

220 sounding particles
(.avi divx 11Mb)
Red dots represent target directions for each particle in the HRTF azimuth-elevation map.
(.avi divx 12Mb)
Efficient 3D Audio Processing on the GPU
E. Gallo and N. Tsingos / REVES - INRIA
Introduction
The widespread availability and increasing processing power of GPUs could offer an alternative solution. GPU features, like multiply-accumulate instructions or multiple execution units, are similar to those of most DSPs used for audio processing [4,9]. Besides, 3D audio rendering applications require a significant number of geometric calculations, which are a perfect fit for the GPU. Our feasibility study investigates the use of GPUs for efficient audio processing.
We consider a combination of two simple operations commonly used for 3D audio rendering: variable delay-line and filtering. The signal of each sound source is first delayed by the propagation time of the sound wave. This involves resampling the signal at non-integer index values and automatically accounts for Doppler shifting.
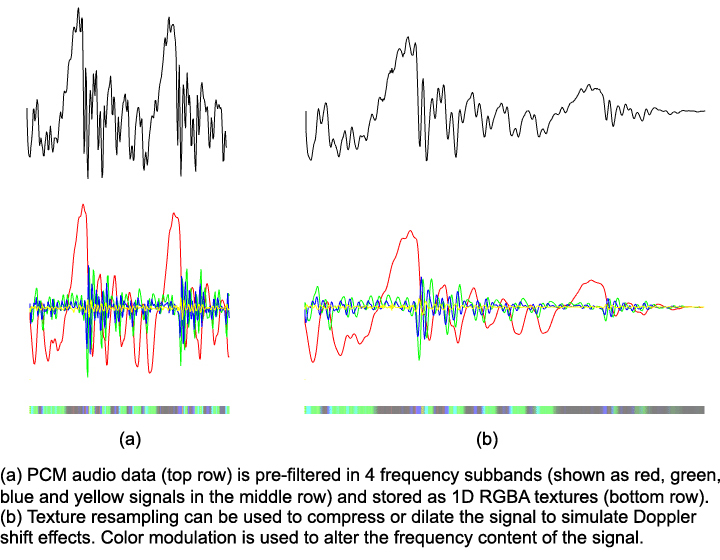
The signal is then filtered to simulate the effects of source and listener directivity functions, occlusions and propagation through the medium. For more information on audio rendering see for example [1,5]. We resample the signals using linear interpolation between the two closest samples. On the GPU this is achieved through texture resampling. Filtering is implemented using a simple 4-band equalizer. Assuming that input signals are band-pass filtered in a pre-processing step, the equalization is efficiently implemented as a 4-component dot product. For GPU processing, we store the sound signals as RGBA textures, each component holding a band-passed copy of the original sounds.
Binaural stereo rendering requires applying this pipeline twice, using a direction-dependent delay and equalization for each ear, derived from head-related transfer functions (HRTFs) [1,8]. Similar audio processing can be used to generate dynamic sub-mixes of multiple sound signals prior to spatial audio rendering.
For instance, pre-mixing operations necessary to the perceptual rendering approach of [7] can be implemented on the GPU to reduce processor load (see [6] for details).
We compared an optimized SSE (Intel's Streaming SIMD Extensions) assembly code running on a Pentium 4 3GHz processor and an equivalent Cg/OpenGL implementation running on a nVidia GeForce FX 5950 Ultra graphics board on AGP 8x. Audio was processed at 44.1 KHz using 1024-sample long frames. All processing was 32-bit floating point.
Results
The SSE implementation achieves real-time binaural rendering of 700 sound sources, while the GPU renders up to 580 in one time-frame (about 22.5 ms). Assuming floating-point texture resampling could be done in hardware, not requiring explicit interpolation in the shader, the GPU could render up to 1050 sources.
For mono processing, the GPU treats up to 2150 (1 texture fetch) / 1200 (2 texture fetches and linear interpolation) sources, while the CPU handles 1400 in the same amount of time. On average, the GPU implementation was about 20% slower than the SSE implementation but would become 50% faster if floating-point texture resampling was supported in hardware.

