Projet ROBEA
Analyse du Mouvement dans des séquences d'Images par Réseaux de neurones Impulsionnels et Asynchrones
Dans cette section, nous explicitons l'approche envisagée. Le point de départ du projet est centré autour des algorithmes de traitement développés par l'équipe de Simon Thorpe inspirés des recherches sur le fonctionnement du système visuel de l'homme et du singe. Pour cette raison, nous commencerons par un exposé des origines de ces concepts et l'état de l'art actuel. L'équipe à l'INRIA Sophia-Antipolis apporte une approche mathématique et rigoureuse à l'analyse des algorithmes. La société SpikeNet Technology intervient dans la valorisation de ces recherches.
L'équipe de Simon Thorpe au Centre de Recherche Cerveau et Cognition (UMR 5549) à Toulouse étudie depuis plusieurs années la remarquable capacité des sujets humains à catégoriser des scènes naturelles. Ils ont montré que 100 à 150 ms de traitement suffisent pour décider si une image qui n'a jamais été vue auparavant contient un animal ou un moyen de transport (Fabre-Thorpe, Delorme, Marlot, & Thorpe, 2001; Thorpe, Fize, & Marlot, 1996; VanRullen & Thorpe, 2001b). Ce laps de temps est extrêmement court au regard de la lenteur relative des neurones et laisse supposer que ces traitements sont possibles dans des conditions où chaque neurone ne peut émettre qu'une seule impulsion. Pour rendre compte de cette extraordinaire rapidité, Thorpe et ses collaborateurs ont proposé un modèle du traitement qui constitue une sorte de rupture par rapport aux modèles classiques (Thorpe, Delorme, & Van Rullen, 2001; Thorpe, Delorme, VanRullen, & Paquier, 2000). Dans ce modèle, le traitement visuel implique la propagation d'une vague d'impulsions (les "spikes") à travers plusieurs couches de neurones. À chaque niveau, ce sont les neurones les plus activés qui déchargent en premier. Dans un tel système, on peut utiliser l'ordre dans lequel les neurones déchargent pour encoder des informations (VanRullen & Thorpe, 2001a). En se servant d'un logiciel de simulation de réseaux de neurones impulsionnels et asynchrones appelé "SpikeNet", Thorpe et ses collaborateurs ont pu montrer l'extrême efficacité computationnelle de cette approche. En effet, "SpikeNet" a déjà fait ses preuves dans le domaine de l'identification et de la localisation des cibles dans des images statiques et les résultats sont si convaincants qu'une société de valorisation (SpikeNet Technology SARL - www.spikenet-technology.com) a été créée avec le concours du CNRS.
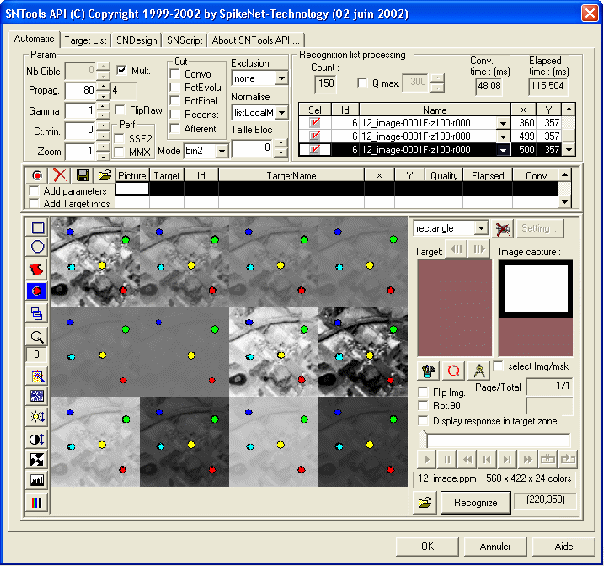
Pour donner une idée plus précise du niveau de performance que l'on peut obtenir, regardons la figure 1 qui illustre un screen-shot tiré de SNTools, logiciel développé conjointement par l'équipe de Simon Thorpe au CERCO et SpikeNet Technology. On voit les résultats d'un traitement effectué sur une image dont les dimensions sont de 560 par 422 pixels, composée d'un montage d'un bout d'image satellitaire avec plusieurs contrastes et plusieurs niveaux de luminance. L'image originale est en haut à gauche. Nous avons sélectionné cinq zones dans l'image, chacune composée d'environ 30 pixel sur 30. Ces zones ont été utilisées pour construire des "prototypes" à reconnaître en se servant d'un algorithme d'apprentissage incorporé dans le noyau SpikeNet. Ensuite, lorsque l'on traite l'image, on peut retrouver les cinq "prototypes" partout dans l'image, quel que soit le niveau de contraste localement (chaque prototype est indexé par une pastille de couleur différente sur la figure ci-dessous). Cette capacité à reconnaître des formes indépendamment des variations d'éclairage est un des points forts de SpikeNet et résulte du fait que le logiciel ne se sert pas de la valeur absolue des niveaux de gris, mais plutôt des contrastes relatifs locaux - comme pour le système visuel humain.
