|
Participants: AxiS (Inria), Dream (Inria), KDD (LGI2P/EMA Nimes), TATOO (LIRMM)
Dans le projet SÉSUR, nous souhaitons nous focaliser sur les approches d'extraction de motifs et sur les approches de classification (supervisée ou non) dans les flots de données. L'extraction de connaissances est dite supervisée lorsqu'il est possible de partager les données en entrée en un ensemble de séquences dans lesquelles le phénomène à caractériser est présent et un ensemble de séquences dans lesquelles on sait que le phénomène ne s'est pas produit. L'extraction non supervisée vise à extraire des schémas sans connaissance préalable. Des critères basés généralement sur la fréquence d'apparition des motifs extraits sont utilisés pour distinguer les motifs à retenir. Dans les deux cas, la qualité des données et leur complexité doivent être prises en compte (en pré-traitement ou pendant l'extraction). Nous commençons donc par présenter un axe qui consiste à étudier la prise en compte de la complexité et l'imperfection des données dans les approches supervisées et non supervisées, de manière à assurer la qualité des connaissances extraites.
Prise en compte de la complexité des données
Les données issues du monde réel sont souvent décrites au travers de différents attributs. De telles données sont dites multidimensionnelles, les dimensions pouvant même être munies de hiérarchies permettant de décrire les données à différents niveaux de granularité. De plus, les données sont souvent entachées d'imperfections, soit parce qu'elles sont incertaines, ou parce qu'elles sont imprécises. Ce phénomène est très fréquent dans les données manipulées dans les flots de données puisqu'elles proviennent la plupart du temps de capteurs renvoyant des informations imparfaites. Dans le contexte des flots de données, notre objectif est de proposer des méthodes permettant de considérer la complexité des données, tant sur le plan de leur aspect multidimensionnel que sur le plan de leur imperfection. Pour ce faire, nous proposons d'intégrer les travaux menés dans l'équipe TATOO liés au traitement de motifs séquentiels multidimensionnels et flous afin de les étendre au contexte des flots de données. Cet objectif est crucial dans le contexte des flots de données puisqu'il conditionne le fait que les méthodes proposées seront robustes et valides sur des données issues du monde réel. En effet, les méthodes classiques existantes pour le traitement des flots de données ignorent les imperfections et traitent donc des données très souvent biaisées.
Extraction non supervisée dans les flots de données.
Extraction de motifs séquentiels
Les motifs (ou connaissances) sont en général extraits en fonction de paramètres spécifiés par l'utilisateur : nombre d'occurrences d'un motif pour qu'il soit pertinent [26,23], contraintes temporelles d'apparition entre événements [24], etc. Les techniques proposées jusqu'à présent considèrent un accès à la base dans son intégralité et nécessitent traditionnellement plusieurs parcours de cette base pour valider ou infirmer la présence de motifs candidats. Dans le cadre des flots de données, notre objectif est de reconsidérer ces approches pour éliminer ces jointures qui sont bloquantes par rapport au flot. De premières pistes ont été explorées par les partenaires impliqués dans ce projet pour l'apprentissage non supervisé de motifs séquentiels dans les flots de données [33,22]. En outre, le treillis des motifs extrait évolue constamment. Il peut donc être nécessaire de remettre en cause une partie de ce treillis et de le mettre à jour par oubli de certains motifs candidats.
Clustering dans les flots de données
- Les travaux réalisés par l'équipe AxIS ont montré l'efficacité d'une approche basée sur une classification des séquences du flot de données, suivi par une extraction dans chaque cluster de la séquence qui le résume [22,21]. Pour cette approche, une heuristique gloutonne a été définie afin d'affecter chaque nouvelle séquence dans une classe. Notre objectif est de proposer de nouvelles approches de classification de séquences dans les flots de données. Nous sommes en effet convaincus que l'extraction de motifs séquentiels dans les flots de données passe par des méthodes efficaces de classification qui permettent de diviser le problème et d'isoler d'éventuels individus susceptibles de provoquer un trop grand nombre de calculs (ce qui pourrait bloquer le flot).
-
-
Les techniques d'alignement de séquences permettent de proposer rapidement un résumé approximatif, mais fiable, d'un ensemble de séquences. Les techniques d'alignement existantes peuvent être appliquées mais elles ont été développées dans le cadre de données stockées et statiques. Notre objectif est de proposer une adaptation de ces techniques au contexte des flots de données, en considérant tout particulièrement que la précision des résultats doit rester aussi grande que possible. Ce dernier point est important, compte tenu du degré d'approximation déjà introduit par les techniques d'alignement appliquées aux données statiques.
Extraction supervisée dans les flots de données Les techniques proposées jusqu'à présent, telles les Bases de Données Inductives [32], pour extraire des chroniques ne permettent pas de prendre en compte des séquences très longues comme celles issues de flots de données. Ces techniques associent deux processus : la génération de motifs candidats et l'évaluation de leur pertinence. Ces deux points nécessitent des adaptations aux flots de données :
- la génération de motifs candidats ne peut plus procéder du plus général au plus spécifique car de nouveaux types d'objets peuvent apparaître dans les séquences et initialiser de nouveaux motifs complexes. Notre objectif est de proposer une méthode de gestion du treillis des motifs candidats qui évite de reconstruire ce treillis à l'apparition de nouvelles données. L'idée est de s'appuyer sur le treillis construit à l'instant
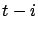 et de ne réévaluer que le sous-treillis concerné par l'introduction du nouveau motif, et de ne réévaluer que le sous-treillis concerné par l'introduction du nouveau motif,
- l'évaluation de la pertinence des motifs candidats doit être réalisée sur une partie des données. Le support d'un motif calculé à un instant
 peut être complètement différent de celui calculé à l'instant . On se trouve alors confrontés aux mêmes problèmes que ceux rencontrés dans les approches non supervisées du paragraphe précédent. Notre objectif est d'étudier les techniques de résumés utilisées en extraction supervisée dans le cadre des flots de données et de les adapter au cas supervisé. peut être complètement différent de celui calculé à l'instant . On se trouve alors confrontés aux mêmes problèmes que ceux rencontrés dans les approches non supervisées du paragraphe précédent. Notre objectif est d'étudier les techniques de résumés utilisées en extraction supervisée dans le cadre des flots de données et de les adapter au cas supervisé.
|