2 Etat de l'art
2.1 Le WORLD WIDE WEB
2.1.1 L'état du WEB
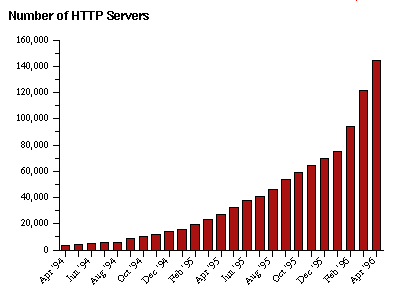
Internet est une interconnection entre réseaux hétérogènes. Un des principals outils connus est le WORLD WIDE WEB, traduit en français par «Toile d'Araignée Mondiale». Créé depuis quelques années, il a connu un gros succès, accompagnant ainsi celui d'Internet. La figure 1 montre cette évolution. Cette comparaison avec une toile d'araignée peut s'expliquer ainsi : Un site est un ensemble de pages HTML [12] référençant d'autres documents. Ces documents peuvent être sur le même site, mais aussi sur des sites distants. On peut considérer ainsi un graphe où chaque site est un noeud et chaque référence entre deux pages une arête. Il est donc possible de se déplacer dans le Web comme dans un graphe en suivant ces liens, et atteindre, n'importe quel autre point, à partir de tout point initial. Cette hypothèse de penser qu'il existe toujours un chemin entre deux points quelconques du graphe n'est qu'une théorie car certains serveurs peuvent ne jamais être référencés par d'autres.
FIGURE 1. L'évolution du Web
Si le Web a connu une telle réussite, c'est sûrement dû à ses possibilités. Une source d'informations peut être transmise à n'importe quelle personne connectée dans le monde entier. Ces informations peuvent s'étendre à de nombreux domaines et donc, beaucoup ont vu un gros potentiel de l'outil. La publicité est l'une des sources de données importantes car c'est un système peu cher vu la clientèle touchée. D'autres domaines comme la distribution, l'éducation ou l'information constituent un ensemble important de sites. Actuellement, le nombre de serveurs ayant énormément augmenté, les sujets se sont d'autant plus diversifiés. Il est donc possible d'accéder aujourd'hui à n'importe quel thème voulu.
Mais, cet accroissement, non prévu, a vite posé certains problèmes. La plus grosse difficulté a été justement cet accès aux informations. Le Web a grossi si vite, sans aucune organisation, ni contrôle, que trouver une information précise s'avère une tâche bien difficile. Cette croissance dynamique a provoqué une anarchie dans le Web. Aussi, a t-il été important de résoudre ce problème afin de rendre l'utilisation du Web aussi conviviale que pratique. L'idée d'indexer le Web [1] est apparue comme la meilleure alternative pour accéder aux informations contenues. Cette solution est, dans un premier temps, de parcourir les différents sites et de ranger ensuite les informations collectées dans des banques de données. Automatiser ce travail s'est donc avéré indispensable. Et, le développement des premiers moteurs [5] de recherche s'est fait afin de répondre à cette demande.
2.1.2 Le travail des moteurs de recherche
Historique
WebCrawler [11]
a été un des premiers moteurs de recherche lancé sur
le marché. Développé dans un projet de recherche de l'Université de
Washington au début de l'année 1994, il a été une véritable réussite
commerciale. Au début de son exploitation, la base de données de
WebCrawler contenait des informations sur 6000 serveurs WEB. Son
succès en a fait un outil très vite utilisé et dès la fin 94, le
service recevait plus de 15000 requêtes par jour. Depuis, de nombreux
autres moteurs ont été mis en circulation:Lycos, InfoSeek, Open Text,
Yahoo, etc ... Le nombre de ces moteurs est aujourd'hui très grand, la
plupart n'étant pas officiels, mais seuls certains sont très souvent
utilisés.
Le vocabulaire utilisé
Pour la suite de ce rapport, nous utiliserons aussi bien le terme de
moteur de recherche que celui de robot. Nous retrouvons également dans
les ouvrages anglais les mots Spider, Worm ou Web Crawler (ne pas
confondre avec WebCrawler (vu auparavant) qui est un robot
spécifique).
En fait, on parle de moteur de recherche, ou de robot, pour un programme qui fait des recherches sur un ensemble de données. Dans le cas du World Wide Web, C'est un automate qui va utiliser le contenu des pages HTML comme données pour faire ses recherches. A partir de ces documents, le robot va stocker des éléments qui pourront être réutilisés au moment de l'interrogation. L'utilisation d'un moteur de recherche ensuite, n'est en fait qu'un accès, interfacé par une page Web, à une base de données préalablement remplie. Le robot, lui, est lancé de façon invisible aux utilisateurs à des dates périodiques pour maintenir ces tables à jour.
Le travail
Le moteur de recherche travaille de façon
simple. On peut le comparer à un browser HTML tel que Netscape,
mais contrairement à lui, la navigation se fait de façon
automatique. C'est à dire, à la différence des navigateurs habituels,
sur lesquels le passage de document en document nécessite la
participation d'un utilisateur qui doit choisir le lien à suivre, le
robot va suivre toutes les pages référencées par une page initiale et
cela de façon récursive.
