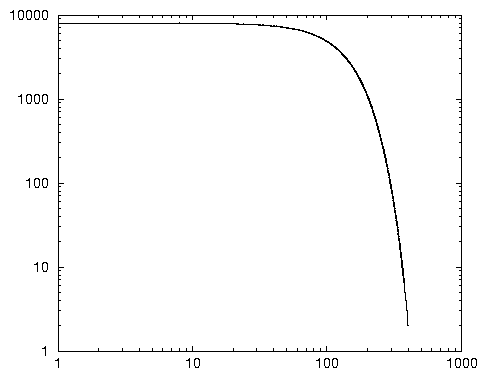
Dans le même registre, on pourrait aussi expliquer le désintérêt pour les requêtes marginales. Un corollaire de notre loi « universelle » est que la somme des phénomènes rares est négligeable (courte queue de distribution). Dans le cas d’une variable qui suit une loi normale centrée réduite, le taux d’individus présentant une valeur supérieure à 3 est ridicule: 0,3 % environ. Il s’ensuit que l’on peut alors oublier les phénomènes dont les fréquences sont inférieures à 100 fois la fréquence maximale 45 (cf. le double graphique 2.11).
En adaptant ce principe aux requêtes 46, sachant que la première apparaît 284 462 fois, on pourrait négliger sans risque aucun les requêtes apparaissant moins de 2850 fois, et donc celles de rang supérieur à 1500. Nous avons mis en évidence les dangers induits par de tels raisonnements 47.
|
|
Mais ce n’est pas tout. La dernière erreur consiste à penser que tout échantillon d’une variable aléatoire quelconque finit par avoir un comportement gaussien (théorème de limite centrale). Et donc, même s’il est faux dans son acception stricte, le raisonnement précédent finirait par être valide. Or, ce théorème ne peut s’appliquer ici, car la loi théorique n’a pas de variance 48.
Ces résultats mettent bien en valeur les vices et les vertus de l’interdisciplinarité: il est dangereux d’appliquer des connaissances mal assimilées en linguistique, en sociologie, et en statistique: les pratiques linguistiques et intellectuelles ne se mesurent pas comme la taille ou le poids. En allant trop vite en besogne, on sous-estime la curiosité, l’intelligence et la diversité culturelle des personnes que l’on étudie. En revanche, on comprend bien comment des comptages sur des mots et des lignes, complétés par des tableaux et des graphiques qui les synthétisent, invitent à décrire une liste, à élaborer d’autres outils pour en affiner l’analyse, en même temps qu’ils font voler en éclats les préjugés consécutifs au refus de penser cette liste-texte comme un objet d’écriture avant toute chose.