Virginie BOTTOLLIER
1.0.2
17/04/2007
Corese User Manual
Corese stands for COnceptual REsource Search Engine. It is an RDF engine based on Conceptual Graphs (CG). It enables the
processing of RDF Schema and RDF statements within the CG formalism (see the note
from T. Berners-Lee on the subject).
Corese is written in Java; it provides an API for developers to add semantic to their applications. The main functionality of
Corese is dedicated to retrieve web resources annotated in RDFS, by using a query language based on
SPARQL and an inference rule engine.
On top of Corese, a JSP tag library (Semantic Tags) has been developed. And a set of web services are under development. These two libraries allow developers to use Corese in their web applications by wrapping Corese access (like Corese administration tasks, query submission and so on) into standard web tools (JSP Tags and Web services).
This manual presents how to use Corese in a standalone mode. After a short introduction
about what Corese is and what it is used for, the main part describes
how to use Corese (how to get the standalone version, how to load
ontologies, how to write queries, which functionalities are added, how
to write a new function, how to write rules), while the final part is
more technical, discussing about how to develop with Corese (it
describes the API, how to handle the results, how to manage the
property files).
It is written for persons with a measurable knowledge in semantic web.
This manual describes the CORESE_2007_04_17_v2_3_0.jar version of Corese.
The standalone version of Corese can be used to:
The first version of the Corese prototype was created in 1999. Corese is now used, and has been used, as semantic search engine in more than 20 applications; here are some examples:
Other applications using Corese can be found here: http://www-sop.inria.fr/acacia/corese/applications.html.
Corese is developed with Java 1.5.
Annotations are RDF files, ontologies are RDFS or OWL (Lite or DL) files, and rules are .rul files.
We use the following APIs:
With the following licenses:
In Corese, we use RDFS (or OWL) for the ontology, RDF for annotations and SPARQL as a query language, you can find information about these four standards (SPARQL will soon become a standard, RDF, RDFS and OWL are already ones) on the following W3C documents:
We also use RDF Rules; they will be explained later in this document.
To get the standalone version of Corese, go the Corese download web page, agree to the "Free of charge software agreement" by clicking on the "I AGREE" button, after having given your name, e-mail and organization.
On the next page, download "CORESE 2.3.0". Here can also be found licenses under which the software is provided, a set of examples of Corese, the Corese Javadoc, the libraries and the sources of Notio (the Conceptual Graph platform used to design Corese).
To start the standalone version of Corese, double click on the JAR (for Windows OS) or use the command
"java -jar CORESE_2007_04_17_v2_3_0.jar" (for any OS).
Once the application is launched, in the "Logging and messages" part, load an
ontology by clicking on the "Load" button and by selecting
the ontology (.rdfs file or .owl file) to load. Repeat this for all the
ontologies you want to load. Note: it is also possible to load a whole
directory in one time.
In the same way it is possible to load annotations (.rdf files) and rules (.rul files).
SPARQL is an RDF query language designed by the W3C Data Access Working Group
to easily access to RDF stores.
According to the SPARQL Working Draft:
"The SPARQL query language consists of the syntax and semantics for asking and answering queries against RDF graphs. SPARQL
contains capabilities for querying by triple patterns, conjunctions, disjunctions, and optional patterns. It also supports
constraining queries by source RDF graph and extensible value testing. Results of SPARQL queries can be ordered, limited and
offset in number, and presented in several different forms."
The Corese tutorial explains briefly what RDF, RDFS, and SPARQL are; before giving a tutorial on how to query Corese and how to use rules.
PREFIX tutor: <http://inria.fr/2006/tutorial#>
SELECT ?student ?name ?firstname
WHERE {
?student tutor:isStudentOf ?univ .
{
{ ?univ tutor:siteweb "http//www.mit.edu" . }
UNION
{ ?univ tutor:siteweb "http//www.stanford.edu" . }
}
?student tutor:name ?name .
OPTIONAL { ?student tutor:firstname ?firstname . }
?student tutor:age ?age .
FILTER ( ?age > 21 )
}
ORDER BY ?name
LIMIT 20
SPARQL is a future semantic web recommendation; that is why we have
decided to use it in Corese to query annotations. Here are the main
functionalities of SPARQL, used in Corese:
With Corese, we offer several other functionalities that are not in SPARQL; they are described in the next part, "Additive functionalities".
Corese query language is based on SPARQL, but it offers in addition some original statements among which approximated search that find best matches according to the RDF Schema, aggregation, path patterns...
SPARQL specification covers simple
Entailment, but with Corese we cover RDFS-Entailment.
In Corese, edges that are inferred by a rule have a default source graph: http://www.inria.fr/acacia/corese#engine
To get inferred edges, it is then possible to ask:
SELECT * WHERE {
GRAPH <http://www.inria.fr/acacia/corese#engine> { ?x ?p ?y }
}
With Corese, it is possible to ask for an approximated answer.
For example, an approximated search for "a teacher who has written a
book" can retrieve "a researcher who has written an article".
Syntactically, the keyword MORE in the select clause of a Corese query asks for approximated answers. In this case, Corese basically
approximates every concept types of the query.
| @prefix e: <http://example/of/ontology#> | ||
| e:personA | e:Name | 'John' |
| e:personA | rdf:type | e:Teacher |
| e:personA | e:hasWritten | e:bookA |
| e:bookA | rdf:type | e:Book |
| e:personB | e:Name | 'Lara' |
| e:personB | rdf:type | e:Researcher |
| e:personB | e:hasWritten | e:artB |
| e:artB | rdf:type | e:Article |
| e:personC | e:Name | 'Lucio' |
| e:personC | rdf:type | e:MathTeacher |
| e:personC | e:hasWritten | e:artC |
| e:artC | rdf:type | e:Article |
| e:MathTeacher | rdfs:subClassOf | e:Teacher |
| e:Teacher | rdfs:subClassOf | e:Person |
| e:Researcher | rdfs:subClassOf | e:Person |
Data
PREFIX e: <http://example/of/ontology#>
SELECT MORE ?name ?doc WHERE {
?person e:Name ?name .
?person rdf:type e:Teacher .
?person e:hasWritten ?doc .
