3 Développement du robot
3.1 Le robot Web Stator
Dans le cadre du projet de D.E.A., le sujet est de savoir s'il
existe une politique de mise à jour des pages WEB. Pour cela, le but
premier est de développer un robot qui effectuerait une visite des
sites WEB (comme tout moteur de recherche) et qui, pour chaque page
visitée, regarderait la date de dernière modification. Ainsi, il sera
possible de faire une analyse, en fonction des résultats obtenus, de
la fréquence de mises à jour des pages HTML et des sites WEB en
général.
3.1.1 World Wide Web Consortium
Le développement complet d'un moteur de recherche était donc la
première étape du stage. Les recherches de W3 Consortium ont permis de
rendre le travail plus facile. En effet, W3C [13]
propose un ensemble
de librairies gratuites permettant la navigation sur le Web. Ce moteur
est reconnu, et ne risque pas de poser de problèmes de politesse au
niveau des accès aux sites Web.
En fait, W3C offre une bibliothèque dans le langage C contenant des
fonctions et des structures de travail sur le World Wide Web. Ainsi,
il donne un squelette et laisse aux adaptateurs du robot le
soin de programmer certaines fonctions qui permettent d'obtenir un
travail spécifique.
3.1.2 Le parcours du robot
L'utilisateur spécifie une adresse. Le déroulement est ensuite
simple. Le robot crée une connection TCP sur le serveur passé en
paramètre et lui envoie le chemin de la page voulue. Ce serveur, comme
dans tout protocole HTTP, retourne une chaîne de caractère, contenant
des informations sur le document et les données HTML, si la page
existe. Dans le cas contraire, une chaîne d'erreur (un fichier par
défaut) est envoyée au client. La connection est ensuite cassée par le
serveur. Une fois que le robot à récupérer les données, il va pouvoir
commencer la lecture de la page. Il analyse tout le document (étape de
parsing) qu'il a transféré. Dans un premier temps, il va créer des
structures contenant les informations de tête du document, tel que la
version du démon HTTP, la longueur du document, la date du passage ou
la date de dernière modification. Ensuite, sur le corps du document
(données HTML), il va créer une liste de liens référencés. A chaque
fois qu'il découvre un tag de type lien (ex: <a href=
... >) sur une nouvelle adresse, il ajoutera l'adresse dans la
liste des pages à visiter. Cette liste permettra de savoir pour chaque
adresse rencontrée, s'il s'agit d'une adresse déjà apparue auparavant,
ou une nouvelle à explorer. C'est en fait, une liste de pointeurs sur
des structures anchor (structure contenant toutes les données
relatives à un document : date de modification, longueur du document,
...), et la profondeur où a été visitée la page. Cette recherche va
durer tant que le robot n'atteint pas la profondeur spécifiée au
départ ou, tant qu'il n'a pas visité tous les liens référencés du
site. On parle de profondeur de travail, pour désigner le nombre de
lien que le robot doit suivre. Le site WEB peut être considéré comme
un arbre parcouru en largeur. Voyons l'exemple suivant de parcours du
robot.
