.JPG "Haut de page")
One of the main limits of the deployment of IP Multicast is the problem of multicast forwarding state scalability. Indeed, in traditional IP multicast, for each group, a tree is configured and the corresponding forwarding entries are stored in routers. The aggregation of the forwarding entries (as it is done in unicast) is a difficult task in multicast as the IP multicast addresses are not meaningful and do not reflect the location of the members of the group. Then, multicast tree aggregation has been proposed.
Multicast tree aggregation is a proposition that attempts to solve these problems by:
The main idea of Multicast tree aggregation is to allow multiple multicast groups to share the same delivery tree.
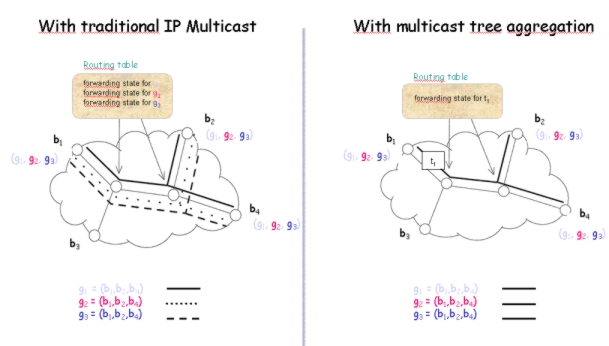
In traditional IP Multicast, each
multicast group is associated to a tree and each on-tree router
maintains a forwarding state.
Thus, the number of trees increases linearly with the number of groups.
With tree aggregation, there is only one
tree for multiple groups. Consequently, the number of trees is reduced
together with the
number of forwarding states. The number of control messages required to
maintain the trees is also reduced.
Centralized
protocols:
The first protocol achieving Tree Aggregation is AM (Aggregated
Multicast).
We proposed STA (Scalable Tree Aggregation) which
realizes fast aggregations.
Centralized
protocols with QoS requirements:
AQoSM realizes tree aggregation with bandwidth
constraints.
We proposed Q-STA which accepts a large number of
multicast groups in case of bandwidth constraints. The protocol mQMA deals with groups in case of multiple QoS requirements.
Distributed
protocols:
BEAM is a distributed protocol.
We proposed DMTA which realizes aggregations without any
requests to centralized entities.
Multicast
Tree Aggretion in Large Domains:
AMBTS and TALD are protocols proposed to
work specifically in domains with a large number of routers.
Indeed, in large domains, the number of different trees is huge. Thus,
the probability of finding a tree already configured for a
given group is rather small. That is why specific protocols for large
domains are proposed.
This work has been realized in collaboration with Alexandre Guitton.