



Next: Conclusion de ce chapitre
Up: ArGiMoGe : Etude et
Développement
Previous: Introduction
Comme on l'a mentionné dans l'introduction de ce document et comme
il a été reconnu par la communauté scientifique concerné par
le sujet réuni lors d'une session de travail qui est à l'origine
de ce sujet et que nous réferrons sous le nom de projet
ReViMoGe , le besoin de standardisation des
méthodes et des structures de données est comblé au niveau des
systèmes, qui ne sont pas soumis à des contraintes temps-réel,
à travers le standard IUE. Ce n'est néanmoins pas le cas pour
les systèmes temps-réel et on appellera ReViMoGe le projet d'un
tel système, ébauché par ce groupe européen et dont ce travail de
stage contribue donc à faire l'analyse.Plus précisément, IUE ou Image Understanding Environment
est un environnement logiciel de programmation pour la recherche en
traitement d'image et vision artificielle. Ce projet est issu, à
l'origine, d'un projet sur cinq années, financé par le
département de recherche de la Défense américaine, le ARPA.
, le besoin de standardisation des
méthodes et des structures de données est comblé au niveau des
systèmes, qui ne sont pas soumis à des contraintes temps-réel,
à travers le standard IUE. Ce n'est néanmoins pas le cas pour
les systèmes temps-réel et on appellera ReViMoGe le projet d'un
tel système, ébauché par ce groupe européen et dont ce travail de
stage contribue donc à faire l'analyse.Plus précisément, IUE ou Image Understanding Environment
est un environnement logiciel de programmation pour la recherche en
traitement d'image et vision artificielle. Ce projet est issu, à
l'origine, d'un projet sur cinq années, financé par le
département de recherche de la Défense américaine, le ARPA.
Le but premier d'IUE est d'accro^itre l'efficacité de la programmation
(définition d'objets et de méthodes couramment employés) et
l'échange de résultats de recherche dans ce domaine
(données, algorithmes, etc  ). A cette fin, IUE fournit :
). A cette fin, IUE fournit :
- une hiérarchie extensive de classes C++ représentant une large gamme
d'objets, images, caractéristiques d'images et algorithmes, utilisés
en vision et traitement d'images,
- une interface standard modulaire orientée objet bien documentée,
et basée sur des outils industriels existants,
- une implémentation d'algorithmes standards (détection de points, ...),
actuellement en cours,
- la possibilité d'utiliser et de coordonner la puissance de systèmes
déjà existant dans ce domaine.
Néanmoins, les spécifications introduites dans IUE
ne couvrent pas les problèmes inhérents au temps réel et à la
réactivité inhérente aux systèmes qu'ils mettent en oeuvre. En effet,
il existe des besoins importants de standardisation en :
- Représentation des données et protocoles de données
pour les échanges en-ligne d'informations ;
- Architectures permettant de construire des systèmes temps-réel ;
- Transfert simplifié depuis une plateforme expérimentale
vers des installations industrielles temps-réel.
En outre, le développement d'un tel environnement, dans le contexte
temps-réel, demande de pouvoir résoudre deux types de contraintes :
- Au niveau de la Spécification :
Le problème semble être de standardiser différents types de
données et d'informations de contrôle de façon à obtenir dans
un même temps des représentations flexibles et communes des données.
Ces représentations ne doivent pas seulement servir à décrire les
données mais aussi les tâches, les flots de contrôle et les interactions
fortes entre le logiciel et le hardware.
Les définitions de telles spécifications vont permettre :
- la modularité au niveau des méthodes orientées-objet ;
- l'instantiation "rapide" des opérateurs génériques ;
- la gestion d'événements et sa mise au point sur des systèmes
cibles
temps-réel.
- Au niveau de l'Implémentation :
Le problème se situe dans la manière d'appliquer dans le monde réel
de telles spécifications. Il faut pouvoir assurer que :
- le système supporte le temps-réel afin d'être utilisé aussi
bien pour les applications industrielles que pour celles de la recherche ;
- le système soit suffisamment flexible pour pouvoir être utilisé
dans différents types d'applications ;
- le système soit séduisant vis-à-vis des programmeurs,
c'est-à-dire que
l'apprentissage du système soit rapide et simple ; - le système doit pouvoir fournir des méthodes simples pour
la mise-à-jour et permettre d'inclure ou tester facilement de nouvelles
méthodes.
Pour atteindre les objectifs fixés précédemment,
voici les points clés qui seront à la base de notre travail :
- La Modularité : il faut un environnement modulaire pour garantir
de pouvoir développer un système dont la taille ne sera fonction que de
l'application envisagée et non de tout l'environnement. Précisons
cette idée :
- De la modularité découle la capacité d'utiliser conjointement
ce qui a été précédemment développé et ce qui le sera
au fur et à mesure des développements.
