|
Thesis
Temporal Scenarios for Automatic Video Interpretation This Computer Science thesis was realized
by Van-Thinh Vu under the supervision of Dr. Monique Thonnat and Dr.
François Brémond at INRIA-Sophia Antipolis in France. The
thesis was defended on the 14th October 2004. The thesis was estimated
“Très Honorable” (the highest PhD graduation level in France at
that time) by an international committee.
This
thesis research focuses on the recognition
of temporal scenarios for Automatic
Video Interpretation: the goal of this work is to recognize in real-time the behaviours of
individuals evolving in a scene depicted by video sequences which were
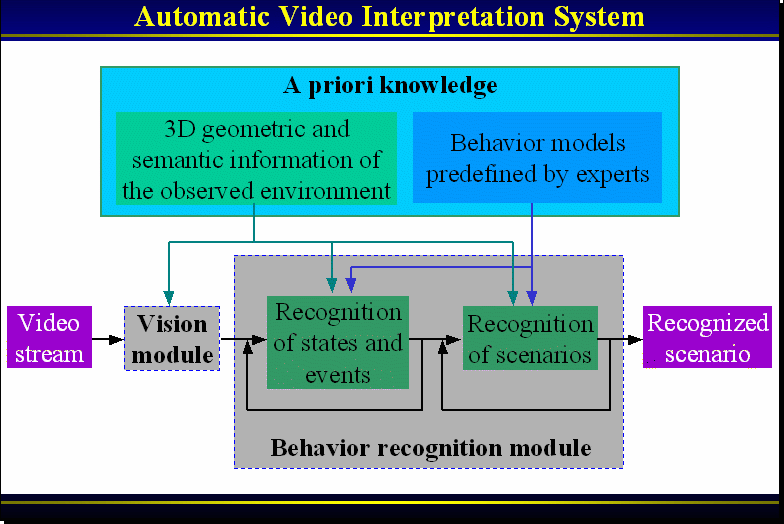
captured by cameras. The recognition process takes the following as
input: (1) human behaviour (i.e., temporal scenario) models predefined
by experts; (2) 3D geometric and semantic information of the observed
environment; and (3) a stream of individuals tracked by a vision module.
To deal with this issue, we have proposed a generic model of temporal scenarios and a description language to represent the knowledge of human behaviours. The representation of this knowledge needs to be clear, rich, intuitive and flexible. The proposed model of a temporal scenario M is composed of five components: (1) a set of physical object variables corresponding to the physical objects involved in M; (2) a set of temporal variables corresponding to the sub-scenarios composing M; (3) a set of forbidden variables corresponding to the scenarios that are not allowed to occur during the recognition of M; (4) a set of constraints (symbolic, logical, spatial and temporal constraints including Allen’s interval algebra operators) involving these variables; and (5) a set of decisions corresponding to the tasks predefined by experts that are needed to be executed when M has been recognized. We have also proposed a temporal constraint resolution technique to recognize in real-time the temporal scenario models predefined by experts. The proposed algorithm is most of the time efficient for processing temporal constraints as well as for combining several actors defined within a given scenario M. By efficient we mean that the recognition process is linear with the number of sub-scenarios and with the number of physical object variables defined within M in most cases. To validate the proposed algorithm in terms of correctness, robustness and processing time with respect to scenario and scene properties (e.g., number of sub-scenarios, number of persons in the scene), we have tested the algorithm on several videos of different applications, in both on-line and off-line modes and also on simulated data. By the experiments conducted in metro surveillance and bank monitoring applications, the proposed scenario description language shows the capability to represent easily temporal scenarios corresponding to the human behaviours of interest in these applications. Moreover, the proposed temporal scenario recognition algorithm shows the capability to recognize in real-time (at least 10 frames/second) complex scenario models (up to 10 physical object variables and 10 sub-scenario variables per scenario) with complex video sequences (up to 240 persons/frame in the scene). Click here to get the full version of the manuscript. |
 |