Stéphane Duval
Elève ingénieur à l’IRESTE
Spécialité S.E.I.I.
|
|
Stéphane Duval Elève ingénieur à l’IRESTE Spécialité S.E.I.I. |
Rapport de stage de fin d’études :
Janvier – Juin 2000
|
Direction : Sabine Moisan |
|
Remerciements.
Je tiens à remercier toute l’équipe d’ORION pour son accueil sympathique et sa bonne humeur durant ces 6 mois.
Je remercie plus particulièrement Sabine Moisan, pour m’avoir encadré et aidé durant ce stage, ainsi que Monique Thonnat.
Je remercie également Alain Boucher et Augustin Lux pour leur aide, leurs conseils précieux en C++ ainsi que leurs patientes réponses à mes questions quotidiennes.
Résumé
Dans le contexte du pilotage de programmes (enchaînement de planification, exécution, évaluation, réparation), les experts ne peuvent pas toujours fournir une connaissance exhaustive. Après exécution et dans le cas d’une mauvaise évaluation, des mécanismes de réparation entrent en jeu. Nous avons cherché, grâce à un module d'apprentissage automatique, à mémoriser les résultats des réparations, pour éviter de refaire le même travail.
De même, dans le but de décharger l’utilisateur final, nous avons travaillé sur un programme de description symbolique de courbes et d’évaluation automatique de résultats. Ainsi, quand les résultats d’une requête sont sous forme de courbes, plutôt que de solliciter l’utilisateur pour juger de leur validité, l’évaluation sera automatisée.
Abstract
In the context of program supervision (planning, execution, evaluation, repair), experts cannot always provide an exhaustive knowledge. After an execution, when the evaluation fails, some repairing mechanisms are used. With an automatic learning program, we have tried to memorise the results of those repair phases, in order to avoid doing the same work several times.
Also, with the aim to help the end-user, we have worked on a program of symbolic description of curves and automatic result evaluation. When the results of a request are expressed with curves, instead of requiring the user for evaluating them, the program automates their evaluation.
Introduction. *
1 Présentation du cadre du stage. *
1.1 L’INRIA. *
1.1.1 L’INRIA – Présentation générale. *
1.1.2 L’INRIA – Historique. *
1.1.3 Les chiffres-clés. *
1.2 L'unité de recherche INRIA Sophia Antipolis. *
1.2.1 Les équipes de l’unité (ou projets d’équipe). *
1.2.2 Thème 3 : Interaction homme-machine, images, données, connaissances. *
1.2.2.1 Généralités. *
1.2.2.2 Les équipes ou (projets d’équipe) du thème. *
1.3 ORION - Environnements intelligents de résolution de problèmes pour des systèmes autonomes. *
1.3.1 Présentation et objectifs généraux. *
1.3.2 Relations internationales et industrielles. *
1.3.3 Responsable scientifique. *
2 Pilotage de programmes. *
2.1 Objectif. *
2.2 Moteur de pilotage. *
3 Présentation du stage. *
4 Gestion du projet. *
5 Programme de description symbolique et d’évaluation de jeux de courbes. *
5.1 Exposé du problème. *
5.1.1 Le sujet. *
5.1.2 Les problèmes. *
5.1.3 Les solutions. *
5.2 Fonctionnement général. *
5.2.1 La segmentation. *
5.2.2 La description symbolique. *
5.3 Quelques précisions sur le code. *
5.3.1 Description succincte des différents fichiers (avant modification). *
5.3.2 Précisions sur quelques méthodes. *
5.3.2.1 Le calcul d’erreur. *
5.3.2.2 La segmentation. *
5.4 Le travail fait. *
5.4.1 Problèmes de portabilité. *
5.4.2 Simplification du code. *
5.4.3 Nouvelle conception. *
5.4.4 Modernisation du code. *
Conclusion. *
6 Programme d'apprentissage automatique. *
6.1 Description de différents types d’apprentissage. *
6.2 Objectif – Spécifications. *
6.2.1 Description d’une règle. *
6.2.1.1 Les prémisses. *
6.2.1.2 Règle d’initialisation – Action. *
6.2.1.3 Règle de choix – Action. *
6.2.2 Description de la trace. *
6.3 Conception. *
6.3.1 La création des nouvelles règles spécifiques. *
6.3.2 La généralisation et la fusion. *
6.3.2.1 La généralisation proprement dite. *
6.3.2.2 La gestion des conflits et la fusion. *
6.4 Réalisation. *
6.5 Tests - Modifications – Améliorations. *
6.5.1 Tests. *
6.5.2 Modifications éventuelles. *
6.5.3 Améliorations. *
7 Bilan. *
Conclusion. *
Références. *
ANNEXES. *
Introduction.
J’ai effectué mon stage de fin d’études de Janvier à Juin 2000 dans l’équipe d’ORION à l’INRIA de Sophia-Antipolis.
Le sujet de ce stage est la conception et la réalisation d'un programme d’apprentissage pour le pilotage de programmes (notamment des programmes de traitement d’images). Ce sujet aborde deux domaines de l’intelligence artificielle, que sont l’utilisation de systèmes à base de connaissances pour le pilotage de programmes, et l’apprentissage.
Je commencerai par présenter le cadre " géographique " et administratif du stage, c’est à dire l’INRIA, pour remonter jusqu’à l’équipe dans laquelle je travaille, ORION. Ensuite, je parlerai du pilotage de programmes, pour en venir à mon sujet. Tout cela présenté, j’entrerai dans les détails du travail que j’ai à faire, c’est à dire la re-ingénierie d’un programme de description symbolique de courbes [3], puis la conception et la réalisation d'un programme d’apprentissage [5], dans le cadre du pilotage [4].
Créé en 1967 à Rocquencourt près de Paris, l'INRIA (Institut national de recherche en informatique et en automatique) est un établissement public à caractère scientifique et technologique (EPST) placé sous la double tutelle du ministère de l'éducation nationale, de la recherche et de la technologie et du ministère de l'économie, des finances et de l'industrie.
Les principales missions de l'INRIA sont (selon le décret du 2 août 1985 portant sur l'organisation et le fonctionnement de l'institut) :
Avec le contrat d'objectifs signé avec l’état en janvier 1995, l'INRIA a confirmé son engagement à mettre l'excellence scientifique de ses chercheurs au service de son environnement national et international afin d'identifier les problèmes posés, de concevoir avec ses partenaires de meilleures solutions et de lancer rapidement ces dernières sur le marché.
Ainsi, l'INRIA est fermement engagé dans le transfert de technologie, soit par les partenariats noués avec des entreprises industrielles, soit par l'intermédiaire de ses sociétés de technologie.
Depuis 1967, l'INRIA a développé son implantation sur le territoire national. Il est désormais présent dans cinq régions :
1967-1972 : les premiers pas de l'IRIA
Sur l’initiative de la Direction générale de la recherche scientifique et technique (DGRST), un groupe de dix personnalités indépendantes, choisies pour leur compétence scientifique ou économique, se réunissait, à la fin de l'année 1964 et courant 1965, sous la présidence du professeur Lelong pour conduire une réflexion sur l'importance des nouvelles techniques du traitement de l'information.
Le mot informatique n'avait pas encore cours ; il devait être proposé à quelque temps de là, mais le rapport que le groupe adressait en février 1966 au Comité consultatif de la recherche scientifique et technique (CCRST) mettait en lumière tous les concepts de base de cette nouvelle science et attirait l'attention sur l'influence décisive qu'elle allait jouer dans tous les domaines d'activités humaines.
Présentées par le CCRST, les propositions contenues dans le rapport des dix experts étaient adoptées dans leur principe, par un comité interministériel sur la recherche scientifique, présidé par G. Pompidou, alors Premier ministre, en 1966. Un peu plus tard, les instances politiques intéressées mettaient en œuvre l'ensemble des mesures connues sous le terme de " Plan Calcul ".
L'Institut de recherche d'informatique et d'automatique, IRIA, créé par le décret 67-722 du 25 août 1967, constituait l'un des organes principaux d'exécution de ce Plan Calcul. L'étendue de ses missions faisait participer l'IRIA à tous les aspects de l'opération. L'institut jouait, en effet, le rôle majeur, aussi bien pour la recherche que pour la formation des hommes et pour la diffusion de la connaissance scientifique et technique.
La période 1967-1972 a constitué une première phase dans la vie de l'IRIA, celle de la création ex-nihilo, l'époque des pionniers, sous la direction du professeur Michel Laudet, avec l'appui du professeur André Lichnerowicz, président du Conseil scientifique. Au cours de cette période, le domaine de Voluceau, laissé vacant par l'OTAN après avoir servi de cantonnement pour le personnel militaire américain, a été transformé en un instrument de recherche et de formation.
1972-1980 : de l'IRIA à l'INRIA
Le 25 février 1972, un conseil interministériel, sur proposition du Comité consultatif de la recherche scientifique et technique (CCRST), confirmait l'IRIA dans ses vocations et arrêtait une série de décisions propres à en amplifier les actions, notamment dans le domaine de la synthèse et orientation de la recherche française en informatique et dans le domaine de l'assistance technique donnée à la pénétration de l'informatique dans toutes les activités d'intérêt national :
Les statuts de l'IRIA ont été partiellement modifiés suivant ces dispositions par le décret 73-338 du 13 mars 1973.
La réforme de structure s'appuyait sur une pièce maîtresse, la création d'un Comité consultatif de la recherche en informatique, le CCRI, chargé d'élaborer les propositions d'une politique nationale de la recherche dans les domaines de l'informatique et de l'automatique. Le décret portant création du CCRI est le 73-130 du 12 février 1973.
Le 8 juin 1972, Michel Laudet, premier directeur de l'institut, passait ses pouvoirs à son successeur André Danzin.
À l'issue du Conseil d'administration du 28 juin 1972 :
Parmi les missions auxiliaires de l'IRIA, intimement liées aux missions principales, on trouvait l'animation et la conduite de projets pilotes ; le premier étant la réalisation d'un réseau permettant l'interconnexion de plusieurs grands centres de calcul (Projet Cyclades).
Dans son action, l'IRIA se souciait non seulement d'accroître le potentiel en chercheurs, mais aussi d'orienter l'implantation des équipes, selon les préoccupations de la Délégation à l'aménagement du territoire (DATAR). Il mettait ainsi à la disposition d'équipes de province, des postes budgétaires de chercheurs, notamment à Rennes. Ces équipes portaient le nom d'équipes associées de l'IRIA.
En 1975, à partir des équipes de Rennes, était créé l'Irisa, laboratoire de recherche associé à l'université de Rennes 1 et au CNRS.
Fin 1979, l'institut se recentre sur sa mission de recherche et de transfert et devient par décret du 27 décembre 1979, l'INRIA (Institut national de recherche en informatique et en automatique), établissement public à caractère administratif sous la tutelle du ministre de l'industrie.
Jacques-Louis Lions en devient le président directeur général.
Parallèlement est créée, par décret du 27 septembre 1979, l'Agence pour le développement de l'informatique qui est chargée, pour ce qui concerne les applications de l'informatique, de mener des expérimentations, des actions de sensibilisation, de formation et de prospection de nouveaux secteurs d'activité concernés. Elle est également chargée d'une mission d'animation et de développement de la recherche publique et privée sur les applications de l'informatique, sur les techniques susceptibles de favoriser leur développement. Cette agence sera supprimée en 1986.
Après 1980 : l'essor de l'INRIA
Depuis les années 80, l'INRIA n'a cessé de se développer.
En 1980, l'unité de recherche de Rennes voit le jour en tant qu'une des composantes de l'Irisa.
En 1982, est créée l'unité de recherche de Sophia Antipolis.
En 1983, Alain Bensoussan devient président directeur général de l'INRIA.
En 1984, est créée l'unité de recherche de Lorraine, conjointement avec l'université de Nancy et le Centre de recherche en informatique de Nancy (Crin) du CNRS.
En 1984, Simulog voit le jour. Il s'agit de la première filiale industrielle de l'INRIA, dans le domaine de l'ingénierie assistée par ordinateur. C'est la première d'une série qui conduira à la création de 19 autres sociétés de technologie issues de l'INRIA.