FIGURE 4. Exemple de parcours
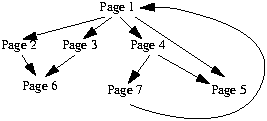
Initialisation de la liste de visite L = ()
^ représente le pointeur de liste
A chaque fin de visite d'une page le pointeur avancera dans la liste
Visite de la page 1 : L=(^1)
Référence 2 :L=(^1,2)
(travail identique pour 3,4,5)
Fin de la page 1 : L=(^1,2,3,4,5)
Visite de la page 2 : L=(1,^2,3,4,5)
Référence 6 : L=(1,^2,3,4,5,6)
Fin de la visite de la page 2 : L=(1,^2,3,4,5,6)
Visite de la page 3 : L=(1,2,^3,4,5,6)
Référence 6 : 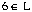 donc on ne fait rien
Fin de la visite de la page 3 : L=(1,2,^3,4,5,6)
Visite de la page 4 : L=(1,2,3,^4,5,6)
Référence 7 : L=(1,2,3,^4,5,6,7)
Référence 5 :
donc on ne fait rien
Fin de la visite de la page 3 : L=(1,2,^3,4,5,6)
Visite de la page 4 : L=(1,2,3,^4,5,6)
Référence 7 : L=(1,2,3,^4,5,6,7)
Référence 5 : 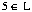 donc on ne fait rien
Fin de la visite de la page 4 : L=(1,2,3,^4,5,6,7)
Visite de la page 5 : L=(1,2,3,4,^5,6,7)
Fin de la visite de la page 5 : L=(1,2,3,4,^5,6,7)
Visite de la page 6 : L=(1,2,3,4,5,^6,7)
Fin de la visite de la page 6 : L=(1,2,3,4,5,^6,7)
Visite 7 : L=(1,2,3,4,5,6,^7)
Référence 1 :
donc on ne fait rien
Fin de la visite de la page 4 : L=(1,2,3,^4,5,6,7)
Visite de la page 5 : L=(1,2,3,4,^5,6,7)
Fin de la visite de la page 5 : L=(1,2,3,4,^5,6,7)
Visite de la page 6 : L=(1,2,3,4,5,^6,7)
Fin de la visite de la page 6 : L=(1,2,3,4,5,^6,7)
Visite 7 : L=(1,2,3,4,5,6,^7)
Référence 1 : 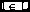 donc on ne fait rien
Fin de la visite de la page 7 : L=(1,2,3,4,5,6,^7)
L=(1,2,3,4,5,6,7^)
Parcours fini : toutes les pages ont été visitées
donc on ne fait rien
Fin de la visite de la page 7 : L=(1,2,3,4,5,6,^7)
L=(1,2,3,4,5,6,7^)
Parcours fini : toutes les pages ont été visitées
Dans le cadre du travail demandé, il n'est pas utile de parcourir
plusieurs sites puisqu'il s'agit d'analyser un site à la fois. Il
serait plus intéressant de visiter entièrement toutes les pages d'un
seule site et de relancer le robot aussi souvent qu'il y a de sites à
étudier. Si toutes les références d'une page sont visitées, avant
d'arriver au niveau n, il faudra avoir visité toutes les pages du
niveau n-1. Avec une grande profondeur, le robot risquerait de se
perdre dans des serveurs qui ne nous intéressent pas pour l'étude et,
le délai de retour dans de tel cas risque d'être très long. Il est
donc souhaitable de limiter l'accès aux pages du même serveur. Pour
cela, il ne faut plus traiter, dans les tags HTML, que les liens
symboliques (chemin par rapport à la page analysée) et les liens sur
le même serveur.
Le robot de W3C laisse plusieurs fonctions qui peuvent être
changées selon le goût du programmeur. Ainsi, il n'est pas nécessaire
de toucher à toutes les sources de la bibliothèque pour pouvoir faire
des changements sur le comportement du robot. Ses fonctions sont
appelées : à l'entrée et à la sortie d'une nouvelle url, à l'entrée et
à la sortie d'un paragraphe, d'une ligne, d'un caractère, etc ... Les
fonctions qui ont été reprises, sont HText_beginAnchor et
HText_endAppend(). La première est appelée à chaque fois, lors de
l'analyse d'un document, qu'un lien HTML est trouvé. C'est dans cette
fonction que le robot vérifie qu'il n'a pas déjà visité cette page et
si ce n'est pas le cas, il ajoute cette page dans la liste des
documents à visiter. C'est également dans cette fonction que l'on
vérifie si l'adresse trouvée ne sort pas du domaine et si l'on est
toujours dans une profondeur désirée. La deuxième fonction est appelée
lorsque le robot a analysé tout le document. A ce moment, toutes les
structures sont correctement remplies et il est possible de mettre à
jour les bases de données.
L'inconvénient majeur de ce robot est qu'il se limite aux tags
<a href=...> et que les frames ne sont pas gérées. Si
l'auteur d'un document souhaite découper le navigateur en plusieurs
fenêtre, il doit spécifier la taille et la disposition de chaque
fenêtre ainsi que le document qui sera ouvert dans chacune
d'elles. Ainsi, dans la page principale, il peut n'y avoir aucun lien
référencé.