Figure 1 : Screen shot du logiciel SNTools, développé conjointement par l'équipe de Simon Thorpe au Centre de Recherche Cerveau et Cognition et la société SpikeNet Technology. On voit les résultats d'un traitement effectué sur une image test composée de 560*422 pixels, où une image originale est reproduite avec plusieurs contrastes et luminances. Les cinq "prototypes" sont correctement localisés, sauf dans un cas lorsque le contraste est très faible (3%). Le temps de traitement sur un Pentium 4 à 2.2 Ghz est de 115 ms.
L'autre point très intéressant de SpikeNet réside dans sa rapidité. En haut à droite de la figure, on peut voir que le temps total du traitement pour cette image, sur un ordinateur équipé d'un processeur Pentium 4 à 2.2 GHz, n'est que de 115 ms, un chiffre remarquablement bas pour une image de cette taille. Le temps de traitement dépend presque linéairement de la taille de l'image, de telle sorte que les images de petite taille peuvent être traitées facilement en temps réel sur un simple PC. De plus, le temps de traitement augmente linéairement avec le nombre de prototypes à tester. Il existe un temps de pré-traitement fixe (ici 48 ms), mais par la suite, chaque nouveau prototype à tester prend environ 22 ms. Enfin, l'utilisation de la mémoire vive est très efficace car le logiciel peut fonctionner avec seulement 32 Moctets de mémoire RAM, ouvrant ainsi des possibilités d'implémentation sur système embarqué - potentiellement très intéressant dans le domaine de la robotique. Bien évidemment, nous croyons que les applications potentielles d'une telle technologie ne manqueront pas.
Or,
jusqu'ici, les applications de SpikeNet ont concerné surtout
l'analyse d'images statiques et un des objectifs primordiaux de ce
projet est d'étendre l'approche au traitement d'images en
mouvement. L'analyse du mouvement pose un problème
particulièrement intéressant sur le plan scientifique pour
un système tel que SpikeNet. En effet, le mode de fonctionnement
de SpikeNet a jusqu'ici été basé sur une seule
vague de propagation d'activité impulsionnelle qui traverse le
système visuel. Cette solution semble bien adaptée au cas
spécifique d'une image flashée sur la rétine au
temps t, ce qui correspond à la situation
expérimentale proposée aux sujets expérimentaux
dans nos expériences sur la catégorisation visuelle. Or,
ce n'est pas particulièrement réaliste lorsque l'on
considère les stimulations dynamiques du monde qui nous entoure.
Certes, la rapidité de SpikeNet permet de concevoir des
systèmes ou chaque image est traitée
indépendamment, mais avec une telle approche, on perd de
nombreuses informations qui ne peuvent être extraites qu'à
partir d'une séquence d'images successives.
Un des exemples les plus clairs de l'utilisation des
informations dynamiques est la perception des mouvements biologiques.