En 1985, l'INRIA devient établissement public à caractère scientifique et technologique (EPST) placé sous la double tutelle du ministère chargé de la recherche et du ministère chargé de l'industrie.
Le décret 85-831 du 2 août 1985, portant sur l'organisation et le fonctionnement de l'institut, rappelle ses principales missions :
En 1987, l'INRIA célèbre son 20e anniversaire : Alain Bensoussan déclare que la plus grande spécificité de l'institut consiste à obtenir que les résultats de la recherche soient transférés aussi vite que possible dans le secteur économique.
En 1987, la deuxième filiale de l'INRIA, Ilog, chargée de l'industrialisation de produits INRIA en intelligence logicielle, voit le jour.
En 1989, l'INRIA est un des fondateurs du consortium européen Ercim qui regroupe actuellement quatorze organismes de recherche.
En 1990, la troisième filiale industrielle de l'INRIA, O2 Technology, est créée dans le domaine des systèmes de gestion de bases de données orientées objet.
En 1992, l'unité de recherche de Rhône-Alpes voit le jour.
En mars 1994, l'INRIA adopte un plan stratégique visant à définir les principaux axes de la politique générale menée par l'institut.
Le 31 janvier 1995, l'INRIA est le premier organisme de recherche à signer avec le ministère de l'enseignement supérieur et de la recherche un contrat d'objectifs. Ce contrat associe également le ministère de l'industrie, des postes et des télécommunications, autre tutelle de l'institut.
En 1995, l'INRIA est choisi comme pilote européen du consortium W3C, créé en 1994, aux côtés du MIT pour les Etats-Unis.
En 1996, Bernard Larrouturou devient président directeur général de l'INRIA. En décembre, il fait adopter par le Conseil d'administration les principales orientations de la politique de l'institut pour les prochaines années.
En décembre 1997, un essai prospectif rédigé par Bernard Larrouturou en juillet 1997 et intitulé " Inria 2007, l’INRIA dans dix ans " est diffusé aux partenaires de l'institut.
L'INRIA, c'est :
On pourra trouver en annexe 1 quelques tableaux détaillant les moyens humains et financiers.
Au cœur de la plus grande technopole européenne, l'unité de recherche INRIA Sophia Antipolis représente un potentiel de 400 personnes, dont 140 sur poste budgétaire.
Cette unité entretient de nombreuses collaborations avec les laboratoires de la région ainsi qu'avec le milieu industriel comme peuvent en témoigner les sociétés de technologie créées par d'anciens chercheurs du site.
Thème 1 : Réseaux et systèmes
MEIJE - Parallélisme, synchronisation et temps réel
MISTRAL - Modélisation en informatique et systèmes de télécommunication : recherche et applications logicielles
RODEO - Réseaux à hauts débits, réseaux ouverts
SLOOP - Simulation, langages à objets et parallélisme
TROPICS - TRansformations et Outils Informatiques Pour le Calcul Scientifique
(PLANETE - Protocoles et applications pour l'Internet)
Thème 2 : Génie logiciel et calcul symbolique
CAFE - Calcul Formel et équations
LEMME - Logiciels et Mathématiques
OASIS - Objets Actifs, Sémantique, Internet et Sécurité
PRISME - Géométrie, algorithmes et robotique
SAGA - Systèmes algébriques, géométrie et applications
(CERTILAB- Spécifications formelles, certification de logiciel)
(LETOOL - Environnements de programmation orientés objets et interfaces visuelles)
Thème 3 : Interaction homme-machine, images, données, connaissances
ACACIA - Acquisition des connaissances pour l'assistance à la conception par interaction entre agents
ARIANA - Problèmes inverses en observation de la Terre
EPIDAURE - Imagerie et robotique médicale
ORION - Environnements intelligents de résolution de problèmes pour des systèmes autonomes
ROBOTVIS - Vision par ordinateur et robotique
(AID - Gestion des connaissances pour l'aide à la conception coopérative)
Thème 4 : Simulation et optimisation de systèmes complexes
CAIMAN - Calcul scientifique, modélisation et analyse numérique
COMORE - Contrôle et modélisation de ressources renouvelables
ICARE - Instrumentation, commande et architecture des robots évolués
MIAOU - Mathématiques et informatique de l'automatique et de l'optimisation pour l'utilisateur
OMEGA - Méthodes numériques probabilistes
SINUS - Simulation numérique dans les sciences de l'ingénieur
SYSDYS - Systèmes dynamiques stochastiques
(CHIR - Chirurgie, Informatique et Robotique)
Les travaux dans ce domaine tendent à améliorer l'interaction entre l'homme et la machine. La psychologie cognitive et l'ergonomie permettent de mieux adapter les systèmes informatiques à leurs utilisateurs (aide à l'apprentissage, assistance à la conduite d'installations, postes de pilotage). L'intelligence artificielle joue un rôle central, d'une part sur le plan du dialogue (parole, langage naturel, graphismes et vision, données multilingues), d'autre part pour la conception d'outils avancés (raisonnements, représentation des connaissances, architectures multi-experts).
La modélisation d'objets tridimensionnels et la reconnaissance de scènes, en prenant éventuellement en compte le mouvement, fournissent des techniques de vision par ordinateur nécessaires au pilotage de robots (robots mobiles, véhicules routiers autonomes, robotique médicale) et interagissent avec la synthèse d'images (simulateurs, illumination artificielle, production audiovisuelle). À l'aide en particulier de ces mêmes techniques, des algorithmes de compression d'images ou de séquences d'images sont développés. La géométrie et les statistiques sont à la base de ces travaux.
Thème 3A : Bases de données, bases de connaissances, systèmes cognitifs
ACACIA - Acquisition des connaissances pour l'assistance à la conception par interaction entre agents
AIDA - Modélisation et apprentissage pour l'interprétation de données et l'aide à la décision
ATOLL - Atelier d'outils logiciels pour le langage naturel
CARAVEL - Système de médiation d'information
CORTEX - Intelligence neuromimétique
LANGUE & DIALOGUE - Dialogue homme-machine à forte composante langagière
MAIA - Machine intelligente autonome
MERLIN - Méthodes pour l'Ergonomie des Logiciels Interactifs
OPÉRA - Outils pour les documents électroniques : recherche et applications
ORION - Environnements intelligents de résolution de problèmes pour des systèmes autonomes
ORPAILLEUR - Représentation de connaissances, raisonnement et extractions de connaissances à partir de base de données
PAROLE - Analyse, perception et reconnaissance de la parole
SHERPA - Dynamique des bases de connaissance
VERSO - Bases de données
(AID - Gestion des connaissances pour l'aide à la conception coopérative)
(AIRELLE - Représentations et langages)
(EIFFEL - Cognition et Coopération en Conception)
(READ - Reconnaissance de l'écriture et analyse de documents)
(SANTE – Santé)
Thème 3B : Vision, analyse et synthèse d'images
AIR - Traitement d'image et données satellites dynamiques
ARIANA - Problèmes inverses en observation de la Terre
EPIDAURE - Imagerie et robotique médicale
iMAGIS - Modèles, algorithmes, géométrie pour le graphique et l'image de synthèse
IMEDIA - Images et Multimédia : indexation, navigation et recherche
ISA - Image, synthèse et analyse
MOVI - Modélisation, localisation, reconnaissance et interprétation en vision par ordinateur
ROBOTVIS - Vision par ordinateur et robotique
SHARP - Programmation automatique et systèmes décisionnels en robotique
SIAMES - Synthèse d'image, animation, modélisation et simulation
TEMICS - Traitement, modélisation et communication d'images numériques
VISTA - Vision spatio-temporelle et active
L’objectif d’ORION est de concevoir et de développer des techniques et des logiciels pour, d'une part, le pilotage automatique de programmes et, d'autre part, l'interprétation automatique d'images.
ORION focalise ses travaux sur l'étude des connaissances qui interviennent dans ces deux types de problèmes : connaissances sur les programmes et leur utilisation pour le pilotage automatique de programmes, et connaissances sur les objets et les scénarios à reconnaître pour l'interprétation automatique d'images. Thématiquement, Orion est une équipe pluridisciplinaire, à la frontière des domaines de la vision par ordinateur, des systèmes à base de connaissances et du génie logiciel. Les techniques utilisées relèvent donc de ces trois disciplines. Les applications qui intéressent ORION sont principalement du domaine de la vision par ordinateur. Plus précisément, l’objectif est de faciliter la construction de systèmes intelligents automatiques et adaptatifs, c'est-à-dire des systèmes incorporant explicitement une expertise (intelligents), fonctionnant sans intervention humaine pour les prises de décisions (automatiques) et ayant des capacités de réaction vis à vis des changements de leur environnement (adaptatifs). Parmi les applications qui nécessitent un fort degré d'autonomie, ORION a identifié, d'une part, les problèmes d'automatisation de l'utilisation de programmes, et, d'autre part, les problèmes d'interprétation automatique d'images. L'automatisation de l'utilisation de programmes nécessite de planifier les traitements et de contrôler l'exécution de codes de calcul. On utilisera le terme pilotage automatique de programmes pour désigner ce type de problèmes. Dans de nombreuses applications, l'utilisateur ne peut pas interpréter les résultats des logiciels de traitements de données, soit parce qu'il n'en est pas capable (manque de compétence), soit parce qu'il n'en a pas le temps (saturation de ses capacités), soit enfin parce qu'il n'est pas présent (systèmes embarqués). Ceci correspond à un sous-problème de la perception, celui de l'interprétation des résultats des traitements d'images. On utilisera le terme d'interprétation automatique d'images pour désigner ce type de problèmes.
Monique THONNAT.
L'objectif du pilotage de codes est de faciliter l'automatisation (partielle ou complète) d'une chaîne de traitements préexistants, indépendamment d'un domaine applicatif particulier.
Le pilotage ne vise pas à optimiser les codes eux-mêmes, mais leur utilisation. La problématique du pilotage de codes est très générale et a été appliquée en traitement d'images, en automatique, en calcul scientifique, etc.
Pour cela, un système de pilotage doit contenir la connaissance sur l'utilisation des codes (opérateurs), qui peut être complexe. En effet, les codes ne sont pertinents que dans certaines conditions (selon l'objectif à atteindre, le contenu et type des données). De plus, leur exécution nécessite la détermination précise de paramètres d'entrée souvent sensibles. Les systèmes à base de connaissances donnent les moyens d'exprimer et de structurer une telle connaissance sur la description des codes et leurs conditions d'utilisation.
La réalisation d'un traitement complexe se décompose en :
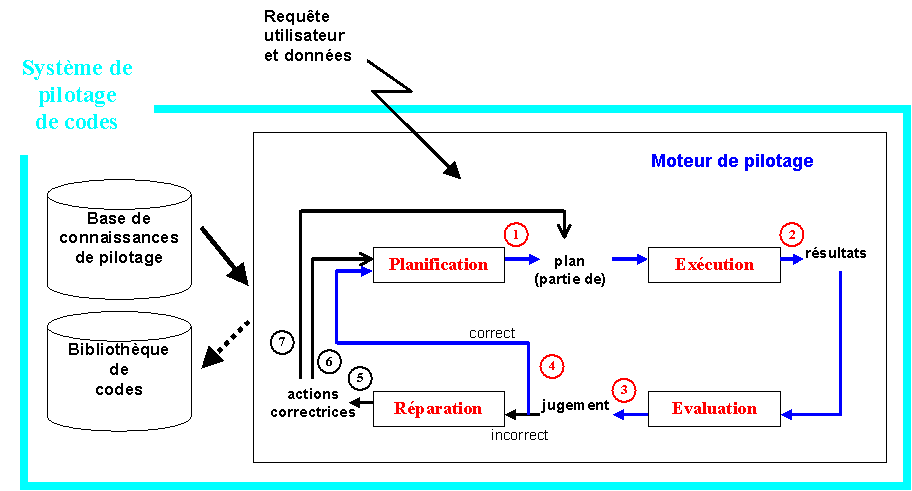
Les intérêts pour l’utilisateur :
Prise en charge de toutes les étapes nécessaires à un traitement et contrôle des résultats obtenus.