Le moteur de recherche démarre toujours sa recherche sur une liste
d'adresses. Cette liste est nécessaire pour pouvoir explorer tout le
Web et pour éviter l'oubli de certains sites non référencés par
d'autres serveurs. Il est donc possible de demander à rajouter
l'adresse de son propre site si l'on désire rendre disponible ses
données à partir d'un moteur de recherche. Ensuite, le travail se
déroule ainsi. Pour chaque page initiale de la liste, le robot va
faire une requête HTTP (protocole décrit dans une section suivante) et
récupérer ainsi un ensemble de données, dont le contenu du document
HTML. Il va analyser tout ce document afin d'en extraire les
différents liens qu'il peut contenir. La plupart des pages sont
référencées en HTML de la façon suivante :
<A
HREF="page.html">texte</A>
Pour chaque nouvelle adresse
obtenue, le robot vérifie qu'il ne l'a pas déjà visitée plus tôt, et
si ce n'est pas le cas, alors il procède de la même façon sur cette
page et cela récursivement jusqu'à ce qu'il ne trouve plus aucunes
nouvelles adresses à visiter. On peut considérer le travail d'un robot
comme le parcours d'un arbre. Les boucles sont évitées en vérifiant à
chaque fois que l'on ne visite pas deux fois la même adresse. Cette
visite se fait en largeur puis en profondeur. Nous verrons un exemple
de parcours d'arbre dans la section 3.1.2 «Le parcours du
robot».
Quelques soient les robots, le parcours se fait à peu près de façon similaire. Après cela, chaque robot a un travail spécifique. Dans le cas de l'indexation du WEB (qui était le but premier des moteurs de recherche), pour chaque adresse visitée, le robot va stocker des données liées au contenu du document : titre, mot clef, paragraphes, etc ... Les informations seront ainsi rangées dans une banque de données. Une fois ce stockage fait, la recherche des pages correspondant à un sujet ne sera qu'une requête sur la banque.
L'indexation
Les techniques d'indexation sont diverses et variées. Au
début, les titres des documents servaient comme mots clef de
recherche, mais cette solution a vite montré ses limites. Le titre
d'un document reflète très rarement le contenu du document. Donc la
solution adoptée est de stocker non seulement ce titre mais aussi tous
les mots des premiers paragraphes. Dans les versions récentes de HTML,
un nouveau tag a été créé pour permettre à l'auteur de la page de
spécifier les mots sur lesquels il désire faire apparaître les
recherches. Mais ce tag n'est pas encore assez propagé pour être
vraiment utilisé par les robots et la technique d'indexer le Web par
rapport au contenu et au titre du document reste toujours la solution
suivie. L'idée du tag reste tout de même une solution d'avenir afin de
vraiment déterminer plus précisément les mots clef dès la création de
la page.
2.2 Les services du WEB
2.2.1 Les adresses URI
Les URI (Uniform Resource Identifiers) sont les moyens pour représenter toutes les adresses des ressources (pages, services, documents, ...) sur le Web. Les URL (Uniform Resource Locator) sont un ensemble d'URI qui possèdent les instructions explicites pour accéder à toutes les ressources sur Internet. Dans leurs formes absolues, elles peuvent contenir un certain nombre d'informations comme la localisation ou une partie du chemin de la ressource. Dans le cas du protocole HTTP, c'est ce type d'ensemble qui sera utilisé.Les URN (Uniform Resource Name) sont un autre ensemble d'URI que nous ne détaillerons pas. Le graphe suivant donne une représentation de ces ensembles.
FIGURE 2. Uniform Resource Identifiers
_______________________________________________________ | _________________ | | | ftp: | | | | gopher: | | | | http: _______________ | | | etc | | urn: | | | |_____________|__| fpi: ? | | | URLs | | | | |_______________| | | URNs | |_______________________________________________________| URIs
2.2.2 Le protocole HTTP
Le protocole HTTP (HyperText Transfert Protocol) [3] est un protocole de transfert utilisé par le système hyper-média WWW afin de récupérer des informations à partir de serveurs distribués. Ce protocole utilise lui même le protocole TCP comme moyen de transport. C'est donc une couche placée au dessus de cette couche transport. Le problème est, que certaines caractéristiques particulières à HTTP agissent mal avec TCP ce qui provoque des problèmes de performance et de débit. En fait, le problème du protocole HTTP est d'utiliser une connection pour chaque requête.
Par contre, ce protocole est très simple. Le client ouvre une connection et envoie une requête. Le serveur exécute la requête en question, retourne le résultat puis ferme la connection établie.
Nous allons déterminer plus précisément comment un client récupère des données HTML sur un serveur HTTP à partir d'une adresse.
Le client établit une connection avec le serveur (dont il connaît l'adresse) et lui envoie une requête. Cette connection se fait sur le port 80 si le port n'est pas précisé explicitement ou sur le port donné. Une adresse HTTP se décompose ainsi : HTTP://hostname[:port]/path[?searchwords]- hostname : nom du serveur (numérique ou alphabétique)- port : numéro de port (facultatif)- path : chemin où se trouve le fichier (à partir du chemin initial des documents HTML)- searchwords : paramètres pouvant être passés à la page
Les requêtes envoyées sont également simples. C'est une chaîne de caractères ASCII terminée par le caractère CrLf (line feed). Il faut ensuite juste passer le type de méthode utilisée (get ou post) (comment passer les paramètres), l'adresse du fichier voulu (en omettant http:) et d'autres informations sur le client.
Syntaxe d'une requête