Dans les années 70s, Gunnar Johannsson (1973) avait
démontré l'extraordinaire capacité des sujets
humains à interpréter le mouvement d'un nombre
limité de points éclairés ("point-light displays")
dans une action telle que la marche, le lancer d'un javelot, etc..
(voir figure 2). Chaque image prise séparément est
difficile, sinon impossible, à interpréter, montrant que
le mouvement est bien l'élément primordial de la
perception. Depuis, il a été démontré que
cette capacité remarquable permet de faire des discriminations
encore plus riches, comme déterminer le sexe d'une personne
à partir de sa façon de marcher (Kozlowski & Cutting,
1977) ou en se servant uniquement des mouvements du visage (Hill &
Johnston, 2001).
Notre capacité à comprendre presque
instinctivement ce type de mouvement est un problème
extrêmement intéressant sur le plan scientifique et un des
buts de ce projet est de reproduire ce type de performance dans des
systèmes artificiels. Le succès serait double. D'abord
nous pourrons tester notre compréhension des mécanismes
de la perception biologique. Mais en même temps, nous pourrons
valoriser nos recherches en développant des logiciels de
traitement d'images très innovants avec un potentiel commercial
déjà en place, grâce à la participation de
la société SpikeNet Technology.
Nous pouvons concevoir deux façons distinctes pour analyser une scène dynamique. La première consiste à étiqueter les objets intéressants dans chaque image l'une après l'autre. Ainsi, supposons que l'on puisse localiser un objet précis (la tête d'une personne, par exemple) dans la première image d'une séquence aux coordonnées XY de (217,117) et que, dans l'image suivante, une tête aux coordonnées (225,120) soit identifiée. On peut alors supposer que la tête a bougé entre les deux images et que sa direction de mouvement a été de 8 pixels vers la droite et 3 vers le bas. Une telle approche dépend de façon critique de la précision du processus d'étiquetage. De plus, il ne faut pas que l'image contienne trop d'objets similaires, sinon le problème classique de mise en correspondance apparaît. Cela dit, ce type d'analyse de mouvement "haut-niveau" correspond assez bien à ce que l'on appelle "long-range motion analysis" chez l'homme, et de plus, cela peut être envisagé à partir de l'architecture actuelle de SpikeNet.
La deuxième méthode, passe par une étape de traitement visant à analyser les mouvements au niveau local dans l'image et plus particulièrement en calculant le flux optique à chaque point de l'image. Une fois que ces mouvements sont analysés, nous pouvons chercher des séquences de mouvements spécifiques qui caractérisent une action donnée, sans passer par l'identification des objets concernés. C'est en effet exactement ce qui se passe dans la perception des point-light displays, car aucune forme précise n'est identifiable - ce n'est que le pattern de mouvement qui est utilisé.
Récemment, Giese et Poggio (2001, et soumission à publication) ont mis au point un modèle simplifié du système visuel qui intègre ces deux types de mécanismes. Ils ont utilisé un réseau de neurones multicouche semblable à celui développé auparavant par Reisenhuber et Poggio pour le traitement des scènes statiques (Riesenhuber & Poggio, 2002). La grande différence réside dans le fait d'utiliser deux voies de traitement indépendantes, l'une spécialisée dans l'analyse des formes et capable d'analyser chaque pose isolément et une autre spécialisée dans le traitement des mouvements seuls. Ce découpage trouve sa justification dans l'organisation des voies visuelles chez le primate où la distinction entre traitement des formes et du mouvement se manifeste dans l'organisation des aires visuelles extra-striées. Le fait d'utiliser deux voies indépendantes donne une robustesse supplémentaire au système lui permettant d'interpréter à la fois des poses isolées et des patterns de mouvements primitifs.