Capitalisation des compétences pour utiliser de façon optimale un ensemble de codes, c'est à dire les informations non explicites, que l'on ne trouve ni dans les algorithmes ou les codes sources, ni dans les documentations (si elles existent).
Le moteur de pilotage fournit plus qu'un simple guide intelligent, et n'exige que peu d'interaction avec l'utilisateur ; cela va plus loin que la génération de " scripts ".
L'emploi de techniques de pilotage apporte des capacités d'évolution (dans le nombre ou les caractéristiques de codes pilotés), de lisibilité des informations sur les codes et de souplesse dans l'exécution des codes (adaptation à différentes données en entrée et réparation des erreurs).
L'expert connaissant les codes et leur utilisation dispose d'éditeurs de connaissances pour constituer la base de connaissances et d'une interface graphique pour visualiser cette connaissance. Un moteur de pilotage réutilisable pour de nombreuses applications, connecté à la base de connaissances et aux codes, constitue un système de pilotage complet.
L’interface graphique :
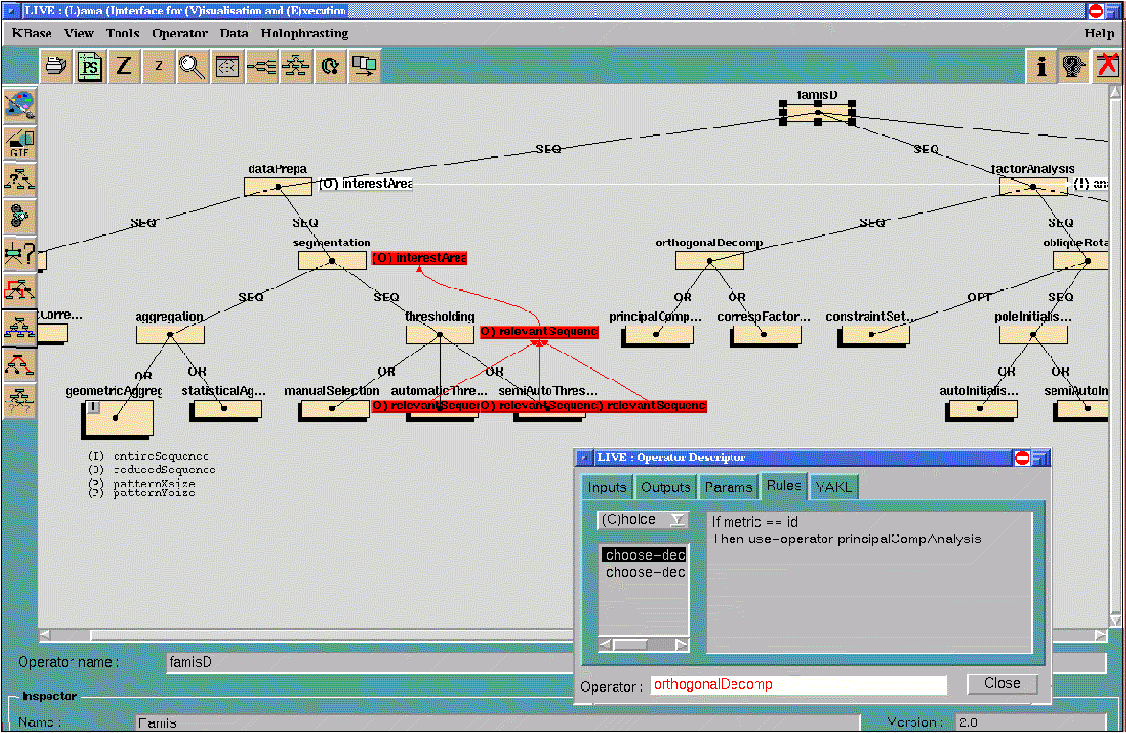
Les connaissances de l’expert sont décrites de la façon suivante :
Puis :
C’est dans le contexte du pilotage de programmes que se place mon sujet de stage. Le domaine de ce sujet est principalement l’apprentissage symbolique.
Comme nous l’avons vu précédemment un expert intervient dans la description du pilotage de codes. Cet expert ne sait pas toujours, ou n'est pas toujours disponible pour fournir la connaissance exhaustive sur tous les enchaînements possibles de programmes ou sur les valeurs à affecter aux paramètres dans tous les cas.
Le moteur doit alors pallier ces manques en lançant des mécanismes longs et coûteux de réparation pour ajuster les bonnes valeurs de paramètres, ou de planification dynamique pour déterminer le meilleur enchaînement. Lorsque ces mécanismes réussissent, leurs résultats sont actuellement perdus pour les futures sessions.
L'objectif principal du stage est de mémoriser les résultats de ce type de travail du moteur pour éviter de le refaire, dans des cas similaires. Ceci sera réalisé par un programme d'apprentissage automatique combinant éventuellement plusieurs paradigmes, pour apprendre les valeurs optimales des paramètres des programmes, et des choix de programmes, principalement en fonction des données. Le programme devra s’intégrer dans une plate-forme logicielle existante pour la construction de systèmes de pilotage.
Un autre objectif de ce stage est en rapport avec la réparation. Le mécanisme de réparation implique pour le système de pilotage le besoin de se rendre compte qu’il y a eu un problème. Ceci est fait via des mécanismes d’évaluation, basés sur des règles d’expert, pour juger de la qualité des résultats obtenus. L’évaluation automatique (ne nécessitant pas l’intervention d’un utilisateur) est difficile sur des images. Mais dans certains cas, on peut avoir à disposition des courbes issues de ces images ; celles-ci sont plus simples à évaluer automatiquement. Donc, toujours dans le cadre du pilotage de la boucle évaluation/réparation, il nous faudra également travailler sur un programme existant de description symbolique de courbes et d’évaluation automatique de résultats, programme visant à décharger au maximum l’utilisateur final. C’est par ce travail que nous commencerons.
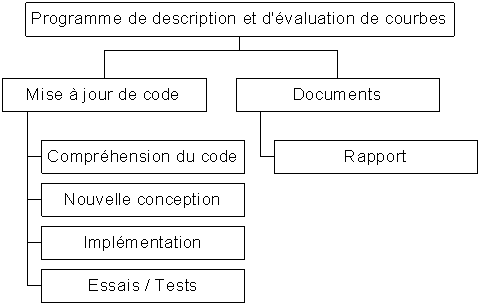
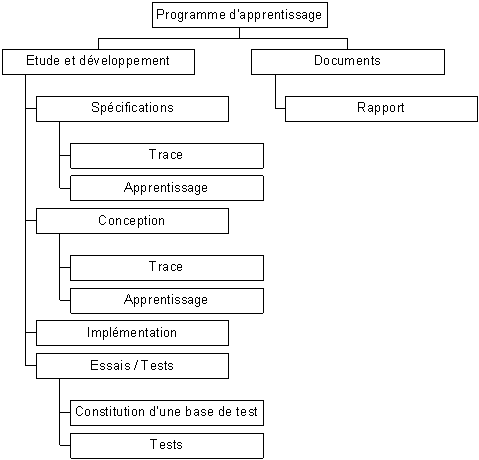
Les tâches à réaliser sont décrites dans l’arbre des tâches en annexe 2
Planning général prévisionnel :
|
Janvier |
Février |
Mars |
Avril à Juin |
|
Documentation sur le pilotage et l’apprentissage. |
Reprise du programme de description de courbes et tests |
Conception du programme d’apprentissage. Rapport |
Codage et test du programme d’apprentissage. Rapport final |
Des programmes de traitement d’images peuvent produire des résultats sous forme de courbe ou de jeux de courbes (par exemple, la distance d’un contour à une droite…). L’évaluation de ces résultats peut nécessiter une certaine expertise de la part de l’utilisateur. Le but d’un programme de description symbolique et d’évaluation de jeux de courbes serait de permettre, dans les cas où cela est possible, une évaluation automatique de ces courbes résultats, dans le cadre du pilotage de codes. Les règles d’évaluation fournies par l’expert utilisant des termes de description symbolique, la première étape, avant de faire cette évaluation automatique est de fournir une description symbolique de ces courbes.
Par exemple, une " courbe symbolique " peut être décrite comme suit :
3 segments
segment 1 : long / décroissance faible
segment 2 : court / croissance forte
segment 3 : long / décroissance forte
1 pic
pic 1 : position retardée / hauteur grande / largeur faible / forme très pointue.
Ces descripteurs symboliques pouvant varier selon le contexte, soit dans leur dénomination, soit dans leur correspondance avec les valeurs numériques, un fichier dit de " contexte " doit être défini. Ce fichier contient les équivalences entre symboles et valeurs numériques (éventuellement normalisées), fixées par l’expert.
Exemple : court Û [0 ; 0,5] et long Û [0,5 ; 1]
Un tel programme existe [3], il présente cependant quelques inconvénients.
En effet, on peut faire les remarques suivantes :
Le travail à faire va donc être avant tout de comprendre le code et d’ajouter des commentaires puis de :
Nous désirons avoir une description symbolique de courbe en terme de segments et de pics, pour pouvoir juger cette courbe.
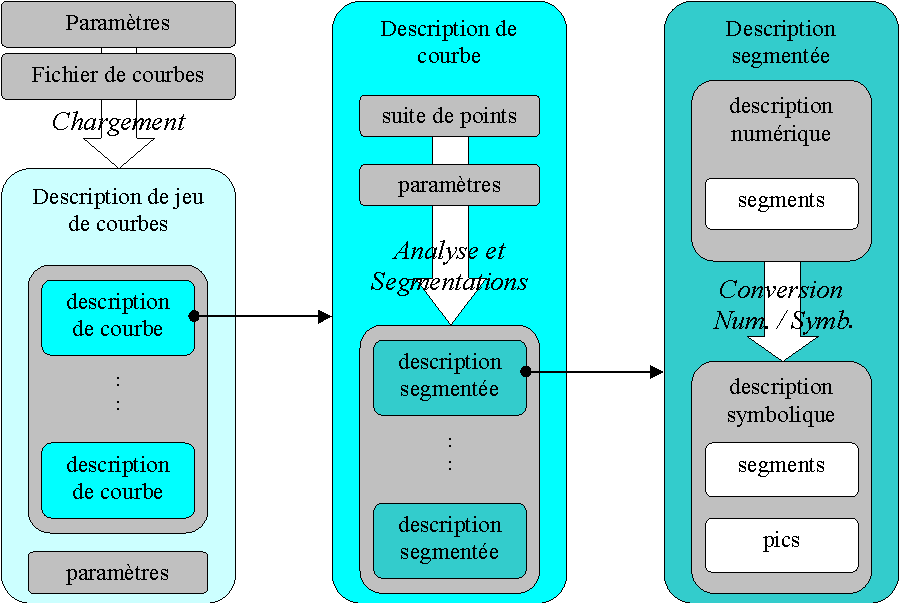
Nous allons maintenant voir comment opère le programme, quels sont les principes de son fonctionnement.
Le programme commence par charger un certain nombre de courbes à évaluer à partir de fichiers. Il récupère ensuite les paramètres de traduction numérique ® symbolique (et d’exécution du programme) dans un fichier " contexte " écrit par l’expert.
Le programme va ensuite traiter toutes les courbes du jeu chargé.
D’abord la courbe est filtrée pour rendre la segmentation moins sensible au bruit. Ce filtrage est paramétrable : l’utilisateur a le choix parmi trois filtres. Il peut également régler la largeur de la fenêtre d’application du filtre.
Ensuite, le programme va pouvoir procéder à la segmentation. Pour une courbe, il pourra effectuer plusieurs niveaux de segmentation.
La première étape de la segmentation est la construction d’un " arbre de segmentation ".
La courbe dont le programme dispose est échantillonnée sur un certain nombre de points, soit n. Il commence par relier ces n points par n-1 segments puis par associer ces segments en n-2 paires de segments consécutifs. (Chaque segment est pris deux fois, dans deux paires consécutives, exceptés le premier et le dernier).
Pour chacune de ces paires de segments, il calcule l'erreur commise en remplaçant les deux segments par un seul.
