| Previous : Sampling the densities Next : The MCMCML estimation algorithm |
|
|
auxiliary variable b, auxiliary images Bx, By (gradients w.r.t. x and y)
and the law of X knowing Bx, By is Gaussian
the processing is independent of the neighbourhood size
which provides a fast algorithm for posterior distribution sampling.
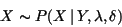
|
|
We first calculate the Fourier transform F[h4 ] and DCT[Y], and W : |
The pixels b of Bx and By are independent : |
The distribution of X with known B is Gaussian because |
|
|
 |
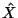 |
|
|
|
|
|
|
  |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
  |
|
|
|
|
|
|
|
 |
|
|
|
|
|
![]() Prior distribution
Prior distribution ![]()
|
|
We first calculate the Fourier transform F[h4 ] and W0 : |
The pixels b of Bx and By are independent : |
The distribution of X with a known B is Gaussian because |
|
|
 |
|
|
|
|
|
|
|
  |
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
  |
|
|
|
|
|
|
|
 |
|
|
|
|
|