Exemple de déclaration de frame
<FRAMESET COLS="18%,*" BORDER=0>
<FRAME SRC="blanc.htm"
MARGINHEIGHT=0
MARGINWIDTH=0
NAME="blanc"
SCROLLING = "auto">
<FRAMESET ROWS="82%">
<FRAME SRC="homepage.html"
MARGINHEIGHT=0
MARGINWIDTH=0
NAME="homepage"
SCROLLING = "auto">
</FRAMESET>
En fait, les références sont faites par les documents de chaque
frame. Actuellement, le robot ne traite pas de tel cas de page. Pour
pouvoir étudier, des sites comprenant plusieurs frames, le robot sera
lancé sur la page paraissant la plus importante. Il serait possible de
reprendre l'analyse de la page pour rajouter le tag frameset.
3.1.3 Le travail particulier de Web Stator
En fait, il faut maintenant adapté ce robot pour rapatrier toutes
les données nécessaires à l'analyse. Cette solution a été considérée
comme peu réalisable. Pour pouvoir tirer des hypothèses sur les
résultats, il faudrait déjà faire plusieurs parcours d'un même site et
suivre les mêmes liens d'une visite sur l'autre. Le problème
d'utiliser toujours le même robot pour ce parcours risque de poser le
problème suivant. Si entre deux visites, des pages sont supprimées ou
ajoutées, le parcours sera complètement différents d'un cas sur
l'autre. Et l'analyse s'en trouvera faussée. Aussi, l'utilisation de
deux robots est une meilleure solution. Le premier, dérivé de celui de
W3C, fera un parcours du site afin d'en déterminer la hiérarchie
globale du serveur étudié. Une fois, cette visite effectuée, il
mettrait à jour une base de données qui serait réutilisée pour la
suite des recherches. Le deuxième robot sera lancé sur les résultats
du premier, de façon à pouvoir suivre un processus Poisson entre les
différentes visites d'une même page. Nous verrons dans le chapitre
3.2. pourquoi et comment utiliser ce processus Poisson.
Le premier robot va être lancé sur une URL et parcourir
récursivement tout le site donné. Pour chaque adresse, il va stocker
l'adresse courante, l'adresse qui a fait référence à la page courante
(NULL pour le premier document) et la date de passage. Le deuxième
robot va utiliser les URL rapatriées pour les utiliser comme chemin à
suivre. Dans ce cas, le robot ne va pas du tout regarder les liens
contenus dans les documents visités. Il va interroger la base de
données dans un premier temps pour connaître le chemin qu'il doit
suivre. Une fois cette liste obtenue, pour chaque URL trouvée, il va
ramener les informations liées au document par le protocole HTTP
décrit précédemment. Ayant ainsi récupéré ainsi une chaîne de
caractère, il va déterminer la date de dernière modification du
document en question et la stocker dans la table avec la date de
passage du robot. Les données rapatriées par le robot peuvent être
trouvées de façon manuelle avec un navigateur tel netscape, en
utilisant Document Info dans le menu View (voir figure 5).
FIGURE 5. Fenêtre Document info de Netscape
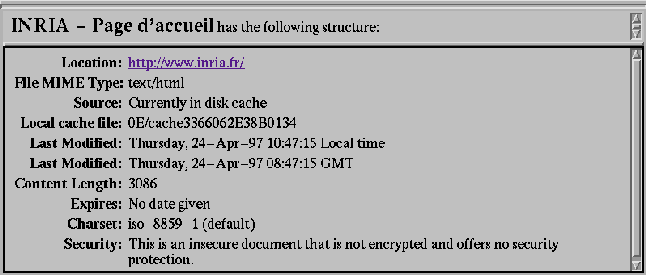
Le problème posé est que, les données telles que la date de mise à
jour, la taille du document, dépendent de la configuration du démon
HTTP qui regarde la dernière modification du fichier, sa taille,
... Aussi, le robot lancé sur certains serveurs WEB mal configurés,
est incapable de récupérer ces dates de mises à jour. De plus, le
format des dates rendu n'est pas toujours le même. Pour la suite du
projet, la plupart des tests seront faits sur le serveur de
l'I.N.R.I.A. pour des raisons pratiques de performance. En effet,
c'est un gros serveur assez diversifié, sur lequel il est possible de
faire des statistiques, car il est composé de pages personnelles, de
pages de présentation du serveur, de pages d'informations ... De plus,
c'est un serveur local, ce qui diminue les délais de visite.