?doc rdf:type e:Book
}
Query: Approximated search
| name | doc |
|---|---|
| John | e:bookA |
| Lara | e:artB |
| Lucio | e:artC |
Query Result
It is possible to require the specialization of some concepts while approximating others by using type operators. For instance, by using the <=: operator, Corese is able to retrieve persons who are teachers (or a subclass of teacher) and who have written a book (or something close) by processing the following query.
| @prefix e: <http://example/of/ontology#> | ||
| e:personA | e:Name | 'John' |
| e:personA | rdf:type | e:Teacher |
| e:personA | e:hasWritten | e:bookA |
| e:bookA | rdf:type | e:Book |
| e:personB | e:Name | 'Lara' |
| e:personB | rdf:type | e:Researcher |
| e:personB | e:hasWritten | e:artB |
| e:artB | rdf:type | e:Article |
| e:personC | e:Name | 'Lucio' |
| e:personC | rdf:type | e:MathTeacher |
| e:personC | e:hasWritten | e:artC |
| e:artC | rdf:type | e:Article |
| e:MathTeacher | rdfs:subClassOf | e:Teacher |
| e:Teacher | rdfs:subClassOf | e:Person |
| e:Researcher | rdfs:subClassOf | e:Person |
Data
PREFIX e: <http://example/of/ontology#>
SELECT MORE ?name ?doc WHERE {
?person e:Name ?name .
FILTER ( ?person <=: e:Teacher )
?person e:hasWritten ?doc .
?doc rdf:type e:Book
}
Query: Approximated search (with a part of the query where the concept is specialized)
| name | doc |
|---|---|
| John | e:bookA |
| Lucio | e:artC |
Query Result
The keyword SCORE allows us to control the level of approximation we want, for every part of the query.
The value 1 corresponds to perfect matches while 0 would correspond to the highest approximation.
We can use SCORE with 2 syntaxes:
| @prefix e: <http://example/of/ontology#> | ||
| e:personA | e:Name | 'John' |
| e:personA | rdf:type | e:Teacher |
| e:personA | e:hasWritten | e:bookA |
| e:bookA | rdf:type | e:Book |
| e:personB | e:Name | 'Lara' |
| e:personB | rdf:type | e:Researcher |
| e:personB | e:hasWritten | e:artB |
| e:artB | rdf:type | e:Article |
| e:personC | e:Name | 'Lucio' |
| e:personC | rdf:type | e:MathTeacher |
| e:personC | e:hasWritten | e:artC |
| e:artC | rdf:type | e:Article |
| e:MathTeacher | rdfs:subClassOf | e:Teacher |
| e:Teacher | rdfs:subClassOf | e:Person |
| e:Researcher | rdfs:subClassOf | e:Person |
Data
PREFIX e: <http://example/of/ontology#>
SELECT MORE ?x ?doc WHERE {
SCORE ?s1 { ?x rdf:type e:Teacher } .
SCORE ?s2 { ?doc rdf:type e:Book } .
?x e:hasCreated ?doc .
FILTER ( score() > 0.75 )
FILTER ( ?s2 > 0.5 )
}
Query: with SCORE
| name | doc |
|---|---|
| John | e:bookA |
| Lucio | e:artC |
Query Result
In the example, we are looking for a teacher who has created a book (or something near); we are more flexible with the fact that the document is a book (?s2 > 0.5), than with the whole result of the query (score() > 0.75).
The function similarity computes the similarity between two concepts; the result is a number between 0 (the highest approximation)
and 1 (concept types are equal). If one concept subsumes the other, we still compute the similarity between the two concepts.
| @prefix e: <http://example/of/ontology#> | ||
| e:p1 | rdf:type | e:Person |
| e:p2 | rdf:type | e:Engineer |
| e:p3 | rdf:type | e:Researcher |
| e:t1 | rdf:type | e:Truck |
| e:t2 | rdf:type | e:Car |
| e:Engineer | rdfs:subClassOf | e:Person |
| e:Researcher | rdfs:subClassOf | e:Person |
| e:Truck | rdfs:subClassOf | e:Vehicle |
| e:Car | rdfs:subClassOf | e:Vehicle |
Data
PREFIX e: <http://example/of/ontology#>
SELECT MORE * WHERE {
?x rdf:type ?t1 .
?y rdf:type ?t2
FILTER ( ?x != ?y && similarity(?x, ?y) > 0.9 )
}
We are looking for 2 different instances, that have similarity of 0.9.
| x | t1 | y | t2 |
|---|---|---|---|
| e:p1 | e:Person | e:p2 | e:Engineer |
| e:p2 | e:Engineer | e:p1 | e:Person |
| e:p1 | e:Person | e:p3 | e:Researcher |
| e:p3 | e:Researcher | e:p1 | e:Person |
| e:p2 | e:Engineer | e:p3 | e:Researcher |
| e:p3 | e:Researcher | e:p2 | e:Engineer |
| e:t1 | e:Truck | e:t2 | e:Car |
| e:t2 | e:Car | e:t1 | e:Truck |
Query Result
The function classSimilarity do the same thing with two classes (and not two instances).
| @prefix e: <http://example/of/ontology#> | ||
| e:p1 | rdf:type | e:Person |
| e:p2 | rdf:type | e:Person |
| e:p2 | rdf:type | e:Engineer |
| e:p2 | rdf:type | e:Actress |
| e:p3 | rdf:type | e:Person |
| e:p3 | rdf:type | e:Dancer |
| e:p3 | rdf:type | e:Researcher |
| e:Engineer | rdfs:subClassOf | e:Scientific |
| e:Researcher | rdfs:subClassOf | e:Scientific |
| e:Actress | rdfs:subClassOf | e:Artist |
| e:Dancer | rdfs:subClassOf | e:Artist |
Data
PREFIX e: <http://example/of/ontology#>
SELECT MORE * WHERE {
?x rdf:type e:Person .
?x rdf:type ?t1 .
?x rdf:type ?t2 .
FILTER ( classSimilarity(?t1, ?t2) < 0.8 )
}
We are looking for 2 different types (with similarity less than 0.8) for a person
| x | t1 | t2 |
|---|---|---|
| e:p2 | e:Actress | e:Engineer |
| e:p2 | e:Engineer | e:Actress |
| e:p3 | e:Dancer | e:Researcher |
| e:p3 | e:Researcher | e:Dancer |
Query Result
It is possible to have functions or expressions in the select clause. The syntax is function(?x) as ?fun.
| @prefix e: <http://example/of/ontology#> | ||
| e:p1 | e:age | '2'^^xsd:integer |
| e:p1 | e:FamilyName | 'Smith' |
| e:p1 | e:birthdate | '1982-10-10'^^xsd:date |
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?p ?y
datatype(?y) as ?datatype
(?age + 10) as ?inTenYears
WHERE {
e:p1 ?p ?y
e:p1 e:age ?age
}
We want to know the datatype of values linked to e:p1 by a property
| ?p | ?y | ?datatype | ?inTenYears |
|---|---|---|---|
| e:age | 2 | xsd:integer | 12 |
| e:FamilyName | 'Smith' | xsd:string | 12 |
| e:birthdate | 1982-10-10 | xsd:date | 12 |
Query Result
In SPARQL, the keyword DISTINCT is described as follows:
"[Distinct] ensures that every combination of variable bindings (i.e. each solution) in the sequence is unique".