- La modularité est importante à la fois dans le développement
d'applications et pour améliorer les spécifications.
- Mais il est aussi
important, pour créer des applications embarquées, de ne pas avoir
à "charger" plus que ce qui est déjà utilisé, pour avoir une taille
minimale des codes.
- De plus, cela permettrait un "apprentissage progressif" de telle sorte
que le premier venu n'aie pas besoin d'apprendre plus qu'il n'est
nécessaire pour débuter son application.
- Les Restrictions Temps-réel : l'utilisation du
temps-réel impose au système de lourdes restrictions au niveau
de la conception et des spécifications. Néanmoins, loin d'être
négatif cet état de fait a l'énorme avantage suivant : en
forçant à
être le plus "simple possible", il permet de limiter les
développements particuliers ou trop spécifiques donc de rester
"générique". Ainsi :
- Même si chaque application a ses exigences propres en
matière de temps-réel, et nécessite peut-être des
caractéristiques particulières, la plupart de ces exigences
ont une base commune. Par conséquent, on peut supposer pouvoir
spécifier une architecture générale qui va servir à
construire des systèmes de contrôle temps-réel pour
différentes applications.
- Ceci va permettre aussi de simplifier la construction
spécifique d'un système de contrôle. L'architecture ne devra
pas seulement gérer un ensemble de ressources (telles que les
processeurs, la mémoire, les canaux de communications ...etc)
utilisées par chaque partie de l'application, mais il devra
aussi gérer le temps d'utilisation de ces ressources et leur
séquencement.
En fait, le développement d'une application nécessite la
définition formelle d'un ensemble de méthodes qui permettent
la
mise en oeuvre d'un ensemble de concepts théoriques, sur lesquels
repose la
spécification des entités que l'on souhaite manipuler
(ex : algorithme,
etc...).
L'implémentation de ces méthodes reposent quant à elles sur le choix
d'un ensemble d'outils adaptés et efficaces.
Le travail consiste à fournir ces outils dans un environnement intégré
selon une architecture bien définie, pour permettre à différentes
personnes
d'interagir et de modifier les entités manipulées indépendament, tout
en cachant
les détails d'implémentation
requis pour suivre les méthodes proposées et les concepts
sous-jacents.
Un autre facteur important, pour atteindre les objectifs dégagés
par les chercheurs, lors de la réunion de travail de janvier 1995,
est d'aboutir à un coût de développement d'un système donné le
plus bas possible. Un moyen pour y parvenir consiste à utiliser des
outils déjà existants. Ainsi, en plus de réduire le coût de
développement, on minimisera le degré d'incertitude sur le
système et assurera sa pérénité au fur et à mesure de l'évolution
des matériels et logiciels.
Cependant, il est bon de noter que cette problématique implique
d'autres développements encore du domaine de la recherche tels que :
- La génération automatique de code (à partir de spécifications
générales des données ou des flots de contrôle).
- La modélisation orientée-objet de données, de flots de contrôle,
de ressources logiciels etc...
- Les techniques de programmation synchrone pour spécifier la
réactivité, les opérateurs de parallélisme, l'interface avec
les événements externes, etc ...
- Les opérateurs génériques pour le parallélisme pour pouvoir
installer les modules développés sur des machines parallèles MIMD.
Ces aspects sont fortement liés avec ce type de projet et pourraient
être utilisés pour optimiser le système. Ils feront l'objet de
travaux ultérieurs.
Considérant les différents critères mis en avant par les partenaires consultés,
les outils actuellement disponibles et utilisés
sur lesquels on peut s'appuyer, pour l'élaboration
du système envisagé, sont les suivants:
- Maple comme générateur de code :
Étant donné que l'on va faire de la génération de code de type
calculatoire, on a besoin d'effectuer beaucoup de calculs symboliques
tel que : résoudre des équations, dériver de manière symbolique,
réduire des expressions, propager des constantes
à travers le code, créer des opérateurs génériques, etc...
[3, 4].
Et bien entendu, le meilleur outil pour réaliser ces manipulations est un
calculateur symbolique. C'est pour cela que Maple5.3 va être
employé pour cette tâche.
Étant donné les caractéristiques de base de ce système symbolique,
le travail additionnel à effectuer sera simplement de :
- ajouter une couche dite "orientée-objet" au-dessus du calculateur
symbolique
- concevoir des "mécanismes de génération de code" utilisant les
définitions orientées-objet établies ci-avant,
ce qui est en cours à travers l'extension Mascotte/mso de
Maple [2].