3.1.4 La base de données
Dans la suite du stage, le but est de faire une analyse statistique
des résultats obtenus par le robot. Pour cela, la sauvegarde des
résultats a dû se faire de façon à pouvoir réutiliser facilement ces
données stockées. La première idée d'utiliser un fichier pour stocker
le résultat de l'exécution n'étant pas une bonne chose, puisque
l'accès ensuite aux informations n'est pas pratique, l'utilisation
d'une Base de Données s'est avérée une bien meilleure solution. Les
informations pourront être ainsi retrouvées beaucoup plus vite, grâce
à un langage de requêtes, que par l'intermédiaire d'un fichier qui
nécessite un parcours séquentiel.
Aucune Base de Données n'étant disponible dans le projet MISTRAL de
l'I.N.R.I.A, il a fallu entrouver une. Le produit msql de Hughes
Technologies
[8] a été choisi pour différentes raisons. En
effet, c'est une véritable base de données, avec un langage
d'interrogation se rapprochant beaucoup de SQL (avec quelques
fonctionnalités en moins), et de plus surtout gratuit. La sauvegarde
des résultats et la recherche des informations se fera ainsi bien plus
facilement. De plus, msql offre une bibliothèque de fonctions C de
dialogue avec la Base (connection, interrogation, MAJ, ...). Le robot
va donc se servir de cette bibliothèque pour mettre la base à
jour.
3.1.5 Le stockage des données
Msql n'étant pas une base de données très puissante, le
développement du robot a dû tenir compte des délais de réponse. Pour
éviter trop d'accès concurrents, qui ralentissent le système, toutes
les mises à jour du deuxième robot se feront de manière différée. Car,
les requêtes qui étaient faites de manière régulière ont posé des
problèmes quand la base a commencé à contenir un grand nombre
d'enregistrement. Dans le cas du premier robot, seul une liste
d'adresses a besoin d'être stockée pour conserver le chemin
suivi. Dans le cas du deuxième robot, il faut non seulement,
interroger la base pour récupérer ce chemin, mais aussi garder les
informations sur les adresses, les dates de modification du document
et de passage du robot. De plus, il faudra également stocker le temps
de décalage entre chaque visite:ce temps est nécessaire au processus
Poisson.
Le stockage des dates va se faire ainsi :
année/mois/jour-heure:minute:seconde, l'année étant codée sur quatre
chiffres pour éviter les problèmes de fin de siècle. Ce genre de
formatage de dates est beaucoup plus facileà utiliser (surtout au
niveau des tris)que les dates standards du type «Thu, 13 Mar
1997 11:16:18 GMT» que le robot est capable de rapatrier
dans un premier temps. Il faut donc coder les dates obtenues. De plus,
il fallait garder également une précision de l'ordre de la seconde
(une page peut être modifiée plusieurs fois dans la même
journée). Pour pouvoir faire des différence entre deux dates, la
solution utilisée a été de ramener chaque date en seconde par rapport
à une date initiale. Cette date choisie est le 1er janvier 1970. Il
suffit ensuite de soustraire les deux montants obtenus et d'obtenir un
résultat en seconde.
3.1.6 Les documents à visiter
Le robot est capable de visiter tous les types de documents (texte,
image, son,...), mais seuls certains ont une valeur pour la suite des
recherches. Toutes les pages du type image ne sont pas accéder car
elles n'évoluent pas dans le temps. Par contre, si une image change
dans une page HTML alors c'est la date de mise à jour de cette page
qui va changer. Donc, seules les pages de textes sont intéressantes à
visiter. Comme nous l'avons vu auparavant, le robot s'est limité à la
visite des pages sur un même serveur. Il faut également qu'il se
limite à certaines extensions : seules les pages .html (ou .HTML)
(format standard), .htm (extension PC), ou bien les répertoires
(puisque par défaut ce sont les fichiers index.html ou homepage.html
qui sont ouverts) seront visitées.
