Point d'ouverture "Similarity"
![]()
![]()
![]()
![]()
![]()
Description |
Le point d'ouverture Similarity permet de définir des mesures de similarité adaptées à un indice simple ou à un indice composé. Il permet de définir des mesures de similarité permettant de comparer les cas sources au cas cible.
Conception |
La modélisation proposée repose sur une représentation structurée des similarités et permet une modification aisée de leur définition.
La représentation des mesures de similarité doit être adaptée à la représentation des indices, c'est pourquoi on utilise de manière identique le patron de conception Composite permettant de définir des mesures structurées (cf. Figure 1). Une mesure (de classe Similarity ) peut donc être une mesure de similarité adaptée à un indice simple (classe SimpleIndiceSimilarity ) ou à un indice composé (classe CompoundIndiceSimilarity ).
On applique également le patron de conception Stratégie pour la représentation des fonctions élémentaires de similarité et des fonctions d'agrégation. Ce patron permet la définition d'une famille de fonctions parmi lesquelles il est possible de sélectionner celle à utiliser. Ainsi, l'objet de similarité d'un indice simple délègue le calcul de la similarité à une fonction de similarité (classe ValueSimilarityFct ). De même, l'objet de similarité d'un indice composé délègue le calcul de l'agrégation des valeurs de similarité issues de la comparaison des sous-indices, à une fonction d'agrégation (classe AggregationFct ). Un vecteur de poids d'importance est également défini au niveau de chaque objet de similarité pour les indices composés. Enfin, les objets de similarité utilisent le patron de conception Prototype qui permet de créer une nouvelle similarité par clonage d'une similarité existante (méthode clone ).
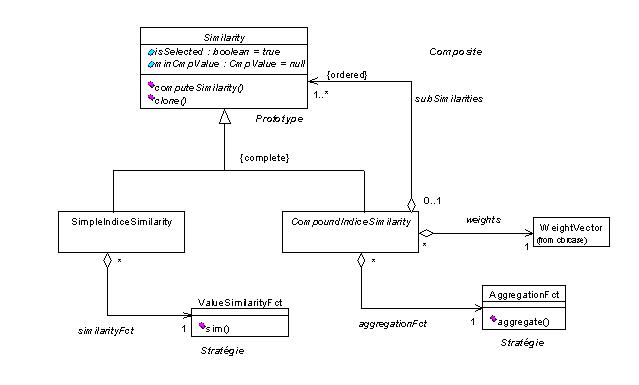
Figure 1 : mesures de similarité structurées et modifiables
Cette modélisation permet une modification aisée des mesures de similarité. Il est tout d'abord possible d'affecter dynamiquement de nouvelles fonctions élémentaires de similarité ou des fonctions d'agrégation sans modifier la structure de la mesure de similarité. D'autre part, le clonage des similarités permet de gérer des mesures qui ne diffèrent que par les modifications apportées. On peut ainsi constituer de manière simple une bibliothèque de mesures de similarité. Cette modélisation présente également une bonne répartition des responsabilités : les objets formant la structure de la mesure de similarité contrôlent le calcul, alors que les fonctions sont utilisables dans différentes mesures et sont issues de hiérarchies de classes pouvant être étendues de manière indépendante. Le calcul est effectué par un parcours récursif de la structure : les mesures de similarité d'un indice simple contrôlent l'appel de la fonction élémentaire de similarité, et les mesures de similarité d'un indice composé contrôlent l'appel récursif aux sous-similarités ainsi que l'agrégation des résultats intermédiaires. Le calcul de la similarité suppose que les deux ensembles d'indices à comparer et la représentation de la similarité aient une structure identique. Si deux cas de structures différentes doivent être comparés, la similarité peut être construite dynamiquement pour refléter la structure commune aux deux cas.
On propose la prise en compte de deux types de paramètres lors du calcul de la similarité : les paramètres de construction et les paramètres d'évaluation :
- Les paramètres de construction permettent de modifier finement le comportement de la similarité au niveau de chaque objet de la structure (attributs de la classe Similarity ). Deux paramètres de construction sont proposés dans CBR*Tools permettant de fixer un seuil de similarité minimum au niveau de chaque indice (simple ou composé), et de sélectionner les indices qui participeront au calcul. Le premier paramètre est utile pour assurer un certain degré de similarité et permet d'anticiper l'échec d'une comparaison : si le seuil n'est pas respecté, le calcul de la similarité est de suite abandonné et les comparaisons restantes ne sont pas effectuées. Le deuxième paramètre permet d'utiliser une structuration de la similarité existante tout en sélectionnant les indices effectivement utilisés. Les paramètres de construction peuvent être modifiés et leur changement est persistant,
- Les paramètres d'évaluation sont des objets (de classe SimilarityEvalParams ) transmis lors du calcul. Ces paramètres sont donc facilement modifiables à chaque appel et permettent notamment : l'activation des seuils de similarité, la sélection d'une méthode de choix des poids d'importance, et la définition de la valeur à utiliser lorsqu'un indice simple a une valeur inconnue. La méthode de sélection des poids est intéressante, puisqu'on peut associer des poids d'importance au niveau des indices des cas sources, du cas cible et de la similarité. Les poids associés à chaque cas source indiquent quelles sont les importances relatives des indices permettant de juger de l'utilité du cas, et sont mis à jour lors de l'apprentissage. Les poids associés aux indices du cas cible proviennent d'une évaluation faite a priori lors de l'élaboration au début d'un raisonnement. Les poids issus de la similarité sont considérés comme des poids par défaut qui ont été estimés lors de la construction de la similarité. La sélection des poids est déléguée à un objet passé en paramètre, permettant ainsi de sélectionner ou de combiner les poids de manière ouverte. Par exemple, si l'utilisateur courant est un novice, le système utilisera les poids de la similarité ou celui des cas sources, par contre, si l'utilisateur est un expert, les poids du cas cible qu'il aura spécifiés seront utilisés. Enfin, il est intéressant de pouvoir modifier la valeur de comparaison dans le cas d'un indice de valeur inconnue. Par exemple, un facteur de 0.5 est habituellement utilisé ; cependant, des évaluations optimistes (valeur 1) ou pessimistes (valeur 0) peuvent être choisies.
API |
- interface aid.cbr.tools.core.memory.similarity. Similarity
- classe aid.cbr.tools.core.memory.similarity. AbstractSimilarity
- classe aid.cbr.tools.core.memory.similarity. CompoundIndiceArraySimilarity
- classe aid.cbr.tools.core.memory.similarity. CompoundIndiceSharedSimilarity
- classe aid.cbr.tools.core.memory.similarity. CompoundIndiceSimilarity
- classe aid.cbr.tools.core.memory.similarity. SimpleIndiceSimilarity
![]()