Example: if we have the results aab aab abb aba abb, we will only keep aab, abb, and aba.
With Corese, in addition to the SPARQL keyword DISTINCT, we have add the keyword DISTINCT SORTED, which keep only distinct values in
variable binding sequence. In fact, we first sort the values in the results and then make the distinct.
Example: if we have the results aab aab abb aba abb, we will only keep
aab and abb (and not aba, because it is not "distinct sorted" with aab).
| @prefix e: <http://example/of/ontology#> | ||||||
| e:p1 | e:FirstName | 'a' | e:p2 | e:FirstName | 'a' | |
| e:p3 | e:FirstName | 'b' | e:p4 | e:FirstName | 'b' | |
| e:p1 | e:hasFriend | e:p2 | e:p1 | e:hasFriend | e:p3 | |
| e:p2 | e:hasFriend | e:p3 | e:p2 | e:hasFriend | e:p4 | |
| e:p3 | e:hasFriend | e:p2 | e:p3 | e:hasFriend | e:p4 | |
Data
PREFIX e: <http://example/of/ontology#>
SELECT DISTINCT SORTED ?n1 ?n2 ?n3 WHERE {
?x e:FirstName ?n1 .
?x e:hasFriend ?y .
?y e:FirstName ?n2 .
?y e:hasFriend ?z .
?z e:FirstName ?n3 .
FILTER (?x != ?y && ?x != ?z && ?y != ?z)
}
DISTINCT SORTED Example
| n1 | n2 | n3 |
|---|---|---|
| a | a | b |
| a | b | b |
Query Result: aab, aab, abb, abb, aba, bab => aab, abb
By default, results are presented as described by the W3C Working Group: SPARQL Query Results XML Format.
PREFIX e: <http://example/of/ontology#>
SELECT ?doc ?person WHERE {
?doc rdf:type e:Document .
?doc e:CreatedBy ?person
}
Example of simple query
<results>
<result>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-31.html</uri></binding>
<binding name='person'><uri>http://www.inria.fr/rose.dieng</uri></binding>
</result>
<result>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-31.html</uri></binding>
<binding name='person'><uri>http://www.inria.fr/equipes/acacia.en.html</uri></binding>
</result>
<result>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-26.html</uri></binding>
<binding name='person'><uri>http://www.inria.fr/stéphane.lapalut</uri></binding>
</result>
<result>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-33.html</uri></binding>
<binding name='person'><uri>http://www.inria.fr/equipes/orion.en.html</uri></binding>
</result>
</results>
Standard presentation of results (XML presentation)
The DISPLAY clause enables to tune the pretty-printer that generates RDF/XML markup.
It is possible to print in RDF format by using the DISPLAY RDF statement.
PREFIX e: <http://example/of/ontology#>
SELECT DISPLAY RDF ?doc ?person WHERE {
?doc rdf:type e:Document .
?doc e:CreatedBy ?person
}
Query with DISPLAY RDF
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:data='file:D:/corese/data/'
xmlns:e='http://example/of/ontology#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'>
<e:ResearchReport rdf:about='http://www.inria.fr/rapports/sophia/R-31.html'/>
<e:Employee rdf:about='http://www.inria.fr/rose.dieng'>
<rdf:type rdf:resource='http://example/of/ontology#Manager'/>
<rdf:type rdf:resource='http://example/of/ontology#Researcher'/>
</e:Employee>
</rdf:RDF>
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:data='file:D:/corese/data/'
xmlns:e='http://example/of/ontology#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'>
<e:ResearchReport rdf:about='http://www.inria.fr/rapports/sophia/R-31.html'/>
<e:ProjectGroup rdf:about='http://www.inria.fr/equipes/acacia.en.html'/>
</rdf:RDF>
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:data='file:D:/corese/data/'
xmlns:e='http://example/of/ontology#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'>
<e:ResearchReport rdf:about='http://www.inria.fr/rapports/sophia/R-26.html'/>
<e:Person rdf:about='http://www.inria.fr/stéphane.lapalut'/>
</rdf:RDF>
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:data='file:D:/corese/data/'
xmlns:e='http://example/of/ontology#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'>
<e:ResearchReport rdf:about='http://www.inria.fr/rapports/sophia/R-33.html'/>
<e:ProjectGroup rdf:about='http://www.inria.fr/equipes/orion.en.html'/>
</rdf:RDF>
Presentation of results in RDF/S
Note: with the statements CONSTRUCT and DESCRIBE, the graphs constructed are presented in RDF format.
The keyword MERGE merges all elementary solutions (projections) into one result.
PREFIX e: <http://example/of/ontology#>
SELECT MERGE ?doc ?person WHERE {
?doc rdf:type e:Document .
?doc e:CreatedBy ?person
}
Query with MERGE
<results>
<result>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-31.html</uri></binding>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-26.html</uri></binding>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-33.html</uri></binding>
<binding name='doc'><uri>http://www.inria.fr/rapports/sophia/R-34.html</uri></binding>
<binding name='person'><uri>http://www.inria.fr/rose.dieng</uri></binding>
<binding name='person'><uri>http://www.inria.fr/equipes/acacia.en.html</uri></binding>
<binding name='person'><uri>http://www.inria.fr/stéphane.lapalut</uri></binding>
<binding name='person'><uri>http://www.inria.fr/equipes/orion.en.html</uri></binding>
<binding name='person'><uri>http://www.inria.fr/régis.vincent</uri></binding>
<binding name='person'><uri>http://www.inria.fr/monique.thonnat</uri></binding>
<binding name='person'><uri>http://www.inria.fr/myriam.ribière</uri></binding>
</result>
</results>
Results are merged
In SPARQL, results are presented in a list, but with Corese, it is
possible to group the results that have the same value for given
variables with the keyword GROUP.
It is possible to group on several variables; in this case, we will
group first according to the first group, then according to the second
one, and so on.
| @prefix e: <http://example/of/ontology#> | ||||||||||
| e:doc1 | rdf:type | e:Document | e:doc1 | e:createdBy | e:p1 | e:doc1 | e:date | '2006-10-10' | ||
| e:doc2 | rdf:type | e:Document | e:doc2 | e:createdBy | e:p1 | e:doc2 | e:date | '2006-10-10' | ||
| e:doc3 | rdf:type | e:Document | e:doc3 | e:createdBy | e:p1 | e:doc3 | e:date | '1999-12-08' | ||
| e:doc4 | rdf:type | e:Document | e:doc4 | e:createdBy | e:p2 | e:doc4 | e:date | '2006-10-10' | ||
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?author ?date ?doc GROUP ?author GROUP ?date WHERE {
?doc rdf:type e:Document .