Le calcul de l'erreur est le suivant :
Pour chaque pas d'échantillonnage, le programme calcule l'intégrale du carré de la fonction qui est la différence entre l'équation du segment représentant un échantillon de courbe et l'équation du segment considéré. La somme de toutes ces intégrales pour le segment considéré est l'erreur (nous expliciterons ce calcul un peu plus loin).
Le programme trie alors dans un tableau les paires de segments par ordre croissant d'erreur. Il supprime la dernière paire du tableau en la remplaçant par un segment et met à jour les deux paires touchées par cet échange, puis trie le tableau de nouveau, sans toucher à l’ancienne dernière case qui contient toujours la trace de la paire remplacée.
Il itère le procédé jusqu'à n'avoir plus qu'une paire de segments. En remplaçant cette paire par un seul segment, il obtient "la racine" de l'arbre de segmentation, segment qui relie les deux points d'abscisses extrêmes de la courbe.
Le programme dispose maintenant d'un arbre de segmentation.
La seconde étape va consister à obtenir les différentes segmentations de la courbe. Le programme va pour cela utiliser un seuil d’erreur initial et un pas d’incrément de cette erreur. Ensuite, il " remonte " dans l'arbre de segmentation jusqu'à satisfaire aux conditions.
A partir des 3 segmentations, le programme va générer trois descriptions symboliques pour la même courbe.
Tout d’abord, les descriptifs de segments se rapportent à leur longueur et à leur pente. Selon des critères paramétrables dans le fichier contexte, un segment peut être court moyen ou long. Sa pente peut être forte, moyenne, faible (positive ou négative) ou nulle. Les segments étant décrits, le programme recherche ensuite des pics.
Un pic est un ensemble de 2 segments consécutifs formant un angle suffisamment faible. Le programme décrit la position du pic (avancé, moyen, retardé) sur l’axe des abscisses, sa largeur (étroit, moyen, large) par rapport à la largeur (en termes toujours d’abscisse) de la courbe , sa hauteur (petit, moyen, grand) par rapport à celle de la courbe (en termes d’ordonnée) et sa forme (arrondi, assez pointu, très pointu) en fonction de l’angle entre les deux segments qui le constituent.
Ces descriptions symboliques permettront de comparer des courbes à des modèles théoriques, à l'aide notamment d’un algorithme calqué sur celui de Wagner et Fischer relatif au calcul de distance entre chaînes de caractères.
La partie importante des fichiers composant le code sont les suivants :
Contient les différents types de base associés au fichier de contexte, et qui sont utilisés durant le parsing de contexte. Tous ces types dérivent de la classe abstraite Type. L'utilisateur pourrait éventuellement ajouter et utiliser ses propres types.
Contient les méthodes d’analyse du fichier contexte, de recherche et de conversion de champ.
Effectue toutes les opérations algorithmiques sur une courbe simple (filtrage, segmentation, passage en symbolique...)
Charge et analyse un fichier contenant un ensemble de courbes, avec détection automatique du format (PPM ou INSERM).
Représente un jeu de courbes, et offre des méthodes de chargement, analyse, mise sous forme symbolique, affichage...
Permet d'afficher un ensemble de courbes dans une fenêtre graphique, avec un titre, à modifier si on veut changer d'utilitaire de visualisation (par défaut, utilisation de GNUPLOT)
Classe de tableau dynamique générique.
Définit différentes classes de filtres à fenêtre coulissante.
Classe de liste chaînée à simple sens. Selon le compilateur, on pourra utiliser la version templates (listt.h) ou la version macros (listm.h). La convention de déclaration/définition (classListDeclare et classListDefine) est la même.
Fichier principal du prototype, qui appelle les différentes phases une par une.
Définit les points, segments, représentation symbolique des segments et des pics. Il est très lié à la classe curve.
Classe de chaîne de caractères.
Classes représentant les variables symboliques, leur type, les différentes fonctions d'appartenance.
Les modifications ont fait disparaître les fichiers dynarray.h, list.h, listm.h, listt.h, string.cc qui définissaient des classes supports, remplacées par des classes de la STL. Le fichier context-types.cc a, lui, été supprimé du fait du changement de conception.
Précisons un peu la méthode CalcError de Segment dont voici le corps, après modification : (nous avons gardé le même calcul d’erreur, après avoir retrouvé d’où venait le calcul fait dans la méthode CalcError originale).
// Méthode CalcError
//
// But : Calcul d erreur entre la courbe et sa segmentation
// (erreur quadratique cumulée)
double Segment::CalcError(const Curve &cur)
{
const Point *p = cur.pointTable[0];
int i = 0;
double c = left->x, d = right->x;
double yc = left->y, yd = right->y;
error = 0;
for (; (i < (cur.nbPoints - 1)) && (p->x < left->x); i++, p = cur.pointTable[i]);
for (; (i < (cur.nbPoints - 1)) && (cur.pointTable[i+1]->x <= right->x); i++, p = cur.pointTable[i])
{
// On a deux fonctions lineaires ( celle representant un élément de la courbe
// segmentée et celle représentant le segment )
// On calcule l’intégrale du carré de la différence de ces deux fonctions
// sur chaque intervalle d’échantillonnage de la courbe
double a = p->x, b = cur.pointTable[i+1]->x;
double ya = p->y, yb = cur.pointTable[i+1]->y;
double A = ((yd - yc) / (d - c)) - ((yb - ya) / (b - a));
double B = ((d*yc - c*yd) / (d - c)) - ((b*ya - a*yb) / (b - a));
error += B*B * (b - a) + A*B * (b*b - a*a) + A*A * (b*b*b - a*a*a)/3;
}
return error;
}
Pour chaque pas d’échantillonnage de la courbe, on exprime l’équation des droites supports du segment représentant la courbe et du segment considéré :
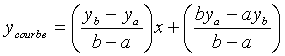
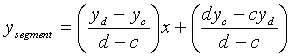
On calcule alors la différence :
![]()
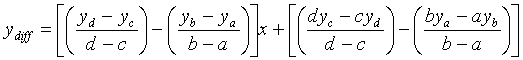
soit :![]()
Nous calculons 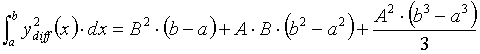
C’est ce terme que nous ajoutons à l’erreur totale sur
chaque pas ![]() d’échantillonnage
de la courbe.
d’échantillonnage
de la courbe.
Les deux méthodes utilisées sont BuildSegTree et CopySegTree de la classe Curve.
C’est la méthode BuildSegTree qui crée l’arbre de segmentation.
Nous avons vu plus haut le principe général de cette méthode. Nous commençons par relier les n points d’échantillonnage de la courbe par n-1 segments que nous associons en n-2 paires de segments consécutifs que nous trions par erreur croissante. Nous avons vu que nous gardons à chaque fois la paire de segments qui a l’erreur maximum. En effet, si nous partons de la segmentation la " pire ", c’est à dire un seul segment qui joint les deux extrémités de la courbe originale, nous allons chercher à remplacer ce segment par une paire de segments qui minimise l’erreur. C’est à dire que, vu dans l’autre sens, nous avons une erreur maximum en passant de la paire de segments au segment. C’est pour cette raison que nous trions les paires par ordre croissant et que nous remplaçons la dernière. Ensuite, la méthode CopySegTree fournit la segmentation à l’aide également de la méthode Build de la classe Segment.
Voilà le code des deux méthodes (après transformations, cf. point 2 de 6.4.2)
// Méthode CopySegTree
//
// But : Copie l’arborescence de segmentation
// jusqu’à un certain point ( critère erreur )
// et génère à ce niveau une représentation segmentée de la courbe
void Curve::CopySegTree(const Curve &c, double errmax)
{
Size(c.nbPoints);
c.root->Build(*this, errmax, true);
nbPoints = cntPoints;
InitSegs(c);
}
// Méthode Build
//
// But : Construction de la courbe segmentée ( en fonction d une erreur voulue )
// On descend dans l arborescence de segmentation jusqu’à l’erreur voulue
// en récupérant les points extrémités des segments
void Segment::Build(Curve &c, double errmax, bool first)
{
if (first) c.AddPoint(left->x, left->y);
if ((error > errmax) && (nbSons)) {
for (int i = 0; i < nbSons; i++) son[i]->Build(c, errmax, false);
}
else c.AddPoint(right->x, right->y);
}
Build est une méthode récursive qui remonte dans l’arbre de segmentation, tant que c’est possible et cela jusqu’à obtenir une erreur inférieure au seuil errmax désiré, et cela pour chaque branche. On ajoute alors le point droit du segment auquel on est arrivé, le premier appel de Build ayant mis en place le point le plus à gauche de la courbe.
InitSegs permet de " joindre " les points créés par Build. On obtient ainsi la segmentation souhaitée.
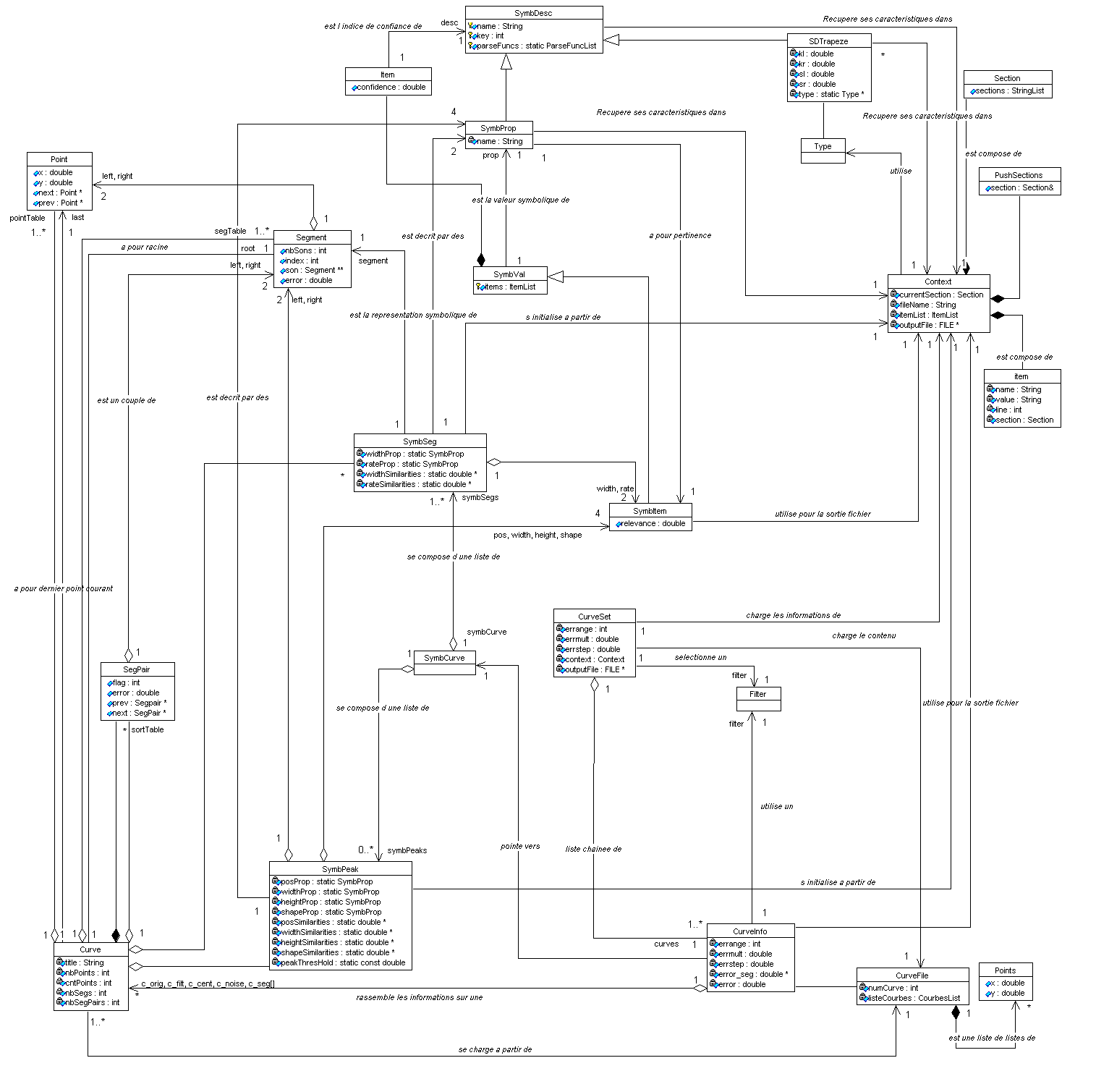
La première étape du travail a été de comprendre et de s’approprier le code.
