During my Ph.D. in the Orion research group at INRIA on the interpretation of image sequences I participated to the PASSWORDS project:
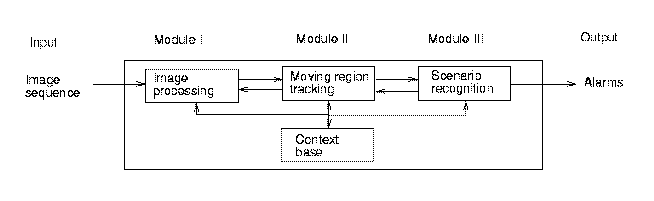
My work consisted in designing and developing a generic interpretation system of dynamic scenes. The class of applications I am interested in is the automatic interpretation of indoor and outdoor partially structured scenes observed with a fixed monocular color camera. Given image sequences of a scene, an interpretation system has to recognize scenarios relative to the behaviors of mobile objects. In my case the mobile objects correspond either to humans or to vehicles and the scenarios describe some real-world human activities.
I have developed a scene interpretation system composed of three stages. First, moving regions are extracted from the image sequence by low-level image processing tasks. Then a tracking module finds the associations between the detected moving regions to form and track mobile objects. In the final stage, a scenario recognition module identifies mobile objects based on the tracked moving regions and interprets the scenarios that are relative to their behaviors. When an interesting scenario is recognized, an alarm is triggered.
For the low-level image processing module, I have experiment several programs developed by different INRIA teams (Temis, Robotvis and Orion). Up to now, as the camera is fixed, I use the image processing module which has been developed by the Orion team in the framework of the European Esprit HPCN PASSWORDS project. It subtracts the current image with the background image which is regularly updated to compensate for illumination change. The main function of this module is to detect the moving regions. However there are still many detection errors due to reflections, blinking lights, lack of contrast... One of my goal is to improve this module by using the context base and results of the interpretation to automatically supervise and focus the attention of the image processing tasks [3].
For the tracking module, I
have developed a generic method able to track rigid or non-rigid
mobile objects. Because of the detection errors, a moving region can
correspond to a noise (e.g. a reflection), to a scene object (e.g. a
man), to a part of a scene object (e.g. a head) or to a group of a
scene objects (e.g. a crowd). For this reason, this module tracks
individually moving regions as well as groups of moving regions. On
the following frames you can see two tracked persons splitting
 ,
merging
,
merging
 ,
merging with noise
,
merging with noise
 ,
splitting again
,
splitting again
 ,
merging again
,
merging again
 ,
then merging with a third person
,
then merging with a third person
 . When
several tracked moving regions merge, the associations with newly
detected moving regions become ambiguous and so I suspend their
track. To freeze ambiguous associations, I use compound tracks
[7]. Then I wait for additive information to obtain sufficiently
reliable associations. My goals are to obtain a robust algorithm and
to repair detection errors as well as tracking problems
(e.g. occlusions). For these reasons I plan to enhance the
resolution of ambiguous associations.
. When
several tracked moving regions merge, the associations with newly
detected moving regions become ambiguous and so I suspend their
track. To freeze ambiguous associations, I use compound tracks
[7]. Then I wait for additive information to obtain sufficiently
reliable associations. My goals are to obtain a robust algorithm and
to repair detection errors as well as tracking problems
(e.g. occlusions). For these reasons I plan to enhance the
resolution of ambiguous associations.
For the scenario recognition module, I have use different works in natural language to describe human activities [8]. Based on these works I have defined six types of scenarios [6]. The scenarios are recursively defined through a combination of sub-scenarios and the property evolutions of mobile objects involved in the scenario. Object properties are defined as average measures computed by the image processing module [9]. There are two types of combination : temporal or non temporal . First, a scenario can represent a non temporal constraint on its sub-scenarios. For example, the scenario "the man sits down" combines the properties "the size of the man shrinks" and "the man is near the seat" . Second, a scenario can represent a temporal sequence of sub-scenarios. For example, the scenario "the man prowls round the cars" combines four sub-scenarios : "the man goes straight ahead" , "the man stays near the cars" ,...