?doc e:createdBy ?author .
?doc e:date ?date
}
Example: group documents by author and then by date
| author | date | doc |
|---|---|---|
| e:p1 | 2006-10-10 | e:doc1, e:doc2 |
| e:p1 | 1999-12-08 | e:doc3 |
| e:p2 | 2006-10-10 | e:doc4 |
Query Result
These four functions can be applied when results are grouped (if not, it does not make sense).
The function count is used to count the number of different values for a variable in a result.
| @prefix e: <http://example/of/ontology#> | ||
| <http://tania.dupont> | e:FirstName | 'Tania' |
| <http://tania.dupont> | e:hasFriend | <http://aurelie.morel> |
| <http://tania.dupont> | e:hasFriend | <http://susan.trott> |
| <http://tania.dupont> | e:hasFriend | <http://christina.meyer> |
| <http://aurelie.morel> | e:FirstName | 'Aurelie' |
| <http://aurelie.morel> | e:hasFriend | <http://tania.dupont> |
| <http://john.hartman> | e:FirstName | 'John' |
| <http://john.hartman> | e:hasFriend | <http://paul.dupont> |
| <http://john.hartman> | e:hasFriend | <http://aurelie.morel> |
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?fname GROUP ?x WHERE {
?x e:FirstName ?fname .
?x e:hasFriend ?friend .
FILTER ( count(?friend) > 2 )
}
Select persons who have more than 2 friends
| fname |
|---|
| Tania |
Query Result
Functions sum and avg can be applied only to numbers (if not, the returned value will be null). They are implemented as
described in the document "XQuery 1.0 and XPath 2.0 Functions and Operators".
The function countItem is used to count the number of values for a variable in a result. In opposition to the function count,
countItem counts all values for a variable, and not only the different ones.
The function sum computes the sum of all values for a variable in a result.
The function avg computes the average of all values for a variable in a result.
avg(?x) = sum(?x) / countItem(?x)
| @prefix e: <http://example/of/ontology#> | ||||||
| e:teamA | rdf:type | e:Team | e:teamB | rdf:type | e:Team | |
| e:teamC | rdf:type | e:Team | ||||
| e:p1 | e:isMemberOf | e:teamA | e:p1 | e:age | 30 | |
| e:p1 | e:FirstName | 'James' | ||||
| e:p2 | e:isMemberOf | e:teamA | e:p2 | e:age | 30 | |
| e:p2 | e:FirstName | 'John' | ||||
| e:p3 | e:isMemberOf | e:teamA | e:p3 | e:age | 28 | |
| e:p3 | e:FirstName | 'Laura' | ||||
| e:p4 | e:isMemberOf | e:teamB | e:p4 | e:age | 20 | |
| e:p4 | e:FirstName | 'Jennifer' | ||||
| e:p5 | e:isMemberOf | e:teamB | e:p5 | e:age | 22 | |
| e:p5 | e:FirstName | 'Alice' | ||||
| e:p6 | e:isMemberOf | e:teamB | e:p6 | e:age | 23 | |
| e:p6 | e:FirstName | 'Bianca' | ||||
| e:p7 | e:isMemberOf | e:teamB | e:p7 | e:age | 28 | |
| e:p7 | e:FirstName | 'Pierre' | ||||
| e:p8 | e:isMemberOf | e:teamC | e:p8 | e:age | 40 | |
| e:p8 | e:FirstName | 'Steve' | ||||
| e:p9 | e:isMemberOf | e:teamC | e:p9 | e:age | 45 | |
| e:p9 | e:FirstName | 'Johan' | ||||
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?t ?x ?age GROUP ?t WHERE {
?t rdf:type e:Team .
?x e:isMemberOf ?t .
?x e:FirstName ?fname .
?x e:age ?age .
FILTER ( avg(?age) < 30 && sum(?age) > 80 )
}
ORDER BY countItem(?age)
Select teams (with their members and ages of their members) where the average age of the members is less than 30 years and the sum of the ages of the members is more than 80 and sort the results on the number of age per team.
| t | x | age | countItem(?age) |
|---|---|---|---|
| e:teamA | e:p1, e:p2, e:p3 | 30, 30, 28 | 3 |
| e:teamB | e:p4, e:p5. e:p6, e:p7 | 20, 22, 23, 28 | 4 |
Query Result
Functions sum, countItem and avg use all values for a variable in a result.
If there is a duplication, the result is biased, but it is the responsability of the person who asks the query.
For example, if we add the following triple to data, results of the
query will be biased, because a person (e:p4) will be counted twice
(because he/she has two names).
| e:p4 | e:FirstName | 'Jenny' |
Triple added
| t | x | age | countItem(?age) |
|---|---|---|---|
| e:teamA | e:p1, e:p2, e:p3 | 30, 30, 28 | 3 |
| e:teamB | e:p4, e:p4, e:p5. e:p6, e:p7 | 20, 20, 22, 23, 28 | 5 |
Query Result
Type comparators enable us to specify constraints on some types in a query: strict specialization (<:), specialization or same type (<=:), same type (=:), generalization or same type (>=:), strict generalization (>:).
For instance, by using the <: operator in the following example, we constrain the document to be a strict specialization of a thesis (e.g. a PhD thesis, a MSc thesis, etc.).
| @prefix e: <http://example/of/ontology#> | ||||||
| e:doc1 | rdf:type | e:Document | e:p1 | e:hasWritten | e:doc1 | |
| e:doc2 | rdf:type | e:Thesis | e:p2 | e:hasWritten | e:doc2 | |
| e:doc3 | rdf:type | e:PhDThesis | e:p2 | e:hasWritten | e:doc3 | |
| e:doc4 | rdf:type | e:MasterThesis | e:p3 | e:hasWritten | e:doc4 | |
| e:PhDThesis | rdfs:subClassOf | e:Thesis | ||||
| e:MasterThesis | rdfs:subClassOf | e:Thesis | ||||
| e:Thesis | rdfs:subClassOf | e:Document | ||||
Data
PREFIX e: <http://example/of/ontology#>
SELECT * WHERE {
?x e:hasWritten ?doc .
?doc rdf:type ?type .