Suite à cela nous avons établi le schéma UML du programme original (cf. annexe 4). Nous avons également ajouté les commentaires dans le code, pour le rendre plus accessible.
A partir de là, nous avons pu préciser la nature des problèmes décelés au 1.1.
On a modifié toutes les méthodes utilisant la syntaxe gcc et non ANSI suivante : (exemple)
String EnumType::Convert(const String &value, void **res) return str
{
… corps de la méthode …
}
pour revenir à cette syntaxe ANSI, plus courante et portable (exemple modifié)
String EnumType::Convert(const String &value, void **res)
{
… corps de la méthode …
return str ;
}
On a supprimé les opérateurs (gcc) :
a >? = b
a >? b
a <? = b
a <? b
pour les remplacer respectivement par
a = max ( a, b )
max ( a, b )
a = min ( a, b )
min ( a, b )
équivalents, plus lisibles et portables.
Ces simplifications portent sur les points suivants :
double Curve::SquareTotal(void) const
{
double tot = 0;
for (int i = 0; i < (nbPoints - 1); i++) {
double a = pointTable[i]->x, b = pointTable[i + 1]->x;
double ya = pointTable[i]->y, yb = pointTable[i + 1]->y;
if ((ya > 0) ^ (yb > 0)) {
double c = (a*yb - b*ya) / (yb - ya);
tot += ya*ya * (c - a) / 3;
tot += yb*yb * (b - c) / 3;
}
else {
double A = (yb - ya) / (b - a);
double B = (b*ya - a*yb) / (b - a);
tot += B*B * (b - a) + A*B * (b*b - a*a) + A*A * (b*b*b - a*a*a)/3;
}
}
return tot;
}
en la remplaçant par la version suivante :
double Curve::SquareTotal(void) const
{
double tot = 0;
for (int i = 0; i < (nbPoints - 1); i++) {
double a = pointTable[i]->x, b = pointTable[i + 1]->x;
double ya = pointTable[i]->y, yb = pointTable[i + 1]->y;
// On traite la fonction F(x) passant par les points (a,ya) (b,yb)
// F(x)=Ax+B avec A = (yb-ya)/(b-a) et B=(b*ya-a*yb)/(b-a)
// L’intégrale de F*F entre a et b après simplification s ajoute a tot
tot += ( b - a ) * ( yb*yb + ya*yb + ya*ya ) / 3;
}
return tot;
}
Il y avait deux classes correspondant au concept de " point ", la première imbriquée dans la Classe CurveFile contenant les coordonnées x et y d’un point, et la seconde contenant les coordonnées x et y d’un point et des pointeurs vers les suivant et précédent.
Nous avons remplacé les deux classes de Points qui étaient relativement similaires par une classe unique. Cette classe ne contient plus comme données membres que les coordonnées x et y. Les autres fonctions ou classes nécessitant un chaînage des points utilisent simplement un vecteur de ces points. Nous reparlerons de ce type <vecteur> un peu plus loin.
La partie exploitation du contexte mettait en jeu de nombreuses classes et de nombreux traitements. L’utilisateur pouvait éditer de la manière qu’il le souhaitait le contexte. Ensuite des procédés de parsing complexes permettaient de vérifier la syntaxe du contexte et de récupérer les informations contenues.
Ce contexte permettait seulement de modifier les intervalles de définition attachés aux descripteurs et de choisir le filtre ainsi que la largeur de sa fenêtre associée.
On ne pouvait pas ajouter de degré de description (par exemple " très court " ou/et " très long " pour un segment, etc.).
Le changement le plus radical que nous avons fait porte donc sur ce fichier contexte. En effet, la complexité des procédés d’analyse et d’exploitation de contexte, nécessitant de nombreuses classes et méthodes, ne nous a pas semblé inévitable. Pour contourner ces difficultés, nous avons pensé à générer le contexte automatiquement, avec donc une syntaxe et une mise en forme constantes. Ce contexte est modifiable, mais par l’entremise d’une interface ne donnant pas d’accès direct à l’utilisateur. La modification et la récupération des données du contexte sont alors très simples. Cela ne nécessite plus d’analyse complexe.
Suite à cette modification, nous avons eu la possibilité d’ajouter simplement d’autres paramètres dans ce contexte. Sont maintenant paramétrables à partir du contexte :
On peut maintenant ajouter des degrés de description (par exemple très court pour la longueur d’un segment). Cependant, ces degrés de description ne sont pris en compte, pour le moment, que pour la description proprement dite ; l’évaluation de similarité entre courbes ne fonctionne toujours qu’avec les descripteurs de la version initiale du programme.
La version révisée du schéma UML est consultable en annexe 5.
Le programmeur avait défini ses propres classes de :
Nous avons remplacé ces classes en utilisant la STL.
Tous les objets et variables du programme utilisant les classes de liste simplement chaînée et tableau dynamique ont été remplacées par des vecteurs de la STL.
Les principales caractéristiques d’un vecteur sont les suivantes :
Dans notre cas, tous les ajouts d’éléments quels qu’ils soient se font en fin de séquence et l’accès aléatoire par indice peut être pratique.
La classe vecteur de la STL est la plus simple des classes " containers ", c’est pourquoi nous avons choisi de l’utiliser.
La classe de chaînes de caractères définie par le programmeur a été remplacée par la structure de string de la STL.
Nous avons également remplacé la presque intégralité des char* par des string.
On a également modernisé le code au niveau des entrées-sorties :
Nous avons exploité les flux de données (stream), en supprimant la gestion traditionnelle des entrées-sorties (print, scan) empruntée au C.
Ces changements ont permis de rendre le code plus lisible, portable et efficace. Il resterait quelques améliorations à apporter, notamment au niveau de l’évaluation automatique qui ne gère pas encore les modifications en nombre des descripteurs symboliques. On ne peut donc pas, pour le moment, comparer des courbes qui n’ont pas, pour les segments, trois niveaux de longueur et sept niveaux de pente et, pour les pics, trois niveaux de position, de largeur, de hauteur et de forme.
Nous allons avoir besoin d’utiliser une technique d’apprentissage pour améliorer le fonctionnement d’un système de pilotage. Passons rapidement en revue quelques-unes une de ces techniques. [1]
L’apprentissage comme généralisation
Il s’agit, à partir le plus souvent d’un ensemble d’exemples, de former une généralisation couvrant tous les exemples positifs et excluant les exemples négatifs. Selon les problèmes, on cherche une généralisation maximalement spécifique ou, au contraire, maximalement générale, voire on conserve toutes les généralisations valides (cet ensemble a été nommé par Mitchell l’espace des versions). Les travaux portent sur la définition de la relation de généralité en fonction du langage de représentation utilisé, sur la recherche dans l’espace des généralisations, sur l’utilisation des contre-exemples, etc.
L’apprentissage comme approximation
L’idée consiste ici à considérer le concept à apprendre comme une fonction cible que l’on désire approcher. Les définitions de distance analytique appropriées et les problèmes de convergence sont alors au cœur de cette approche. Si de plus, on introduit une notion de distribution des exemples, entrent alors en jeu les théories de probabilité et de mesure sur les ensembles. Combinant ces notions, Valiant, en 1984, a proposé le cadre formel d’apprenabilité Probablement Approximativement Correcte, très utile en classification.
L’apprentissage comme confirmation d’hypothèses
On recherche un modèle, parmi tous les modèles possibles, qui explique au mieux les données observées. La connaissance préalable inclut la représentation choisie et les connaissances expertes, y compris la donnée de probabilités a priori. Le modèle appris résulte de méthodes de recherche et d’optimisation, mais surtout d’un principe d’apprentissage basé sur la révision des probabilités conditionnelles et sur la théorie de la décision. Il est ainsi possible d’évaluer à tout moment l’utilité de chaque hypothèse (ou théorie). Ce cadre conceptuel a l’avantage d’être très général et de permettre de rendre compte facilement des connaissances a priori et du mécanisme d’apprentissage incrémental.
L’apprentissage comme compression d’information
On voit ici l’apprentissage comme la découverte de régularités au sein des données. Comme toute régularité offre le moyen de résumer ou de comprimer l’expression des données, il s’agit de trouver la théorie permettant la compression maximale. La qualité d’une hypothèse est évaluée ici en termes de longueur de codage, et non plus (cf. ci-dessus) en termes de probabilités. Un intérêt de cette approche est son lien naturel direct avec la notion de complexité algorithmique.
La technique que nous allons utiliser sera basée sur la généralisation où les exemples seront les erreurs et corrections faites par un système de pilotage, stockées sous forme de trace pendant l’exécution d’une session de pilotage.
Comme nous l’avons déjà dit, il va s’agir de concevoir en C++ un programme d’apprentissage automatique visant à enrichir une base de connaissance pour éviter au maximum la mise en jeu de mécanismes de réparation de la part du moteur de pilotage. Cet apprentissage devra se faire au niveau des règles d’initialisation et de choix. [5]
Nous disposons pour réaliser ce travail d’une trace d’exécution générée par le moteur. Cette trace contient toutes les réparations qui ont eu lieu durant l’utilisation. C’est à partir de cette trace que nous allons réaliser l’apprentissage.
On peut représenter cela de la manière très simplifiée suivante :

Une règle quelconque [2] se présente sous la forme suivante :
Nous ne nous intéresserons qu’à des règles d’initialisation ou de choix. De plus, nous nous limiterons aux règles qui ont des prémisses relativement simples.
Les prémisses sont une suite de conditions liées implicitement par des ET logiques.
Les prémisses que nous avons désignées par " simples " sont des suites de conditions décrites par :
Donnée Comparateur Valeur (numérique ou symbolique)
Exemple :
If im-info-connectee.epaisseur-coupes == moyenne,
precision-calcul <> fine,
precision-calcul <> minimale
Les différents comparateurs sont : <>, ==, >, <, >=, <=
( différent de, égal à, strictement supérieur à ... )
L’action d’une règle d’initialisation consiste à initialiser un paramètre à une valeur (numérique ou symbolique).
Exemple :
Then isotropie := quasi
L’action est ici le choix ou le refus d’un opérateur (nommé) ou d’un opérateur présentant certaines caractéristiques.
Exemple : Then use-operator seuillage-histo
Le moteur, durant son fonctionnement, manipule de nombreuses informations. Il est possible de les récupérer dans une trace. Nous ne retiendrons dans cette trace que les informations strictement nécessaires dans le cadre de l’apprentissage que nous voulons mener.
Ainsi, nous avons défini que la trace contiendra toutes les réparations qui ont eu lieu durant l’utilisation du programme, sous la forme suivante : on trouvera les règles ayant échoué (mauvaise évaluation) ainsi que l’action finalement retenue. On trouvera également un " contexte des données " contenant les valeurs disponibles des données avant l’application de la règle, pour chaque réparation.
La technique d’apprentissage que nous allons mettre en place s’effectuera en 2 étapes :
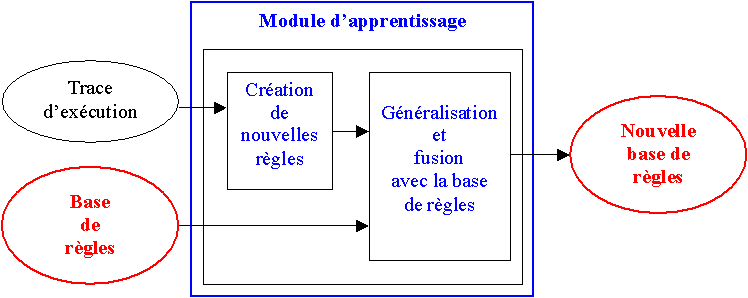
On parcourt toutes les réparations que contient la trace. Pour chaque réparation, on crée une nouvelle règle spécifique.