Deux autres raisons pratiques favorisent l'utilisation de Maple :
- c'est un puissant interpréteur doté d'un grand nombre de primitives
permettant la manipulation de données symboliques, non nécessairement
mathématiques ;
- c'est un produit facile à apprendre, bon-marché, bien reconnu et
populaire, tout en étant notoirement efficace.
- Un langage C-restreint comme langage cible :
On a choisi de générer le code en utilisant un sous-ensemble
du langage C standard que l'on a baptisé C-restreint ou encore
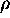 -C.
-C.
L'utilisation d'un sous-langage C est motivé par les faits suivants :
- chaque processeur sur le marché possède un compilateur C. Il
est le plus souvent adapté à l'architecture du processeur de façon
à ce que l'usage des registres CPU, de l'adressage mémoire et
des instructions soient optimisés.
- le but recherché avec le système ReViMoGe étant de créer
un standard "universel", le sous-langage C permettra de rendre le
système portable sur presque n'importe quel type de machine ou de
processeur.
- d'un point de vue plus théorique, on définit ainsi une "machine
virtuelle" plus que réaliste puisque instantiable sur toutes les
architectures, mais sans avoir à modéliser tout ce qui concerne l'architecture
d'un processeur donné (micro-instructions, mémoire cache, etc...) qui serait
d'une complexité rédibitoire, à ce niveau.
Mais pourquoi utiliser un sous-ensemble de C ? Il y a deux principales
raisons à cela:
- on n'a pas besoin dans la génération de code de l'intégralité
du langage C.
- on évite comme cela d'utiliser certaines caractéristiques
du langages qui sont au niveau sémantique très lourdes et mal définies
(pointeurs, casting, etc...).
Nous développerons plus en détails ce sous-langage à l'annexe
B. - Esterel pour définir la partie réactivité du code :
Pour la partie réactive du système, le langage C n'est pas suffisant
à lui seul pour définir nos outils, car
il n'a pas été conçu pour pouvoir gérer
du synchronisme ou encore du parallélisme. Aussi a-t-on choisi d'utiliser
les primitives du langage Esterel, pour les motivations suivantes :
- Esterel permet une gestion optimale des événements, et par
conséquent garantit une grande efficacité au niveau de l'exécution,
car ce langage se base sur une hypothèse de synchronisation
qui permet de produire un automate d'états finis pour le contrôle de
la réactivité de toute
application et donc de résoudre à la compilation les problèmes de
communication et de séquencement de processus.
- Esterel permet de prouver, de part son élaboration même,
de manière mathématique, que le programme aura bien le fonctionnement
voulu, lors de l'exécution. Par conséquent, cela permet d'introduire
des preuves au niveau du code.
- Posix pour le formalisme temps-réel :
POSIX ou Portable Operating System Interface
est une norme qui fournit des moyens de rendre portables des applications
écrites pour un système d'exploitation donné, et de rendre
l'écriture d'un programme plus simple. Toutes les primitives temps-réel
utilisées dans notre système sont compatibles avec la norme Posix.
Par conséquent, elles peuvent tourner sous tout système compatible
avec Posix tel que VXWORKS et même avec certains
packages logiciels sur PC. - Les primitives PVM pour définir le parallélisme :
Le langage PVM est devenu un outil relativement bien accepté
pour définir des processus parallèles et les communications entre ces
processus. C'est ce langage qui a été retenu pour définir les modules
de vision que l'on va lancer sur différents processeurs. En fait,
grâce au formalisme de programmation parallèle basée sur le
langage Esterel, seul un petit sous-ensemble de primitives PVM
sera utilisé. - Java pour définir l'interface utilisateur :
L'interface utilisateur sera réalisée grâce au langage Java, et
à ses "widgets". Cette méthode permet à l'utilisateur
de spécifier assez simplement les menus, les pannels interagissant
avec l'utilisateur, les données et images de sortie. Il suffit
à l'utilisateur de créer son interface "à la main" et
Java se charge de l'implémenter. De plus, on peut obtenir
une interface efficace sur une station de travail et proposer des
démonstrations du système sur le réseau. - WWW pour la documentation et la distribution du produit :
La documentation des modules sera générée en "hypertext" en utilisant
le langage HTML.
Le choix de WWW permet d'éliminer une partie des problèmes liés à
l'interface utilisateur. De plus, la diffusion, la publicité et la
maintenance du logiciel sont facilement réalisées à travers
INTERNET étant donné que les données WWW et sa hiérarchie
peuvent être directement transférées à travers le réseau ou
vers n'importe quel type de support, y compris les modules Java.
D'autre part, l'échange de données
et de méthodes entre utilisateurs est facile à établir.
Next: Conclusion à ce chapitre
Up: ArGiMoGe : Etude et
Développement
Previous: Introduction
Soraya Arias
Mon Aug 5 17:38:44 MET DST 1996