6p-3 is a program which enable to compute the solutions of the forward kinematics of 6-3 parallel robot with a planar base.
The problem is reduced to solving a 8th order polynomial.
Free source codes are available under Free Software Society conventions through anonymous ftp (download here).
This software is provided "as is" without warranty of any kind. In no event shall INRIA be liable for any loss of profits, loss of business, loss of use or data, interruption of business, or for indirect, special, incidental, or consequential damages of any kind, arising from any error in this software. No commercial use of this software can be made without the previous agreement of INRIA. The use of this software for any publication should acknowledged the contribution of INRIA.
Window system: none
Type: sources
Language: C
Number of lines: 2166
Size of binary: 1.14 Mo
Output: results, files, graphic output in xjpdraw format
6p-3 is a program which enable to compute the solutions of the forward kinematics of 6-3 parallel robot with a planar base.
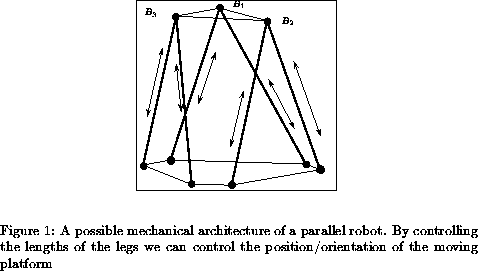
For the forward kinematics the mechanism is equivalent to a 3-(RS) mechanism.
The 3-(RS) mechanism is constituted of a base and a moving platform, which is a triangle. Each vertex of this triangle is connected to the ground by a fixed length link which is attached to the platform by a ball-and-socket joint. The other extremity of the link is connected to the ground through a revolute joint (figure 2).
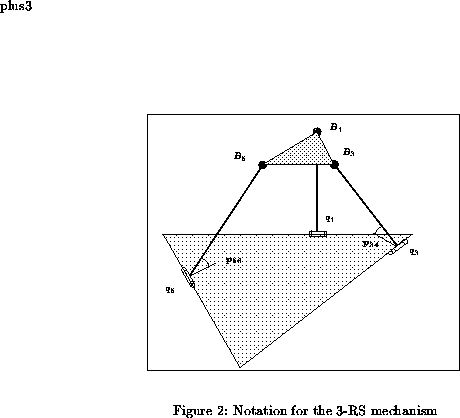
The angles between the links and the base are denoted p12, p34, p56.
6p-3 enables to solve the forward kinematics problem. Such robot is defined in a mechanism file which contain the following data:
xa1 ya1 za1 xa2 ya2 za2 ........ xb1 yb1 zb1 xb2 yb2 zb2 .........Where xai,yai,zai are the coordinates of points Ai, xbi, ybi, zbi are the coordinates of points Bi (zbi should be 0 and B1=B6, B3=B2, B5=B4).
Note that such file is compatible with the visualization program visu_robot also available via ftp.
The resolution of the forward kinematics is done by computing a 8th order polynomial in the square of tan(p34/2). Then the other angles are determined, from which is deduced the posture of the platform.
You run the program with the name of a robot file as an argument.
The program will ask you to define a posture of the robot. The leg lengths for this posture are computed and are assumed to be the leg lengths for the forward kinematics. Then you enter in the following menu:
you want to : compute the value of the polynomial for a given position-----> 1 see the algebraic form of the polynomial -------------------> 2 create a xjpdraw file of the polynomial ---------------------> 3 recompute the coefficients of the polynomial-----------------> 4 put the coefficients of the polynomial in a file-------------> 5 the angles and postures -------------------------------------> 6 the solution closest to a given posture----------------------> 7 the number of roots of the polynomial------------------------> 8 the angles and postures for given leg lengths----------------> 9 quit ----- --------------------------------------------------> -1Using 1 the program will display the value of the polynomial for a given p34.
Using 2 the program will display the polynomial in algebraic form.
Using 3 the program will create a xjpdraw format file describing the polynomial (xjpdraw is a drawing editor which is available from INRIA via anonymous ftp).
Using 4 you may give another initial posture for the forward kinematics.
Using 5 the program will write the coefficinet of the polynomial in a file.
Using 6 the program solve the forward kinematics (you should therefore find your initial position among the solutions).
Using 7 the program solve the forward kinematics and display the closest solution to a given posture.
Using 8 the program give the number of solution postures.
Using 9 the program will ask you 6 leg lengths and then solve the forward kinematics.
DATE