Point d'ouverture "ValueSimilarityFct"
![]()
![]()
![]()
![]()
![]()
Description |
Le point d'ouverture ValueSimilarityFct permet la hiérarchisation des fonctions élémentaires de similarité. Il permet de définir les différentes fonctions de similarité définies suivant les connaissances du domaine, la sémantique des indices et leur domaine de valeurs..
Conception |
La modélisation proposée repose sur une représentation structurée des similarités et permet une modification aisée de leur définition.
Le calcul des similarités s'appuie sur l'utilisation de deux types de fonctions : les fonctions élémentaires de similarité et les fonctions d'agrégation. Pour la représentation de ces fonctions, on propose deux hiérarchies extensibles de classes. La hiérarchie des fonctions élémentaires de similarité est donnée dans la Figure 1et l'expression des fonctions est précisée dans Tableau 1. Le premier critère de classification est constitué du domaine de valeurs de la fonction. On développe uniquement les sous-classes permettant de calculer des facteurs de similarité, et les sous-classes applicables pour n'importe quel type de domaine. Lors du calcul de la comparaison, le descripteur de l'indice considéré est passé en paramètre, ce qui permet à la méthode de calcul, d'une part, de vérifier que les propriétés nécessaires de l'indice sont bien respectées, et d'autre part, de récupérer les données descriptives de l'indice dont notamment son domaine de valeurs (par exemple domaine numérique borné, liste de valeurs).
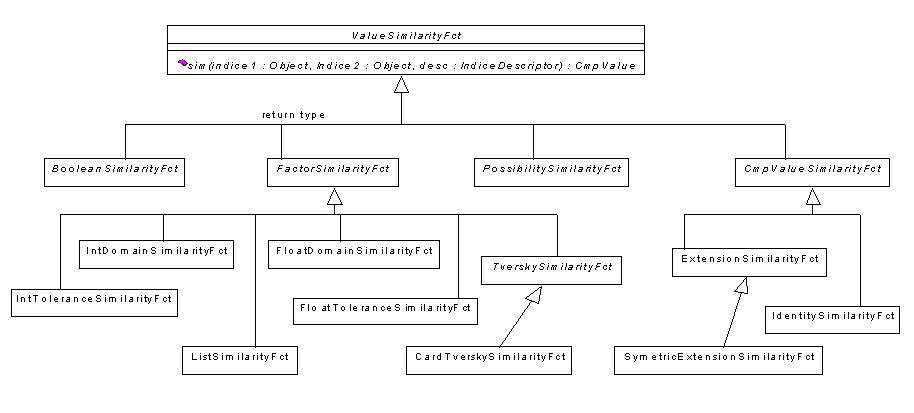
Figure 1 : extrait de la hiérarchie des fonctions élémentaires de similarité

Tableau 1 : fonctions élémentaires de similarité dans CBR*Tools
API |
- interface aid.cbr.tools.core.memory.similarity. ValueSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. AbstractSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. BooleanSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. CardTverskySimilarityFct
- classe aid.cbr.tools.core.memory.similarity. CmpValueSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. ExtensionSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. FactorSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. FloatDomainSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. FloatToleranceSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. IdentitySimilarityFct
- classe aid.cbr.tools.core.memory.similarity. IntDomainSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. IntToleranceSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. ListSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. PossibilitySimilarityFct
- classe aid.cbr.tools.core.memory.similarity. SymetricExtensionSimilarityFct
- classe aid.cbr.tools.core.memory.similarity. TverskySimilarityFct
![]()