I have developed two main methods to recognize scenarios
according to the combination type. To recognize a scenario
representing a non temporal combination of sub-scenarios, I use an
abductif diagnosis in the fuzzy set framework [4]. In this case, the
problem consists in establishing whether or not the sub-scenarios
are caused by disorders interfering with the current scenario
[6]. To recognize a scenario representing a temporal combination of
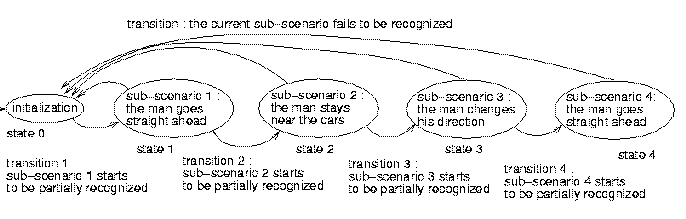
sub-scenarios I use an automaton, the states of which correspond to
the sub-scenarios. For example, the scenario "the man prowls
round the cars" is recognized by an automaton with five states
(1 state for the initialization + 4 states for the sub-scenarios)
[8]
 . These
two methods (diagnosis and automaton) enable to recognize all the
scenarios described by the proposed formalism. However, the
automatic generation of these methods from scenario descriptions is
still a problem.
. These
two methods (diagnosis and automaton) enable to recognize all the
scenarios described by the proposed formalism. However, the
automatic generation of these methods from scenario descriptions is
still a problem.
It contains all the information on the world environment of the scene, including static objets (e.g. "a seat" ) and interesting areas (e.g. "an exit" ). I have defined a mechanism to delimit contextual information in an image sequence interpretation system [5]. I have also defined a formalism to represent and to use contextual information depending on its nature [2]. This representation uses a tessellation of the 2D space (i.e. the image plan of the scene background). This tessellation is composed of polygonal zones that contain all context elements. My future works consist in the on-line and automatic acquisition of the contextual information during the interpretation process execution.
I have developed a graphical interface, implemented in C and using the Motif toolkit, to help a human operator to acquire off-line an application context.
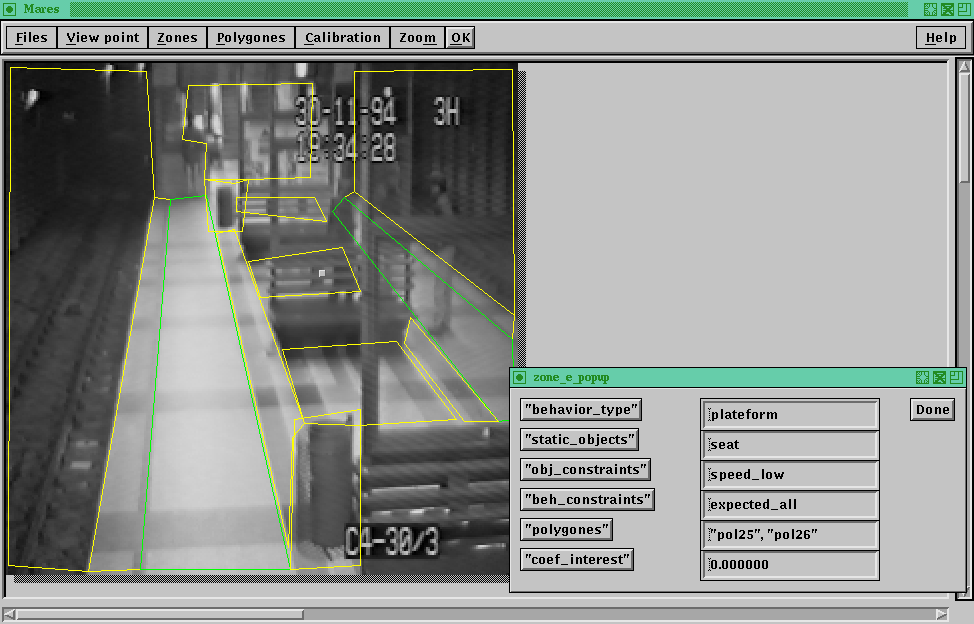 This picture represents the background image of a scene. On
this picture you can see a human operator using the graphical
interface in order to draw polygonal zones and to link
contextual informational to these zones.
This picture represents the background image of a scene. On
this picture you can see a human operator using the graphical
interface in order to draw polygonal zones and to link
contextual informational to these zones.
I am validating my work using
image sequences obtained from the European Esprit HPCN
PASSWORDS project. The process of one color 512*512 image takes
an average time of 2.5 seconds. I have managed to recognize
different types of scenarios [8]. The target applications are the
video-surveillance of metros, car parks and supermarkets. This
system is implemented in C++ and has started to work since fall
1996. In this image sequence, the interpretation system tracks a
man in the middle of the frames and recognizes a scenario relative
to his behavior "to prowl round cars"
 (mpeg file, 2.3M).
(mpeg file, 2.3M).
For more information,see the PASSWORDS PROJECT HOME PAGE: Parallel and real time Advanced Surveillance System With Operator assistance for Revealing Dangerous Situations.