Une question s'est posée lors de la restriction des accès sur
certaines pages : faut-il visiter les pages générées par un programme
cgi? Un programme cgi est un programme (écrit dans n'importe quel
langage de programmation) qui fait des écritures sur la sortie
standard. Exécuté par l'intermédiaire d'un navigateur, le programme,
avec extension spécifique (.cgi, .pl, ...), écrit dans un premier
temps une ligne où il indique qu'il va renvoyer du texte HTML et puis
renvoie ensuite le texte qui sera perçu directement comme une page
html. Le problème des programmes cgi est de savoir si leur date de
modification est la date à laquelle a été développé le programme, ou
bien est-ce à la date où a été exécuté ce programme. En fait, la
deuxième solution s'est avérée plus juste puisque un programme cgi
peut ne jamais donner le même résultat. En effet, suivant
l'utilisateur qui lance le programme, ce cgi peut indiquer le nom,
prénom, adresse de l'utilisateur. Ces informations changeront à chaque
nouvel utilisateur. Dans le cas du développement d'un site miroir, il
ne faudrait pas rapatrier ce type de page car son exécution pourrait
varier si le programme fait accès à une base de données, mise
uniquement à jour sur le site distant.
Donc, la visite des programmes cgi semble être inutile puisque l'on
connaît déjà, à n'importe quelle date, sa dernière mise à jour,
puisqu'il s'avère que c'est la date de visite de la page en question
(exécution du programme). Il ne serait alors pas très intéressant
d'utiliser ce type de pages pour faire des statistiques sur la mise à
jour des sites WEB.
3.2 Le processus Poisson
3.2.1 Les visites de pages
Pour obtenir un certain type de mesure, le robot qui rapatrie les
dates de modifications, soit suivre un processus de Poisson dans sa
visite de page pour permettre l'analyse des résultats. C'est à dire
que les moments d'observation doivent être pris de façon totalement
aléatoire. Ainsi, il sera possible de tirer des conclusions sur les
espérances des mises à jour des sites à partir des espérances obtenues
entre la visite et la date de dernière modification de chaque
page. Pour cela, nous allons procéder de la manière suivante (figure
6).
FIGURE 6. Chronologie des visites d'un site
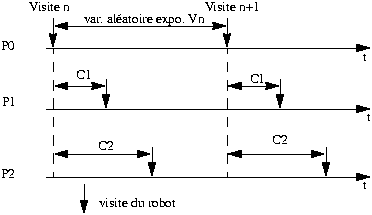
Il est important que la visite de chaque page suive elle-même un
processus Poisson. Pour cela, l'intervalle entre les visites d'une
même page doit être déterminée dans le temps par une variable
aléatoire exponentielle. Nous verrons dans la section suivante comment
déterminer cette variable. Nous voyons également pourquoi il est
important de garder le même chemin de parcours d'une visite sur
l'autre.
Pour se faire, il faut «ralentir» le robot afin qu'il
consulte une page au moment voulu. C'est à dire qu'il faut attendre un
certain délai entre la visite de chaque page. Ce délai sera identique
entre les différentes visites d'un même site. Il est représenté dans
le schéma ci-dessus par les constantes Cn.
Le délai C1 sera le temps mis par le robot pour passer d'une page
P0 à une page P1. Mais ce délai n'est pas uniquement une mise en
sommeil du robot. En fait, il faut considérer le temps réseau
nécessaire au passage d'une page à l'autre. Il faudra donc calculer le
temps d'attente effectif. Pour déterminer les constantes Cn, il est
impératif que ces délais soient au moins supérieurs au temps déterminé
par le réseau. les Cn seront d'autant plus grands que le robot tourne
sur un site distant ou sur un réseau saturé. Pour mettre au point la
stratégie d'attente, l'idée est d'utiliser deux processus comme dans
le schéma suivant.
