



Next: Stopping a procedure and
Up: Parallel processing
Previous: Parallel processing
Contents
Parallelizing ALIAS programs
Interval analysis has a structure that is appropriate for a
distributed implementation. Indeed the principle of the algorithm is
to process a list of boxes, the processing for a box being independent
of the other boxes in the list (except that it may have be stopped).
A classical distributed implementation will rely on the
master/slave paradigm. A master computer will manage the list of boxes
and monitor the activity of the slaves. As soon as a slave is free the
master will send a box to this slave. The slave, which has its own
list of boxes, will perform a few iteration of the solving algorithm
and then send back to the master the remaining boxes to be processed in
its list and eventually the solutions it has found.
After receiving a signal from the slave the master will receive the
boxes from the slave and append them to its list of boxes. This slave
being now free the master will send him another box in its list.
Hence most of the calculation will be performed by the
slaves. It may happen however that at a given time all the slaves are
busy processing boxes. The master itself may then start a few
iteration of the solving algorithm on the current box of its list
while carefully monitoring the activity of the slaves.
The structure of the interval analysis algorithms is very convenient
for using the above paradigm:
- few data are to be transmitted by the master to the slave:
typically for a problem with
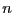 unknowns the master will have to send
2 floating numbers that describe a box. It may however be
interesting to send other information such as the derivatives but
still the amount of data will be low
unknowns the master will have to send
2 floating numbers that describe a box. It may however be
interesting to send other information such as the derivatives but
still the amount of data will be low
- the processing time of a box is in general much more large than
the transmission time
The gain in computation time will in general be lower than the number
of used slaves. This is due to
- the transmission time between the master and the slaves
- an overhead of the slave program: in our implementation the
slaves uses basically the same program than the master and perform
some coherence checks on the unknowns, equations, available memory
size
 before starting the processing of the box
before starting the processing of the box
- the fact that only one computer manages the list of boxes. This
master may be still managing the boxes send by a slave while others
slaves have already finished their processing. Clearly the
master/slave paradigm exposed above may not be the best for a large
number of computers. In a next version we intend to propose another
paradigm for the use of the interval analysis algorithms in the
framework of grid computing
Note however that in some cases the gain may be larger than the number
of slaves. This is, for example, the case of the optimization
algorithms as the independence of box processing is no more true: the
discovery of a good optimum by a slave may leads to stop the
processing of the other slaves.
In any case a key point of a distributed implementation is to be able
to
- stop an algorithm that is run by a slave computer
after it has performed some processing on a box
- recover
the current state of the slave process i.e. the solutions if any and the
remaining unprocessed boxes.
Next: Stopping a procedure and
Up: Parallel processing
Previous: Parallel processing
Contents
Jean-Pierre Merlet
2012-12-20