FILTER ( ?doc <: e:Thesis )
}
Ask for a strict specialization of a thesis
| x | doc | type |
|---|---|---|
| e:p2 | e:doc3 | e:PhDThesis |
| e:p3 | e:doc4 | e:MasterThesis |
Query Result
The following example excludes students and their sub-types.
| @prefix e: <http://example/of/ontology#> | ||
| e:p1 | rdf:type | e:Student |
| e:p2 | rdf:type | e:MasterStudent |
| e:p3 | rdf:type | e:Engineer |
| e:Student | rdfs:subClassOf | e:Person |
| e:MasterStudent | rdfs:subClassOf | e:Student |
| e:Engineer | rdfs:subClassOf | e:Person |
Data
PREFIX e: <http://example/of/ontology#>
SELECT * WHERE {
?p rdf:type e:Person .
?p rdf:type ?type .
FILTER (!( ?p <=: e:Student))
}
Example of the negation of a type operator
| p | type |
|---|---|
| e:p3 | e:Engineer |
Query Result
In addition to the existing operators in SPARQL, we have defined
some other operators specifically for Corese, that applies for string, literals and URIs:
In this query, we are looking for titles that either contains the word 'Potter' or begins with 'Witch'.
| @prefix e: <http://example/of/ontology#> | ||||||
| e:book1 | e:title | 'Witches and Wizards'@en | e:book2 | e:title | 'Harry Potter 2' | |
| e:book3 | e:title | 'The Witch Book' | e:book4 | e:title | 'Harry Potter 1' | |
| e:book5 | e:title | 'Everything about Harry Potter' | e:book6 | e:title | 'Magic' | |
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?book ?title WHERE {
?book e:title ?title .
FILTER ( (?title ^ 'Witch') || (?title ~ 'Potter') )
}
Example of use of other operator
| book | title |
|---|---|
| e:book1 | Witches and Wizards |
| e:book2 | Harry Potter 2 |
| e:book4 | Harry Potter 1 |
| e:book5 | Everything about Harry Potter |
Query Result
These operators can be useful to manipulate URIs, for example to find every properties that have for prefix "http://www.w3.org/1999/02/22-rdf-syntax-ns#" (which corresponds to the prefix "rdf:" in this manual).
SELECT ?p WHERE {
?p rdf:type rdfs:Property .
FILTER ( ?p ^ 'http://www.w3.org/1999/02/22-rdf-syntax-ns#' )
}
Find properties defined in the rdf syntax
A query with an oriented path of given maximum length n between two
resources generates n queries (written here as UNION) and stops at the
first query that succeeds.
The syntax for oriented path is to add [ <INTEGER> ] after the property.
Example: e:hasFriend[n] for a path of maximum length n.
We stop the query at the first result found.
| @prefix e: <http://example/of/ontology#> | ||
| <http://maria> | e:hasFriend | <http://tania> |
| <http://tania> | e:hasFriend | <http://leo> |
| <http://leo> | e:hasFriend | <http://sophie> |
| <http://john> | e:hasFriend | <http://nicolas> |
| <http://john> | e:hasFriend | <http://maria> |
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?y WHERE {
<http://maria> e:hasFriend[2] ?y . FILTER(?y ~ 'o')
}
generates PREFIX e: <http://example/of/ontology#> SELECT ?y WHERE { { <http://maria> e:hasFriend ?y . FILTER(?y ~ 'o') } UNION { <http://maria> e:hasFriend ?z . ?z e:hasFriend ?y . FILTER(?y ~ 'o') } }
Oriented path: we are looking for a friend of Maria or a friend of a friend of Maria
| y |
|---|
| <http://leo> |
Query Result
A query with a non oriented path of given maximum length n between
two resources generates 2^(n+1)-2 queries (written here as UNION) and
stops at the first query that succeeds.
?x e:hasFriend{n} ?y search the paths of maximum length n between ?x and ?y; both (?x e:hasFriend ?y) and (?y e:hasFriend ?x) are valid triples to
construct the path.
Note: This statement should be used with care because of the large number of triples that it generates.
We stop the query at the first result found.
| @prefix e: <http://example/of/ontology#> | ||
| <http://maria> | e:hasFriend | <http://tania> |
| <http://tania> | e:hasFriend | <http://leo> |
| <http://leo> | e:hasFriend | <http://sophie> |
| <http://john> | e:hasFriend | <http://nicolas> |
| <http://john> | e:hasFriend | <http://maria> |
Data
PREFIX e: <http://example/of/ontology#>
SELECT * WHERE {
<http://maria> e:hasFriend{2} ?y FILTER(?y ~ 'o')
}
generates PREFIX e: <http://example/of/ontology#> SELECT * WHERE { { <http://maria> e:hasFriend ?y . FILTER(?y ~ 'o') } UNION { ?y e:hasFriend <http://maria> . FILTER(?y ~ 'o') } UNION { <http://maria> e:hasFriend ?v . ?v e:hasFriend ?y . FILTER(?y ~ 'o') } UNION { <http://maria> e:hasFriend ?v . ?y e:hasFriend ?v . FILTER(?y ~ 'o') } UNION { ?v e:hasFriend <http://maria> . ?y e:hasFriend ?v . FILTER(?y ~ 'o') } UNION { ?v e:hasFriend <http://maria> . ?v e:hasFriend ?y . FILTER(?y ~ 'o') } }
Non oriented path
| y |
|---|
| <http://john> |
Query Result
When using paths, we stop by default at the first query that succeeds, but it is possible to test all paths with the property qualifier all::. This is possible both for oriented and not oriented paths.
| @prefix e: <http://example/of/ontology#> | ||
| <http://maria> | e:hasFriend | <http://tania> |
| <http://tania> | e:hasFriend | <http://leo> |
| <http://leo> | e:hasFriend | <http://sophie> |
| <http://john> | e:hasFriend | <http://nicolas> |
| <http://john> | e:hasFriend | <http://maria> |
Data
PREFIX e: <http://example/of/ontology#>
SELECT * WHERE {
<http://maria> all::e:hasFriend{2} ?y FILTER(?y ~ 'o')
}
Usage of the property qualifier all::
| y |
|---|
| <http://john> |
| <http://leo> |
| <http://nicolas> |
Query Result
The direct:: property qualifier can be used either on rdfs:subClassOf or on rdf:type.
When it is used with rdfs:subClassOf, the aim is to limit the query to direct rdfs:subClassOf
by ignoring occurrences produced by the transitive nature of rdfs:subClassOf.