FIGURE 7. Synchronisation des visites entre plusieurs pages
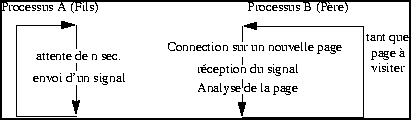
En fait, il s'agit de créer deux processus Père et Fils, le premier
envoyant tout simplement un signal au deuxième toutes les périodes
données. Le deuxième fait la majeure partie du travail (transfert des
données d'un document), et se bloque entre les visites de deux pages
jusqu'à l'obtention du signal. Cette méthode permet de ne pas
s'intéresser au temps réseau pour obtenir la connection sur la
page. Il faut juste s'assurer que le temps de repos du fils est au
moins supérieur au temps écoulé pour la connection sur une page.
3.2.2 Comment déterminer le délai entre les visites
Comme vu précédemment, il faut qu'une page soit visitée suivant un
processus de Poisson. Pour cela, il faut que la période entre les
visites soient déterminées de façon totalement aléatoire.
On dit qu'un processus suit une loi de Poisson s'il se déroule à
des périodes de temps aléatoires exponentielles. La fonction C,
rand(), est une fonction qui renvoie des entiers. En
fait, elle renvoie des valeurs uniformément réparties sur un
intervalle (de 0 à 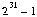 ). Pour
pouvoir poursuivre, il faut ramener ces variables sur un intervalle de
[0:1] (division par la borne
supérieure par exemple). Il faut ensuite se ramener à des variables
aléatoires exponentielles, utiles pour la suite. Pour passer de
variables aléatoires uniformément réparties à des variables aléatoires
exponentielles, il faut utiliser la fonction inverse de la fonction de
répartition de Poisson.Soit le fonction de répartition de Poisson F,
tel que :
). Pour
pouvoir poursuivre, il faut ramener ces variables sur un intervalle de
[0:1] (division par la borne
supérieure par exemple). Il faut ensuite se ramener à des variables
aléatoires exponentielles, utiles pour la suite. Pour passer de
variables aléatoires uniformément réparties à des variables aléatoires
exponentielles, il faut utiliser la fonction inverse de la fonction de
répartition de Poisson.Soit le fonction de répartition de Poisson F,
tel que : 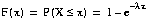
FIGURE 8. Fonction de répartition de Poisson
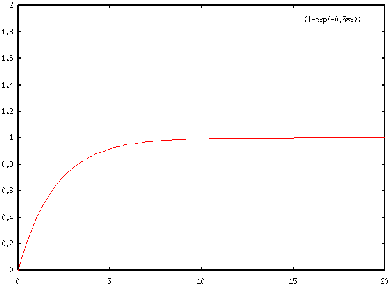
Supposons la fonction inverse de F, F-1. on sait que :
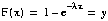 donc :
donc :
 avec
avec
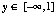 et
et
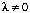 et
où y est une variable aléatoire uniformément répartie sur [0;1].
et
où y est une variable aléatoire uniformément répartie sur [0;1].
FIGURE 9. Fonction inverse de Poisson
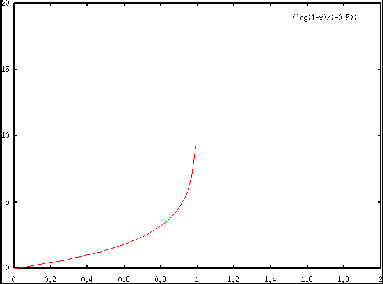
Le problème principal de ce calcul est le problème de précision des
machines. En effet, nous voyons que
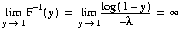 alors que la précision lors de la
programmation est beaucoup moins bonne qu'en théorie.
alors que la précision lors de la
programmation est beaucoup moins bonne qu'en théorie.
Pour changer d'échelle, suivant la distance du site,
il est possible de faire varier la valeur de 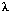 afin d'adapter les valeurs des variables aléatoires exponentielles.
afin d'adapter les valeurs des variables aléatoires exponentielles.