Pour créer cette règle, on devra donc créer ses prémisses et son action. L’action est simple à trouver : c’est l’action finalement retenue à l’issue des réparations.
Pour les prémisses, on commencera par reprendre les prémisses de la règle qui a échoué, auxquelles on ajoutera des prémisses tirées des valeurs (numériques ou symboliques) des données contenues dans le " contexte des données ". On ajoutera le maximum de ce genre de prémisses. La règle obtenue sera donc très spécifique, d’où sa désignation.
Toutes les règles spécifiques étant créées, on va maintenant devoir les généraliser.
On établit en premier lieu des listes de règles généralisables entre elles. Une condition nécessaire pour pouvoir généraliser des règles est qu’elles aient la même action.
Pour les règles de choix, il n’y a pas de problème : l’action est le choix ou le rejet d’un opérateur (ou de caractéristiques d’opérateur), donc les actions sont identiques si et seulement si les opérateurs (ou caractéristiques d’opérateur) sont les mêmes.
Pour les règles d’initialisation, il y a deux cas possibles :
Cas des règles spécifiques initialisant un paramètre avec une valeur numérique :
On doit commencer par regrouper les règles initialisant le même paramètre. Ensuite, on envoie les valeurs numériques des conclusions de ces règles à un programme (cf. annexe 6). Celui-ci, à partir d’une liste de nombres, les regroupe par intervalle d’une certaine largeur relative maximum (paramétrable) et selon un critère (lui aussi paramétrable) qui maximise le nombre d’éléments et minimise leur variance par intervalle.
Les listes de règles généralisables étant établies, on procède enfin à la généralisation.
Le but de cette étape est de déterminer une règle générale englobant les règles spécifiques de la liste. Pour ce faire, on va essayer de ne garder que les prémisses dites pertinentes qui seront les prémisses de la règle générale.
Les prémisses portant sur les données à valeurs symboliques ne sont pertinentes et donc conservées que si elles sont identiques dans toutes les règles, ou s’il existe pour l’une d’elles un intervalle de définition englobant toutes les autres.
C’est un peu plus délicat pour les prémisses portant sur les données à valeurs numériques.
Cas d’une prémisse numérique.
On trie par ordre croissant les différentes valeurs et intervalles de validité de la donnée considérée. Si une " grande majorité " de ces points et intervalles sont " suffisamment proches " les uns des autres, on considère la prémisse pertinente et on construit un ou plusieurs intervalles de validité incluant cette " grande majorité " de points.
S’il n’y a pas de majorité(s) d’éléments " suffisamment proches ", la prémisse est rejetée. Ce programme est détaillé en annexe 7.
L’action de la règle générale de choix sera l’action commune à toutes les règles spécifiques dont la règle générale est issue.
L’action de la règle générale d’initialisation sera l’initialisation du paramètre concerné à la valeur moyenne des valeurs d’initialisation des règles spécifiques dont la règle générale est issue.
De cette généralisation pourront naître des règles conflictuelles entre elles ou avec les règles de l’expert.
Deux règles quelconques (même opérateur) de conclusions différentes sont en conflit si et seulement si :
Tous les cas de conflits sont les suivants :
On a en bleu l’intervalle de validité d’une donnée dans la première règle , en rouge l’intervalle de validité de la même donnée dans la seconde règle et en vert l’intervalle conflictuel Ic.
Il y a de nombreuses possibilités pour gérer les conflits.
En voici une liste non exhaustive :
Toutes ces possibilités sont plus ou moins arbitraires.
Les méthodes b et c ne semblant pas judicieuses sont abandonnées. En effet, elles modifient le domaine de validité d’une règle (et cela arbitrairement) de façon très radicale et peuvent donc engendrer des règles fausses ou inutilisables.
On implémentera les cas a, d et e pour les tester et les valider ou non. A priori, elles n’ont pas les défauts signalés ci-dessus.
Les conflits étant levés, on peut maintenant ajouter à la base de règles expertes les nouvelles règles spécifiques et générales. Ainsi, lors d’une utilisation ultérieure du programme de pilotage, les réparations qui avaient déjà eu lieu ne se reproduiront plus et de nouveaux cas de réparation seront évités grâce aux nouvelles règles générales.
Au cours des sessions suivantes, il sera éventuellement possible de refaire des opérations d’apprentissage. Le choix des modalités précises d’utilisation du programme n’est pas encore fixé.
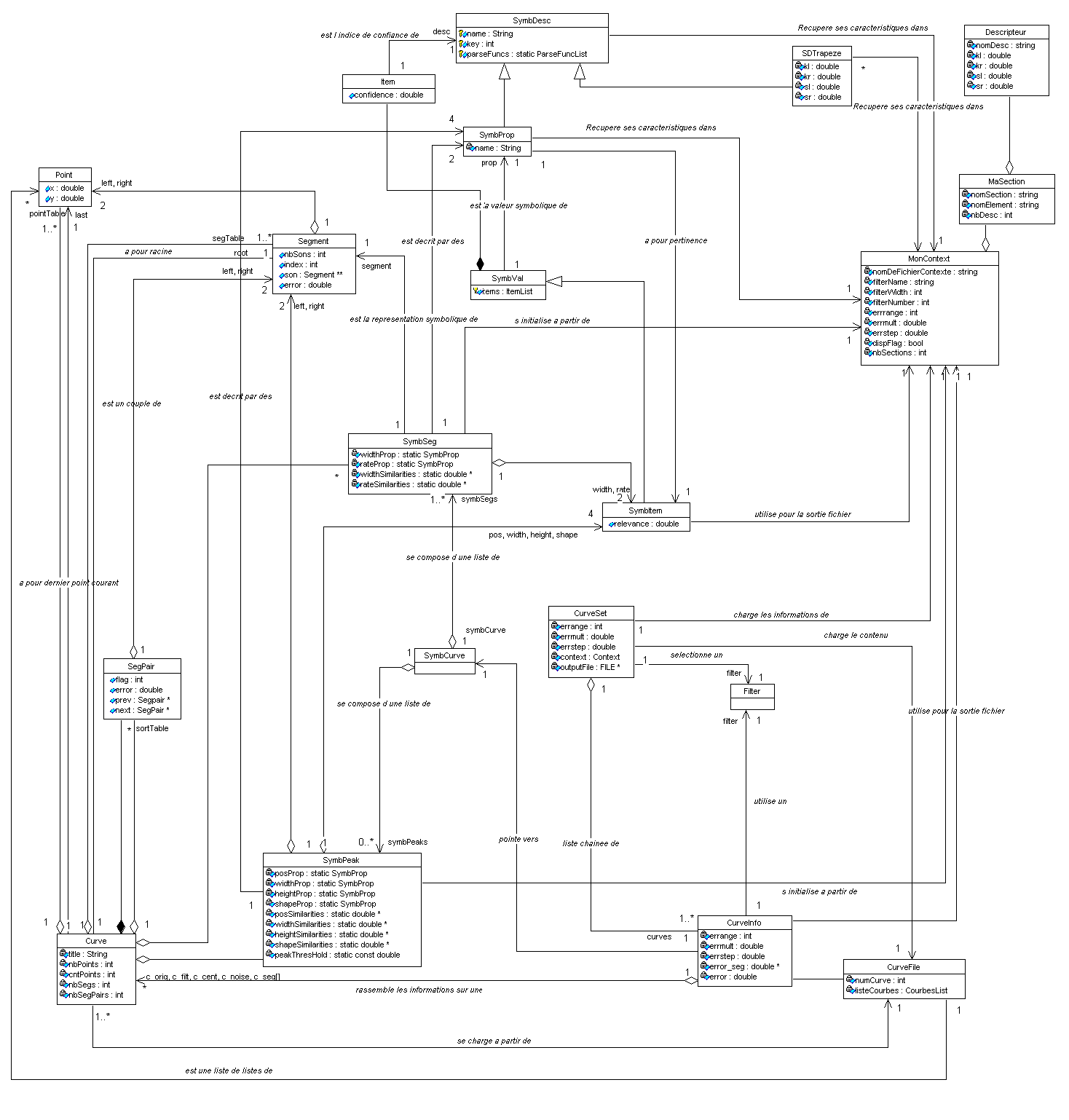
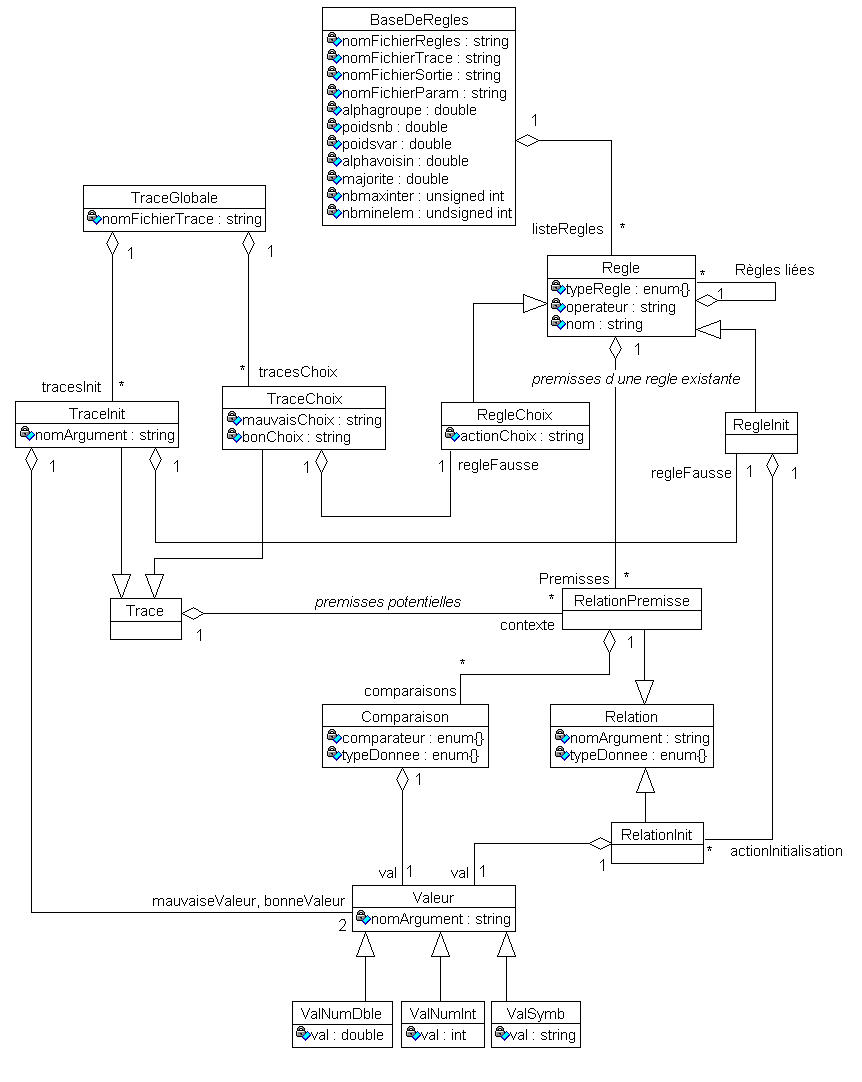
L’implémentation est faite en C++. La phase d’analyse et de conception a fait apparaître les classes suivantes (au format UML). Le schéma UML complet est en annexe 8.