It is also possible to use this property with rdf:type to ask the most precise type(s) of ?x.
| @prefix e: <http://example/of/ontology#> | ||
| e:Thesis | rdfs:subClassOf | e:Document |
| e:MasterThesis | rdfs:subClassOf | e:Thesis |
| e:MasterThesis | rdfs:subClassOf | e:Document |
| e:Engineer | rdfs:subClassOf | e:Person |
| e:p1 | rdf:type | e:Person |
| e:p2 | rdf:type | e:Engineer |
| e:p2 | rdf:type | e:Person |
Data
SELECT * WHERE {
{ ?class direct::rdfs:subClassOf ?super }
UNION
{ ?x direct::rdf:type ?class }
}
Usage of the property qualifier direct::
| x | class | super |
|---|---|---|
| e:Thesis | e:Document | |
| e:MasterThesis | e:Thesis | |
| e:Engineer | e:Person | |
| e:p1 | e:Person | |
| e:p2 | e:Engineer |
Query Result
The DESCRIBE statement is not well defined in SPARQL:
Current conventions for DESCRIBE return an RDF graph without any
specified constraints. Future SPARQL specifications may further
constrain the results of DESCRIBE, rendering some currently valid
DESCRIBE responses invalid. As with any query, a service may refuse to
serve a DESCRIBE query.
With Corese, when we ask for describing the variable ?x (respectively the URI <uri>), we transform the query in a SELECT MERGE ?x ?p ?v DISPLAY RDF statement (respectively SELECT MERGE <uri> ?p ?v DISPLAY RDF) that contains { { ?x ?p ?v } UNION { ?v ?p ?x } } (respectively { { <uri> ?p ?v } UNION { ?v ?p <uri> } }).
DESCRIBE <uri>
is transformed in
SELECT MERGE <uri> ?p ?v DISPLAY RDF
WHERE { { <uri> ?p ?v } UNION { ?v ?p <uri> } }
DESCRIBE ?x WHERE { ?x rdf:type rdfs:Class }
is transformed in
SELECT MERGE ?x ?p ?v DISPLAY RDF
WHERE { ?x rdf:type rdfs:Class . { { ?x ?p ?v } UNION { ?v ?p ?x } } }
Transformation of the DESCRIBE statement in Corese
| @prefix e: <http://example/of/ontology#> | ||
| <http://tania.dupont> | rdf:type | e:Person |
| <http://tania.dupont> | rdf:type | e:Engineer |
| <http://tania.dupont> | e:FamilyName | 'Dupont' |
| <http://tania.dupont> | e:FirstName | 'Tania' |
| <http://tania.dupont> | e:age | 25 |
| <http://aurelie.morel> | e:hasFriend | <http://tania.dupont> |
| <http://aurelie.morel> | e:age | 28 |
Data
DESCRIBE <http://tania.dupont>
Exemple of a describe query
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:xsd='http://www.w3.org/2001/XMLSchema#'
xmlns:e='http://example/of/ontology#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'>
<e:Person rdf:about='http://tania.dupont'>
<rdf:type rdf:resource='http://example/of/ontology#Engineer'/>
<e:FamilyName rdf:datatype='http://www.w3.org/2001/XMLSchema#string'>Dupont</e:FamilyName>
<e:FirstName rdf:datatype='http://www.w3.org/2001/XMLSchema#string'>Tania</e:FirstName>
<e:age rdf:datatype='http://www.w3.org/2001/XMLSchema#integer'>25</e:age>
</e:Person>
<e:Person rdf:about='http://aurelie.morel'>
<e:hasFriend rdf:about='http://tania.dupont'/>
</e:Person>
</rdf:RDF>
Query Result
The CONSTRUCT statement is defined in SPARQL
Here are some details about CONSTRUCT in Corese:
It is an error, when a variable is used in the CONSTRUCT while it is not defined in the WHERE clause.
It is not possible to use a property that is undefined in the ontology.
It is possible to restrict the maximum number of positive elementary projections with the keyword PROJECTION.
A projection is an elementary result, before being (possibly) grouped.
| @prefix e: <http://example/of/ontology#> | ||
| <http://tania.dupont> | rdf:type | e:Person |
| <http://tania.dupont> | rdf:type | e:Engineer |
| <http://susan.trott> | rdf:type | e:Gardener |
| <http://john.dotty> | rdf:type | e:Person |
| <http://john.dotty> | rdf:type | e:Researcher |
| <http://christina.meyer> | rdf:type | e:Engineer |
Data
SELECT ?x ?type PROJECTION 4 WHERE {
?x rdf:type ?type
}
Search all the possible types, but stop running the query after 4 elementary projections
| x | type |
|---|---|
| <http://tania.dupont> | e:Person |
| <http://tania.dupont> | e:Engineer |
| <http://susan.trott> | e:Gardener |
| <http://john.dotty> | e:Person |
Query Result
For the functions score, similarity and classSimilarity, see the
"Approximated search" paragraph.
For the functions count, sum, avg and countItem, see the
"Aggregation" paragraph.
This function returns the depth of a class in the hierarchy.
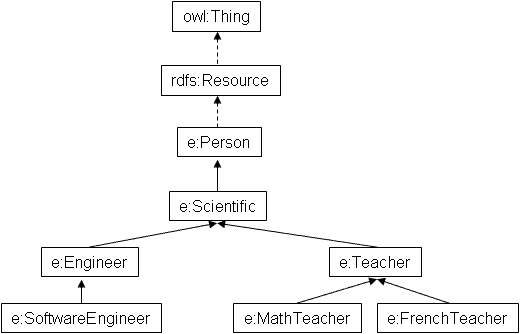
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?class WHERE {
?class rdfs:subClassOf e:Person .
FILTER ( depth(?class) > 4 )
}
Example: Looking for a subclass of e:Person, which is at a depth greater than 4 in the ontology
| class |
|---|
| e:SoftwareEngineer |
| e:MathTeacher |
| e:FrenchTeacher |
Query Result
The depth is relative to the root class.
In Corese, the root class is owl:Thing (depth 0); rdfs:Resource (depth 1) is a subclass of owl:Thing;
concepts in the ontology can be at depth 2 or more.
This function is used to ask if a URI is a source (i.e a URI that represents a graph).
| # Named graph: http://example/of/graphs/graphA | ||||
| @prefix e: <http://example/of/ontology#> | ||||
| _:a | e:FirstName | 'Alice' | ||
| _:a | e:FamilyName | 'Dupont' | ||
| _:a | e:hasFriend | _:b | ||
| _:b | e:FirstName | 'Bob' | ||
| <http://example/of/graphs/graphA> rdf:type e:Graph | ||||
| # Named graph: http://example/of/graphs/graphB | ||||
| @prefix e: <http://example/of/ontology#> | ||||
| _:a | e:FirstName | 'Aline' | ||
| _:a | e:hasFriend | _:b | ||
| _:b | e:FirstName | 'Bianca' | ||
| <http://example/of/graphs/graphB> rdf:type e:Graph | ||||
Data
SELECT ?x WHERE {
?x ?p ?y .