Le modèle de Giese et Poggio est très intéressant, mais reste au niveau de démonstration car il ne fonctionne qu'avec des images artificielles de petite taille et composée de formes dessinées avec des traits. De plus, leur système n'est pas prévu pour une utilisation "temps réel". Une des raisons pour cela est leur choix d'utiliser des neurones avec une activité continue, comme dans la quasi-totalité des réseaux de neurones artificiels. Nous avons trouvé que cette approche est computationnellement peu efficace comparativement à la rapidité impressionnante de SpikeNet qui s'affranchit de cette contrainte. Donc, un premier objectif de ce projet sera de proposer une version impulsionnelle et asynchrone du modèle développé par Giese et Poggio. Cette partie du projet sera faite en étroite collaboration avec Martin Giese, récemment installé à Tübingen en Allemagne.
Une autre faiblesse du modèle de Giese et Poggio tient au fait que le calcul du flux optique utilisé dans la voie neuronale spécialisée dans l'analyse des mouvements, n'a pas été implémenté explicitement. Des informations prétraitées ont simplement été fournies au réseau. Or, avec SpikeNet, nous avons déjà travaillé sur une version spécifiquement adaptée à l'analyse du flux optique lors d'un stage de DEA (Paquier & Thorpe, 2000), mais aujourd'hui il faut mettre ce travail préliminaire en phase avec les dernières innovations du noyau SpikeNet. Dans la version standard de SpikeNet, la première étape de traitement implique la convolution de l'image en entrée avec un opérateur de type "chapeau mexicain" pour simuler l'action des cellules "ON-" et "OFF-center" de la rétine, mais dans un tel schéma, chaque image est traitée de façon indépendante. Pour prendre en compte les aspects dynamiques de l'image, nous avons envisagé l'ajoute d'une autre famille de neurones dans la "rétine" qui eux sont sensibles aux changements de niveau de luminance entre deux images successives. Deux types de cellules sont implémentées - l'un répondant lorsque la luminance augmente entre deux images (Transient-ON ou T-ON), l'autre répondant avec des baisses de luminances (Transient-OFF ou T-OFF).
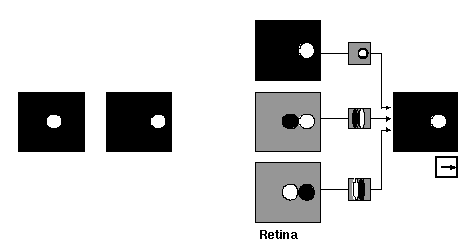
Figure 3: Illustration de l'architecture développée par Paquier et Thorpe (2000) pour détecter la direction du mouvement dans une séquence composée de deux images successives.
En spécifiant un jeu de connexions entre les différentes familles de cellules rétiniennes et les neurones du niveau supérieur, on peut obtenir des neurones sélectifs à une direction de mouvement. A la figure 3, on illustre comment le mouvement d'un point lumineux se déplaçant vers la droite activerait une combinaison d'activité dans les cellules ON, T-ON et T-OFF, cette combinaison permettant d'activer des neurones au niveau de V1, sélectif donc au mouvement de points clairs vers la droite. En dupliquant le même type de connectivité pour différentes directions de mouvements et pour différentes polarités de luminance, nous avons pu mettre au point tout un ensemble de cartes corticales capable de signaler des mouvements dans 8 directions différentes. Ensuite, les réponses des cartes spécialisées pour les deux polarités sont combinées au niveau suivant pour obtenir des réponses sélectives à la direction, indépendamment de la polarité.
Enfin, nous avons utilisé l'activité des neurones dans ces huit cartes directionnelles pour construire des cartes sélectives à des mouvements complexes, telles des rotations, des expansions (positive ou négative) et deux types de déformations. Ces premières expériences ont été très encourageantes et la figure 4 illustre comment un tel système peut localiser le centre de rotation dans une séquence vidéo où l'on voit un disque en train de tourner.