|
BaseDeRegles |
|
nomFichierRegles : string listesRegles : vector<Regle>[4] alphagroupe : double poidsnb : double poidsvar : double alphavoisin : double majorite : double nbmaxinter : unsigned int nbminelem : unsigned int nomFichierTrace : string nomFichierSortie : string nomFichierParam : string |
|
void Lecture(string nomFichierRegles) void Ecriture() void MiseAJourBase() list<Conflit> DetectionConflit() void LectureParametresExecution() vector<vector<RegleChoix*>> ListeRegleChoixMemeConclu(vector<RegleChoix*>& regle) vector<vector<RegleInit*>> ListeRegleInitMemeParam(vector<RegleInit*>& regle) vector<vector<RegleInit*>> ListeRegleInitParamSymbMemeValeur(vector<RegleInit*>& regle) vector<RegleInit*> ListeNouvellesReglesInit(TraceGlobale& trace) vector<RegleChoix*> ListeNouvellesReglesChoix(TraceGlobale& trace) vector<vector<Regle*>>CreerListeReglesGeneralisables(vector<RegleInit*>& nouvellesReglesInit, vector<RegleChoix*>& nouvellesReglesChoix) void CreationNvellesReglesGales(unsigned int& i, vector<vector<RelationPremisse>>& prNouvelleRegle, vector<vector<Regle*>>& ReglesSpecif) void Generalisation(vector<vector<Regle*>>& ReglesSpecif) void SuppressionRegle(list<unsigned int> TablIndiceReglesSupprimer) void ResolutionConflit(list<Conflit>& conflits) |
|
Regle |
|
reglesLiees : vector<Regle*> operateur : string nom : string typeRegle : enum{apprGen,apprSpec,expFix,expModif} premisses : vector<RelationPremisse> |
|
virtual string Action() const void SubstitutionPremisse(unsigned int prASubstituer, RelationPremisse nvellePr) bool ExisteConflit(Regle*& regle) const |
|
RegleInit : Regle |
RegleChoix : Regle |
|
|
actionInitialisation : RelationInit* |
ActionChoix : string |
|
|
virtual string Action() const |
virtual string Action() const |
|
Conflit |
|
indice : vector<unsigned int> type : vector<TypeDeRegle> |
|
Relation |
|
nomArgument : string typeDonnee : enum {} |
|
RelationInit : Relation |
|
val : Valeur* |
|
RelationPremisse : Relation |
|
comparaisons : vector<Comparaison> |
|
bool EstEgal(RelationPremisse& relPr) const Interval Convert() const bool IntersectionVide(RelationPremisse& relPr) const bool operator<(RelationPremisse& relPr) |
|
Comparaison |
|
comparateur : enum {} typeDonnee : enum {} val : Valeur* |
|
bool EstUtile() const bool operator<(Comparaison& comp) |
|
Valeur |
|
nomArgument : string |
|
ValeurNumInt: Valeur |
ValNumDble : Valeur |
ValSymb : Valeur |
||
|
val : int |
val : double |
val : string |
||
|
TraceGlobale |
|
nomFichierTrace : string tracesInit : vector<TraceInit*> tracesChoix : vector<TraceChoix*> |
|
void Lecture() void Ecriture() TypeDonnee LectureType(ifstream& inputFile) Valeur* LectureValeur(ifstream& inputFile, TypeDonnee& type) string LectureChoix(ifstream& inputFile) vector<RelationPremisse> LectureContexte(ifstream& inputFile) vector<Comparaison> LectureComparaison(ifstream& inputFile, TypeDonnee& type) vector<RelationPremisse> LectureRelationPremisse(ifstream& inputFile) RegleInit* LectureRegleInit(ifstream& inputFile, RelationInit* relInit) RegleChoix* LectureRegleChoix(ifstream& inputFile, string choix) |
|
Trace |
|
contexte : vector<RelationPremisse> |
|
virtual string Type() const |
|
TraceInit : Trace |
TraceChoix : Trace |
|
|
nomArgument : string mauvaiseValeur : Valeur* bonneValeur : Valeur* regleFausse : RegleInit* |
mauvaisChoix : string bonChoix : string regleFausse : RegleChoix* |
|
|
string Type() const |
string Type() const |
On trouvera en annexe 9 des schémas de déroulement du programme.
Nous avons effectué des tests à partir de traces d’exécution " artificielles ", visant à explorer toutes les possibilités que le programme est capable de traiter.
Quelques fichiers traces, paramètres et résultats qui ont servis pour les tests ou qui en sont les résultats sont en annexe 10.
Après quelques mises au point, les tests sont concluants.
Au moment où ce rapport est rédigé, ont été implantés et testés avec succès les modules suivants :
Reste donc à implanter et tester la résolution des conflits.
Tous les calculs liés aux écarts relatifs qui découlent de choix arbitraires peuvent être remplacés aisément par d’autres calculs. Ces calculs sont regroupés dans le fichier gendef.h.
Les prémisses " <> " (différent de) dans les cas numériques ne sont pas prises en compte dans la généralisation. En effet, la façon de généraliser fait que les deux intervalles définis par cette relation sont systématiquement " recollés ". On pourrait envisager de traiter cela autrement. Par exemple, on peut garder ces prémisses en dehors de la généralisation et les reprendre en compte à la fin en les ajoutant simplement aux prémisses de la nouvelle règle générale.
D’autres modifications de principe sont évidemment envisageables.
Elles peuvent porter sur divers aspects.
Nous nous sommes en effet limités à des types de règles bien particulières.
On ne gère pas par exemple, pour le moment, les valeurs numériques discrètes et les intervalles de valeurs symboliques. Leur gestion peut-être simplement prise en compte en implantant un module de conversion symbolique – numérique et numérique – symbolique (les valeurs numériques discrètes peuvent être assimilées à des valeurs symboliques) et tout traiter comme des valeurs numériques " continues ".
D’autres améliorations sont envisageables.
Comme bilan, nous pouvons représenter les deux programmes intégrés dans le système de pilotage complet :
Bien que non encore intégré dans son environnement final, le programme donne des résultats, sur le plan fonctionnel, qui sont satisfaisants. Le programme est implanté d’une façon qui se veut potentiellement évolutive, et peut donc se généraliser et intégrer de nouvelles fonctions sans trop de difficultés.
Quant à moi, ce stage m’a permis de découvrir quelques domaines comme l’intelligence artificielle, le pilotage de programmes, le génie logiciel et de pratiquer de façon relativement intensive la programmation en C++. Grâce à ce stage, j’ai donc pu retrouver le plaisir de programmer, ce que je n’avais pas vraiment eu l’occasion de faire depuis longtemps.
Les domaines que j’ai abordé plus ou moins succinctement, notamment l’informatique et l’intelligence artificielle, m’ont donné envie de m’attarder sur ces sujets, par l’entremise d’un éventuel DEA suivi d’une thèse, si j’en ai la possibilité. Côtoyer les chercheurs d’ORION m’a en effet permis de confirmer que les domaines applicatifs de ces sciences sont très étendus, ce qui multiplie encore leur intérêt.
ANNEXES
1 ANNEXE : Les moyens humains et financiers de l’INRIA. *
2 ANNEXE : Arbre des tâches. *
3 ANNEXE : Programme de description symbolique. *
4 ANNEXE : Schéma UML du programme de description de courbes avant modification. *
5 ANNEXE : Schéma UML du programme de description de courbes après modification. *
6 ANNEXE : Programme de " regroupement ". *
7 ANNEXE : Programme de " voisinage ". *
8 ANNEXE : Schéma UML courant du programme d’apprentissage. *
9 ANNEXE : Déroulement du programme d’apprentissage. *
10 ANNEXE : Tests du programme d’apprentissage. *
(Tableaux extraits du rapport annuel de l'INRIA pour 1997)
(Personnes physiques présentes au 31 décembre 1997)
|
Chercheurs : Directeurs de recherche Chargés de recherche |
307 128 179 |
|
Ingénieurs, techniciens, administratifs Ingénieurs de recherche Ingénieurs d'études Assistants-ingénieurs Techniciens de recherche Adjoints techniques Agents techniques Chargés d'administration de la recherche Attachés d'administration de la recherche Secrétaires d'administration de la recherche Adjoints d'administration de la recherche |
385 98 62 47 83 28 6 2 14 34 11 |
|
TOTAL |
692 |
(Hommes/année - chiffres pour 1997)
|
Boursiers de recherche Boursiers MENRT complémentés Boursiers à l'étranger Coopérants service national à l'étranger Boursiers post-doctoraux Boursiers PDI (post-doctoraux industriels) Boursiers HCM Stagiaires de recherche Boursiers et stagiaires de recherche étrangers (CIES) Ingénieurs experts Conseillers scientifiques et conseillers extérieurs Invités Collaborateurs extérieurs Vacataires Agents temporaires Contrats emploi-solidarité Contrats emploi-consolidés Apprentis |
99 46 16 3 16 8 7 51 70 108 31 5 26 36 31 8 19 3 |
|
TOTAL |
583 |
Dans les trois tableaux suivants, l'abréviation ITA signifie ingénieurs, techniciens et administratifs.
|
ANNÉE |
CHERCHEURS |
ITA |
TOTAL* |
|
1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 |
194 206 213 220 233 246 258 272 292 304 315 325 327 |
306 319 321 327 334 346 356 368 380 385 389 388 388 |
500 525 534 547 567 592 614 640 672 689 704 713 715 |
* y compris les 3 emplois fonctionnels.
(Personnes physiques présentes au 31 décembre 1997)
|
Scientifiques |
(dont doctorants) |
ITA/CDD |
Total |
|
|
Unité de recherche de Lorraine Unité de recherche de Rennes Unité de recherche de Rhône-Alpes Unité de recherche de Rocquencourt Unité de recherche de Sophia Antipolis Siège, Ucis *, activités transversales |
256 246 260 330 338 116 |
86 111 103 93 93 14 |
60 74 53 137 73 150 |
316 320 313 467 411 266 |
|
TOTAL |
1 546 |
500 |
547 |
2 093 |
* Unité de communication et information scientifique.
(Chiffres pour 1997)
|
THÈMES ET SERVICES |
EFFECTIFS SUR POSTE INRIA |
|
|
CHERCHEURS |
ITA |
|
|
59 55 71 85 |
11 12 16 15 |
|
Actions de développement Soutien informatique aux unités de recherche |
9 3 |
16 87 |
|
Sous-total |
282 |
157 |
|
Direction Services communs nationaux, informatique Administration du siège Administration des unités de recherche (y compris les services des relations extérieures) Services généraux, approvisionnements, courrier, entretien, restaurant Association œuvres sociales Unité de communication et information scientifique Documentation |
21 1 1
2 |
13 4 47 80 38 3 27 24 |
|
Sous-total |
25 |
236 |
|
Total général |
307 |
393 |
(Données en MF - TTC)
|
ANNÉE |
A) DÉPENSES DE PERSONNEL |
B) BUDGET TOTAL |
RAPPORT A/B |
|
1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 |
151,8 154,25 169 185,666 210,968 234,301 254,474 267,799 278,337 300,078 307,98 |
327,268 347,067 378,375 379,297 447,244 469,089 477,973 515,974 536,631 581,754 583,5 |
46% 44% 45% 49% 47% 50% 53% 52% 52% 51% 52% |
Programme qui, à partir d’une liste de nombres, retourne une liste de groupes de nombres " proches ".
On a une liste de n points, soit (x1, … xn).
Pour chacun de ces points, on construit 2 intervalles (l’un ayant le point considéré comme maximum et l’autre comme minimum), de largeur relative k ( kÎ [0,2[ ) paramétrable, c’est à dire que pour un point xi considéré, on a les deux intervalles [ai,xi] et [xi,bi] tels que :
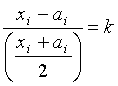 et
et 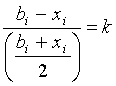
Pour chaque intervalle : on réduit ses bornes de manière à ce que son minimum soit le plus petit des points (xj) de la liste qu’il contient, et à ce que son maximum soit le plus grand des points (xk) de la liste qu’il contient. Cela permet de supprimer ensuite les intervalles en double. Ainsi, aucun point n’appartient à plusieurs intervalles.
Pour chaque intervalle restant (de la forme [xj,xk]),
on calcule un " indice de valeur " ![]() où
où
![]() est le nombre de points que contient
l’intervalle et
est le nombre de points que contient
l’intervalle et ![]() la variance de
ces points.
la variance de
ces points.
a et b sont des paramètres.
On garde de côté l’intervalle ayant le meilleur " indice de valeur " et on supprime ses points de la liste. On recommence jusqu’à ne plus avoir aucun point.
Exemple d’intérêt des paramètres sur les groupes finalement obtenus, avec un k fixé :
L’utilisation de la variance permet d’obtenir des groupes plus cohérents.
a =1
b =0
a =1
b =1
On obtient ainsi une liste de groupes ne contenant que des nombres proches d’écart relatif majoré par k.