FILTER ( isSource(?x) )
}
This query looks for sources
| x |
|---|
| <http://example/of/graphs/graphA> |
| <http://example/of/graphs/graphB> |
Query Result
The function cardinality must be used on a property; if not, the query will fail.
It returns the number of occurrences of this property (and its subproperties) in the RDF base.
| @prefix e: <http://example/of/ontology#> | ||
| <http://tania.dupont> | rdf:type | e:Person |
| <http://tania.dupont> | rdf:type | e:Engineer |
| e:teamA | rdf:type | e:Team |
| <http://tania.dupont> | e:FirstName | 'Tania' |
| <http://aurelie.morel> | e:FirstName | 'Aurelie' |
| <http://tania.dupont> | e:FamilyName | 'Dupont' |
| <http://tania.dupont> | e:FamilyName | 'Morel' |
| <http://tania.dupont> | e:age | 25 |
| <http://tania.dupont> | e:hasBestFriend | <http://aurelie.morel> |
| <http://tania.dupont> | e:hasFriend | <http://susan.trott> |
| <http://tania.dupont> | e:hasFriend | <http://christina.meyer> |
| <http://tania.dupont> | e:hasFriend | <http://chris.bilon> |
| <http://aurelie.morel> | e:hasFriend | <http://tania.dupont> |
| <http://tania.dupont> | e:isMemberOf | e:teamA |
| e:hasBestFriend | rdfs:subPropertyOf | e:hasFriend |
Data
SELECT ?p WHERE {
?p rdf:type rdf:Property .
}
ORDER BY DESC ( cardinality(?p) )
This query looks for the properties the most used in the base graph
| p | cardinality(?p) |
|---|---|
| e:hasFriend | 5 |
| rdf:type | 3 |
| e:FirstName | 2 |
| e:FamilyName | 2 |
| e:age | 1 |
| e:isMemberOf | 1 |
| e:hasBestFriend | 1 |
| rdfs:subPropertyOf | 1 |
Query Result
The function occurrence do the same thing but only for the property in argument, NOT its subproperties. With the previous example, with
the function occurrence, we would have found only 4 occurences of the property e:hasFriend instead of 5.
Note: The function occurrence also works with classes: when asking for occurrence(?c) with ?c of type rdfs:Class, we retrieve the exact number of instances of the class ?c, without taking its subClasses.
These functions are taken from "XQuery 1.0 and XPath 2.0 Functions and Operators".
Report to this document to have the full description of the functions.
Note: func-year-from-dateTime, func-month-from-dateTime and func-day-from-dateTime have been renamed (respectively)
year, month and day.
Write a function (example: isOdd()) in a class (example: myClass.java), in a package
(example: example.of.path).
In our example, the function's access path will be example.of.path.myClass.isOdd().
Note: The function must have an "IDatatype" as a result and zero, one or several "IDatatype"
as arguments; to make this possible, include CORESE_2007_04_17_v2_3_0.jar in the classpath of the project.
To return a IDatatype, compute the result and use the DatatypeFactory; three ways are possible:
return DatatypeFactory.newInstance(result);return DatatypeFactory.newInstance(result, "fr");return DatatypeFactory.newInstance(result, CoreseType.INTEGER);public static enum CoreseType {STRING, BOOLEAN, XMLLITERAL, DOUBLE, FLOAT, DECIMAL, INTEGER, LONG, LITERAL, DATE, URI, BNODE};See the Corese Javadoc for more documentation about IDatatype.
/**
* say if the number is odd or not
* @param dt
* @return true if the argument is odd, false if not
* @throws CoreseDatatypeException
*/
public IDatatype isOdd(IDatatype dt) throws CoreseDatatypeException {
boolean result = (dt.getDoubleValue() % 2 == 1);
return DatatypeFactory.newInstance(result);
}
Example of function
Note: Functions have to be public
After having created the function, compile it and make a jar file.
It is possible to use ant, or simply the java command:
jar -cvf jar_name.jar classes/*
where jar_name.jar is the name of the jar and classes/* indicates where the compiled class is.
In order to recognize the new jar, add it to the java classpath; either add it to the classpath of the project in the IDE (if
a new application based on Corese is being created), or add it to the classpath when launching the Corese jar
(java -classpath "/path/of/the/newFunctionProject.jar;." -jar CORESE_2007_04_17_v2_3_0.jar)
Note: To execute this command, we have to be in the CORESE_2007_04_17_v2_3_0.jar directory; the dot in the classpath means that we use the
jar placed in the current directory (that is to say CORESE_2007_04_17_v2_3_0.jar).
To use the new function in a query, add a prefix, based on the following one (myurl).
function:// -> To inform Corese that the function is user defined
example.of.path.MyClass -> The path of the class where the function is defined
PREFIX humans: <http://www.inria.fr/2006/02/11/humans.rdfs#>
PREFIX myurl: <function://example.of.path.MyClass>
SELECT ?x ?age WHERE {
?x humans:age ?age
filter(myurl:isOdd(?age))
}
Example of a query with a user defined function call
The Corese rule language is based on the triple model of RDF and SPARQL. The syntax of a rule is the following.
<cos:rule>
<cos:if>
RDF Query
</cos:if>
<cos:then>
RDF Pattern
</cos:then>
</cos:rule>
where cos: is the predefined prefix for the Corese namespace (http://www.inria.fr/acacia/corese#) and where the triples correspond to RDF statements whose conjunction is translated into a conceptual graph.
In the IF part, it is possible to have prefix, defined like in SPARQL. The prefix is valid in the THEN part. It is however
possible to define the previous prefix again, to redefine it (with a new URI), or to define a new prefix in the THEN part.
The IF part follows the SPARQL syntax of the WHERE clause, i.e. GroupGraphPattern. Hence OPTIONAL, UNION and FILTER can be used in the IF part.
The THEN part follows the SPARQL syntax of BasicGraphPattern, hence OPTIONAL, UNION and FILTER cannot be used in the THEN part.
<cos:rule>
<cos:if>
PREFIX s: <http://example/of/ontology#>
{ ?m rdf:type s:Person .
?m s:head ?t .
?t rdf:type s:Team .
?t s:hasMember ?p .