A possible explanation, besides multiple SIMD execution units and memory bandwidth, for the good performance of the GPU is the use of specific instructions for dot product and linear interpolation. Such instructions are not currently part of the SSE. The latest graphics architectures are likely to significantly improve GPU performance due to their increased number of pipelines and better floating-point texture support.
The huge pixel throughput of the GPU can also be used to improve audio rendering quality without reducing frame-size by recomputing rendering parameters (source-to-listener distance, equalization gains, etc.) on a per-sample rather than per-frame basis. This can be seen as an audio equivalent of per-pixel vs. per-vertex lighting. Since fragment programs can be dynamically activated, such processing can be used only when necessary (e.g., for near-field fast moving sources). By storing directivity functions in cube-maps and recomputing propagation delays and distances on a per-sample basis, our GPU implementation can still render up to 180 sources in the same time-frame.
However, more complex texture addressing calculations are needed in the fragment program due to limited texture size. By replacing such complex texture addressing with a single texture-fetch instruction, we estimated that direct support for large 1D textures would increase performance by at least a factor of 2.
Example renderings
The following movie files demonstrate binaural 3D audio rendering on the GPU using the approach
described in the previous sections. In these examples all audio and graphics rendering is performed by the GPU
(CG/openGL implementation accelerated by a GeForce FX5950 ultra AGP8x on P4 3GHz win2k platform).
The examples sound best when listened to with headphones.
|
|
|
|
220 sounding particles |
Red dots represent target directions for each particle in the HRTF azimuth-elevation map. |
Can the GPU be a good audio DSP ?
Our first experiments suggest that GPUs can be used for 3D audio processing with similar or increased performance compared to optimized software implementations running on the latest CPUs.
GPUs have been shown to outperform CPUs for a number of other tasks, including Fast Fourier Transform, a tool widely used for audio processing [2].
However, several shortcomings still prevent the use of GPUs for mainstream audio processing applications:
Slow AGP readbacks might also become an issue when large amounts of audio data must be retrieved from graphics memory to be transfered to the audio hardware for playback. However, upcoming PCI Express support should solve this problem for most applications.
Can Audio Processing Units (APUs) benefit from graphics hardware design ?
Finally, our results support our hypothesis that game-audio hardware, borrowing from graphics architectures and shading languages, may benefit from including a programmable ``voice processor" prior to their main effects processor. The architecture of such a processor could be inspired from the GPU while high level shading languages might inspire high-level audio processing languages for future programmable APUs.
Hardware support for programmable voice shaders might open a lot more possibilities to the game audio programmer than multiplying the number of (3D) audio channels in future APUs.
References
[1] D. Begault. 3D Sound for Virtual Reality and Multimedia. Academic Press Professional, 1994.
[2] I. Buck, T. Foley, D. Horn, J. Sugerman, and P. Hanrahan. Brook for GPUs: Stream computing on graphics hardware. ACM Trans. on Graphics, Proc. of SIGGRAPH, 2004.
[3] P. Cook. Real Sound Synthesis for Interactive Applications. AK Peters, 2002.
[4] J. Eyre and J. Bier. The evolution of DSP processors. IEEE Signal Processing Magazine, 2000.
See also www.bdti.com.[5] T. Funkhouser, J.M. Jot, and N. Tsingos. Sounds good to me ! Computational sound for graphics, VR, and interactive systems. SIGGRAPH course #45, 2002.
[6] N. Tsingos, E. Gallo, and G. Drettakis.
Breaking the 64 spatialized sound sources barrier. Gamasutra Audio Resource Guide, 2003.[7] N. Tsingos, E. Gallo, and G. Drettakis.
Perceptual audio rendering of complex virtual environments. ACM Trans. on Graphics, Proc. of SIGGRAPH, 2004.[8]
The listen project HRTF database.[9] P. Lapsley and J. Bier and A. Shoham and E.A. Lee, DSP Processor Fundamentals, IEEE Press, 1997.
Related publications
GP2, ACM Workshop on General Purpose Computing on Graphics Processors ,
Los Angeles, August 2004. Abstract (pdf 22Kb). Poster (pdf 2Mb).