On détaille ci-après les calculs de variance et moyenne employés dans les algorithmes.
La moyenne : 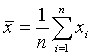 (1)
(1)
La variance : 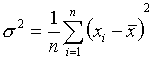 (2)
(2)
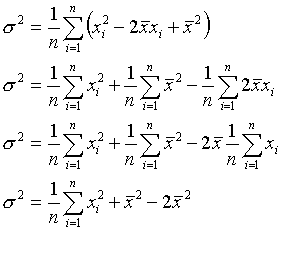
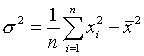 (3)
(3)
Dans l’algorithme, on calcul en fait le moyenne et la variance de la façon suivante :
On a une liste de n nombres dont on connaît
les moyenne ![]() et variance
et variance![]() .
On ajoute à cette liste un
.
On ajoute à cette liste un ![]() nombre,
nombre,
![]() .
.
Les nouvelles moyenne et variance sont : (d’après les formules (1) et (3))
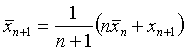
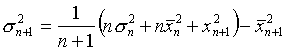
Détails des calculs :
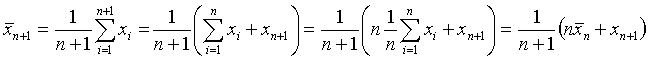

Programme qui, à partir d’une liste d’intervalles de validité, retourne une liste réduite d’intervalles de validité et leur pertinence.
On a une liste de points et d’intervalles de validité.
On convertit tout en intervalles, un intervalle étant éventuellement donc réduit à un point.
On " élargit " ces intervalles en ajoutant à gauche (resp. à droite) l’écart relatif permis par rapport à la borne minimum (resp. maximum).
Illustration pour un intervalle :
On part de l’intervalle [a,b] et on obtient l’intervalle [xa,xb] tel que :
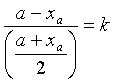 et
et 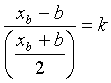 ,
,
k ( kÎ [0,2[ ) étant l’écart relatif autorisé.
On concatène ensuite tous les intervalles élargis qui se chevauchent pour former n intervalles plus grands.
On juge ensuite de la pertinence de ces intervalles avec le critère suivant : si on tolère l’existence de nb intervalles pertinents, un intervalle doit contenir au moins nbmin éléments (un élément étant un intervalle de départ) et majorité / nb % des éléments pour être jugé pertinent. Si nb = 1, seule la notion de majorité est prise en compte.
CHOIX
[Contexte]
entier entvar1 3
entier entvar2 2
entier entvar3 3
entier entvar4 16
flottant flotvar1 1.2
flottant flotvar2 1.5
flottant flotvar3 3.6
flottant flotvar4 4.7
symbolique contraste faible
symbolique taille petite
[Choix]
use operateur op1 [finMauvaisChoix]
use operateur op2 [finBonChoix]
[RegleFausse]
nomregle1
NomOperateur
[Comparaison]
entier entvar1
< 4
> 1
[Comparaison]
entier entvar2
> 1
[Comparaison]
entier entvar3
< 5
[Comparaison]
entier entvar4
> 15
< 18
[finTraceChoix]
CHOIX
[Contexte]
entier entvar1 5
entier entvar2 5
entier entvar3 7
entier entvar4 0
flottant flotvar1 5.2
flottant flotvar2 15.5
flottant flotvar3 3.75
flottant flotvar4 4.7
symbolique contraste faible
symbolique taille grande
[Choix]
use operateur op1 [finMauvaisChoix]
use operateur op2 [finBonChoix]
[RegleFausse]
nomregle2
NomOperateur
[Comparaison]
entier entvar1
< 4
> 1
[Comparaison]
entier entvar2
> 4
[Comparaison]
entier entvar3
> 4
[Comparaison]
entier entvar4
< 1
[Comparaison]
flottant flotvar1
<> 1
[finTraceChoix]
[FIN]
PARAMETRES 1
nomFichierTrace trace1
nomFichierSortie base1
Ecart_relatif_toléré_pour_les_groupes 1
Importance_du_nombre_d'éléments_par_groupe 5
Importance_de_la_variance_des_éléments_par_groupe 1
Ecart_relatif_toléré_pour_les_voisinages 1
définition_de_la_Majorité .9
nombre_max_d'intervalles_pour_une_prémisse_pertinente 3
nombre_min_d'éléments_pour_accepter_un_intervalle 0
PARAMETRES 1bis
nomFichierTrace trace1
nomFichierSortie base1bis
Ecart_relatif_toléré_pour_les_groupes 1
Importance_du_nombre_d'éléments_par_groupe 5
Importance_de_la_variance_des_éléments_par_groupe 1
Ecart_relatif_toléré_pour_les_voisinages 1
définition_de_la_Majorité .9
nombre_max_d'intervalles_pour_une_prémisse_pertinente 3
nombre_min_d'éléments_pour_accepter_un_intervalle 2
BASE1
BASE DE REGLES
- Règles apprises spécifiques :
*** DEBUT REGLE CHOIX ***
Nom : nomregle1_RS_0
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 1
entvar3 < 5
entvar4 > 15 < 18
flotvar1 == 1.2
flotvar2 == 1.5
flotvar3 == 3.6
flotvar4 == 4.7
taille == petite
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
*** DEBUT REGLE CHOIX ***
Nom : nomregle2_RS_1
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 4
entvar3 > 4
entvar4 < 1
flotvar1 <> 1
flotvar2 == 15.5
flotvar3 == 3.75
flotvar4 == 4.7
taille == grande
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
- Règles apprises générales :
*** DEBUT REGLE CHOIX ***
Nom : nomregle1_RG_0
Règles spécifiques sources :
- nomregle1_RS_0
- nomregle2_RS_1
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 1
entvar4 > 15 < 18
flotvar1 == 1.2
flotvar2 == 15.5
flotvar3 >= 3.6 <= 3.75
flotvar4 == 4.7
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
*** DEBUT REGLE CHOIX ***
Nom : nomregle1_RG_1
Règles spécifiques sources :
- nomregle1_RS_0
- nomregle2_RS_1
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 1
entvar4 < 1
flotvar1 == 1.2
flotvar2 == 15.5
flotvar3 >= 3.6 <= 3.75
flotvar4 == 4.7
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
*** DEBUT REGLE CHOIX ***
Nom : nomregle1_RG_2
Règles spécifiques sources :
- nomregle1_RS_0
- nomregle2_RS_1
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 1
entvar4 > 15 < 18
flotvar1 == 1.2
flotvar2 == 1.5
flotvar3 >= 3.6 <= 3.75
flotvar4 == 4.7
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
*** DEBUT REGLE CHOIX ***
Nom : nomregle1_RG_3
Règles spécifiques sources :
- nomregle1_RS_0
- nomregle2_RS_1
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 1
entvar4 < 1
flotvar1 == 1.2
flotvar2 == 1.5
flotvar3 >= 3.6 <= 3.75
flotvar4 == 4.7
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
- Règles expertes :
FIN DE LA BASE DE REGLES
BASE1bis
BASE DE REGLES
- Règles apprises spécifiques :
*** DEBUT REGLE CHOIX ***
Nom : nomregle1_RS_0
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 1
entvar3 < 5
entvar4 > 15 < 18
flotvar1 == 1.2
flotvar2 == 1.5
flotvar3 == 3.6
flotvar4 == 4.7
taille == petite
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
*** DEBUT REGLE CHOIX ***
Nom : nomregle2_RS_1
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 4
entvar3 > 4
entvar4 < 1
flotvar1 <> 1
flotvar2 == 15.5
flotvar3 == 3.75
flotvar4 == 4.7
taille == grande
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
- Règles apprises générales :
*** DEBUT REGLE CHOIX ***
Nom : nomregle1_RG_0
Règles spécifiques sources :
- nomregle1_RS_0
- nomregle2_RS_1
Opérateur : NomOperateur
Prémisses :
contraste == faible
entvar1 > 1 < 4
entvar2 > 1
flotvar3 >= 3.6 <= 3.75
flotvar4 == 4.7
Conclusion :
use operateur op2
*** FIN REGLE CHOIX ***
- Règles expertes :
FIN DE LA BASE DE REGLES
INITIALISATION
[Contexte]
entier largeur 2
symbolique contraste fort
symbolique taille grande
[Parametre]
flottant seuil 1 2
[RegleFausse]
rinit1
Operateur1
[Comparaison]
entier largeur
> 1
< 4
[Comparaison]
symbolique contraste
== fort
[finTraceInit]
INITIALISATION
[Contexte]
entier largeur 3
symbolique contraste fort
symbolique taille grande
[Parametre]
flottant seuil 1 2.3
[RegleFausse]
rinit2
Operateur1
[Comparaison]
entier largeur
> 1
< 5
[finTraceInit]
INITIALISATION
[Contexte]
entier largeur 4
symbolique contraste fort
symbolique taille grande
[Parametre]
flottant seuil 1.5 6.2
[RegleFausse]
rinit3
Operateur1
[Comparaison]
entier largeur
> 2
[finTraceInit]
[FIN]
PARAMETRES 2
nomFichierTrace trace2
nomFichierSortie base2
Ecart_relatif_toléré_pour_les_groupes 1
Importance_du_nombre_d'éléments_par_groupe 5
Importance_de_la_variance_des_éléments_par_groupe 1
Ecart_relatif_toléré_pour_les_voisinages 1
définition_de_la_Majorité .9
nombre_max_d'intervalles_pour_une_prémisse_pertinente 3
nombre_min_d'éléments_pour_accepter_un_intervalle 0
PARAMETRES 2BIS
nomFichierTrace trace2
nomFichierSortie base2bis
Ecart_relatif_toléré_pour_les_groupes 1.9
Importance_du_nombre_d'éléments_par_groupe 1
Importance_de_la_variance_des_éléments_par_groupe 0
Ecart_relatif_toléré_pour_les_voisinages 1
définition_de_la_Majorité .9
nombre_max_d'intervalles_pour_une_prémisse_pertinente 3
nombre_min_d'éléments_pour_accepter_un_intervalle 0
BASE2
BASE DE REGLES
- Règles apprises spécifiques :
*** DEBUT REGLE INIT ***
Nom : rinit1_RS_0
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 1 < 4
taille == grande
Conclusion :
seuil = 2
*** FIN REGLE INIT ***
*** DEBUT REGLE INIT ***
Nom : rinit2_RS_1
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 1 < 5
taille == grande
Conclusion :
seuil = 2.3
*** FIN REGLE INIT ***
*** DEBUT REGLE INIT ***
Nom : rinit3_RS_2
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 2
taille == grande
Conclusion :
seuil = 6.2
*** FIN REGLE INIT ***
- Règles apprises générales :
*** DEBUT REGLE INIT ***
Nom : rinit1_RG_0
Règles spécifiques sources :
- rinit1_RS_0
- rinit2_RS_1
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 1 < 5
taille == grande
Conclusion :
seuil = 2.15
*** FIN REGLE INIT ***
- Règles expertes :
FIN DE LA BASE DE REGLES
BASE2bis
BASE DE REGLES
- Règles apprises spécifiques :
*** DEBUT REGLE INIT ***
Nom : rinit1_RS_0
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 1 < 4
taille == grande
Conclusion :
seuil = 2
*** FIN REGLE INIT ***
*** DEBUT REGLE INIT ***
Nom : rinit2_RS_1
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 1 < 5
taille == grande
Conclusion :
seuil = 2.3
*** FIN REGLE INIT ***
*** DEBUT REGLE INIT ***
Nom : rinit3_RS_2
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 2
taille == grande
Conclusion :
seuil = 6.2
*** FIN REGLE INIT ***
- Règles apprises générales :
*** DEBUT REGLE INIT ***
Nom : rinit1_RG_0
Règles spécifiques sources :
- rinit1_RS_0
- rinit2_RS_1
- rinit3_RS_2
Opérateur : Operateur1
Prémisses :
contraste == fort
largeur > 1
taille == grande
Conclusion :
seuil = 3.5
*** FIN REGLE INIT ***
- Règles expertes :
FIN DE LA BASE DE REGLES