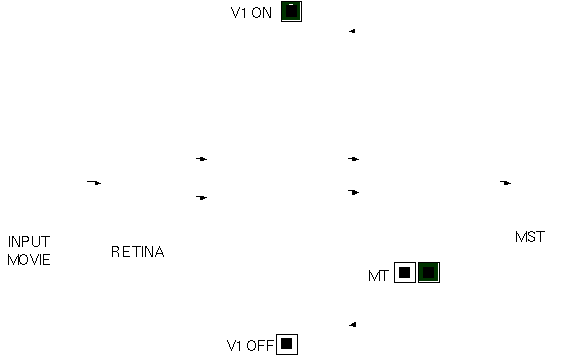
Figure 4 : Activité des différentes cartes de neurones dans le modèle d'analyse du flux optique basé sur SpikeNet et développé par Paquier et Thorpe (2000). Les images en entrée sont d'abord analysées par des neurones ON-center, OFF-center, Transient-ON et Transient-OFF de la rétine. Les spikes générés par ces cartes déclenchent de l'activité dans des cartes sélectives au mouvement dans 8 directions différentes au niveau de V1. À ce niveau, les points de polarité différente sont traités par des cartes différentes (V1-ON et V1-OFF), mais ces informations sont regroupées au niveau suivant (équivalent de l'aire MT chez le singe). Enfin, des neurones au niveau de MST sont sélectifs à des mouvements complexes comme des expansions, des rotations et des déformations.
Or, depuis 1999, la version "statique" de SpikeNet a été améliorée en terme de vitesse de traitement ainsi que de résistance au bruit et aux variations d'éclairage. Donc, un des buts de ce projet est de produire une nouvelle version pour traiter le flux optique prenant en compte les améliorations récentes. De plus, nous souhaiterions explorer d'autres implémentations "biologiquement plausibles" des algorithmes de traitement du flux optique, et ceci en étroite collaboration avec l'équipe de l'INRIA dont les compétences en vision algorithmique sont reconnues.
Fabre-Thorpe, M., Delorme, A., Marlot, C., & Thorpe, S. (2001). A limit to the speed of processing in ultra-rapid visual categorization of novel natural scenes. J Cogn Neurosci, 13(2), 171-180.
Paquier, W., & Thorpe, S. J. (2000). Motion Processing using One spike per neuron. Proceedings of the Computational Neuroscience Annual Meeting, Brugge, Belgium.
Thorpe, S., Delorme, A., & Van Rullen, R. (2001). Spike-based strategies for rapid processing. Neural Networks, 14(6-7), 715-725.
Thorpe, S., Fize, D., & Marlot, C. (1996). Speed of processing in the human visual system. Nature, 381(6582), 520-522.
Thorpe, S. J., Delorme, A., VanRullen, R., & Paquier, W. (2000). Reverse engineering of the visual system using networks of spiking neurons, Proceedings of the IEEE 2000 International Symposium on Circuits and Systems (Vol. IV, pp. 405-408): IEEE press.
VanRullen, R., & Thorpe, S. J. (2001a). Rate coding versus temporal order coding: what the retinal ganglion cells tell the visual cortex. Neural Comput, 13(6), 1255-1283.
VanRullen, R., & Thorpe, S. J. (2001b). The time course of visual processing: from early perception to decision- making. J Cogn Neurosci, 13(4), 454-461.
Viéville T., Crahay S, 2002, A deterministic biologically plausible classifier. INRIA Research Report, 4489
Viéville T., Crahay S, 2003, A deterministic biologically plausible classifier. Journal of Computational Neuroscience, (in review).
Viéville T., Crahay S, 2003, A deterministic biologically plausible classifier. Computational Neuroscience Meeting, Elevier, in press.
Viéville T., 2003, SVM et modèle biologique de reconnaissance visuelle, Journées thématique "Support Vector Machines et méthodes ànoyau", ENST, Paris
Giese MA, Poggio T (2000): Morphable models for the analysis and synthesis of complex motion patterns. International Journal of Computer Vision, 38 (1), 59-73.
Giese MA, Lappe M (2001): Measurement of generalization fields for the recognition of biological motion. Vision Researech, (in press).
Giese MA Poggio T (2001): Neural mechanisms for the recognition of biological movements and actions. (submitted to Nature, under review).