?p rdf:type s:Person }
</cos:if>
<cos:then>
{ ?m s:manage ?p }
</cos:then>
</cos:rule>
Rule example
Here is the translation of the previous rule:
IF we have a person m (?m rdf:type s:Person) who is at the head (?m
s:head ?t) of a team (?t rdf:type s:Team), with another person p (?p
rdf:type s:Person) who is a member of this team (?t s:hasMember ?p),
THEN the person m manages the person p (?m s:manage ?p).
Rules are processed in forward chaining mode until saturation of the RDF base. The inference engine stops when nothing new is deduced. The deductions are stored within a default source which is: http://www.inria.fr/acacia/corese#engine. Hence the SPARQL graph statement enables to retrieve deductions of rules.
There are also Constraint Rules that enable to test whether constraints hold within the RDF graph. The condition describes a situation that should not happen, in which case the conclusion infer an error, by means of a predefined cos:Error system class. In this case, an error message is delivered, the resource (here ?m) is not typed to cos:Error, i.e. it is syntactic sugar.
<cos:rule>
<cos:if>
PREFIX s: <http://example/of/ontology#>
{ ?m rdf:type s:Adult .
?m s:age ?age .
filter(?age < 18)}
</cos:if>
<cos:then>
{ ?m rdf:type cos:Error }
</cos:then>
</cos:rule>
Constraint Rule example
Tip: As the document is an RDF/XML file, pay attention to write:
<?xml version="1.0" encoding="utf-8" ?>
<!DOCTYPE rdf:RDF [
<!ENTITY cos "http://www.inria.fr/acacia/corese#">
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY s "http://www.inria.fr/acacia/schema#">
]>
<rdf:RDF xmlns:rdf="&rdf;" xmlns:cos="&cos;" xmlns:s='&s;' >
<cos:rule cos:name='r1'>
<cos:if>
PREFIX s: <http://example/of/ontology#>
{ ?m rdf:type s:Person .
?m s:head ?t .
?t rdf:type s:Team .
?t s:hasMember ?p .
?p rdf:type s:Person }
</cos:if>
<cos:then>
{ ?m s:manage ?p }
</cos:then>
</cos:rule>
</rdf:RDF>
Complete example
Corese is compliant with SPARQL, except in two cases:
| @prefix e: <http://example/of/ontology#> | ||||||||||
| e:x1 | e:p | e:y1 | e:a1 | e:q | e:y1 | e:x1 | e:q | e:a1 | ||
| e:x2 | e:p | e:y2 | e:a2 | e:q | e:y2 | |||||
| e:x3 | e:p | e:y3 | e:x3 | e:q | e:a3 | |||||
Data
PREFIX e: <http://example/of/ontology#>
SELECT ?x ?y ?z ?a WHERE {
?x e:p ?y .
OPTIONAL { ?a e:q ?y } .
?x e:q ?a .
}
Example of different results with OPTIONAL
Corese Result:
| x | y | a |
|---|---|---|
| e:x1 | e:y1 | e:a1 |
| e:x3 | e:y3 | e:a3 |
| x | y | a |
|---|---|---|
| e:x1 | e:y1 | e:a1 |
Query Result
PREFIX e: <http://example/of/ontology#>Note: it is possible to write the query in another way to get the results:
SELECT * WHERE {
?x e:p ?y .
OPTIONAL { { ?x e:q ?z } UNION { ?x e:r ?z } } .
FILTER ( ! bound(?z) )
}
PREFIX e: <http://example/of/ontology#>
SELECT * WHERE {
?x e:p ?y .
OPTIONAL { ?x e:q ?z1 }
OPTIONAL { ?x e:r ?z2 }
FILTER ( !bound(?z1) && !bound(?z2) )
}
The processor of the query language is the conceptual graph projection. It takes advantage of RDF Schema by using subsumption relations (rdfs:subClassOf and rdfs:subPropertyOf) and processes datatype values (i.e. not the lexical form). It also exploits property signature (domain and range). The query language can query the RDF schema itself.
The Corese engine internally works on conceptual graphs. When matching a query with an annotation, according to their common ontology, both RDF graphs and their schemas are translated in the conceptual graph model. Through this translation, Corese takes advantage of the existing work of the knowledge representation community leading to reasoning capabilities of this language.
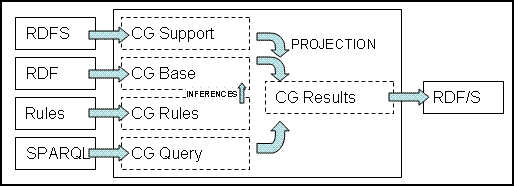
Corese general principle
As can be seen in the figure, Corese takes RDFS (ontologies), RDF (annotations), Rules, and SPARQL (queries) in entries. It constructs a conceptual graph with RDFS, RDF, and rules (using inferences). When a query (SPARQL) is submitted to Corese, we also transform it in a conceptual graph and then make projections on the first graph created (the one which represents ontology + annotations + rules). We finally find conceptual graph results, that we transform into RDF/S to pretty print the results.
To create an instance of the engine, create an instance of the EngineFactory first.
EngineFactory ef = new EngineFactory();
It is possible, but not mandatory, to set some properties before creating the instance of IEngine.
Properties that can be set in the EngineFactory are:
Exemple of path with Windows: String path = "D:/toto/corese/data"; Exemple of path with Linux: String path = "/0/user/toto/corese/data";
ef.setProperty(EngineFactory.PROPERTY_FILE, "corese.properties"); ef.setProperty(EngineFactory.DATAPATH, "D:/toto/corese/data"); ef.setProperty(EngineFactory.ENGINE_LOG4J, "prop/log4j.properties"); ef.setProperty(EngineFactory.ENGINE_SCHEMA, "data/humans.rdfs ontology/owlOntology.owl onto"); ef.setProperty(EngineFactory.ENGINE_DATA, "data/humans.rdf"); ef.setProperty(EngineFactory.ENGINE_RULE, "data/humans.rul"); ef.setProperty(EngineFactory.ENGINE_RULE_RUN, "true");
Example of properties settings
Note: if a property is defined both in the properties file and by the setProperty function, the value defined by the setProperty function will be considered, while the value defined by the properties file will be left aside.
Finally, create an IEngine by using the newInstance() method.
IEngine engine = ef.newInstance();
If you have not specified any files to load (with EngineFactory.ENGINE_SCHEMA, EngineFactory.ENGINE_DATA or EngineFactory.ENGINE_RULE), or if you want
to load additional files, it is possible after the creation of the IEngine.
It is also possible to say explicitly when rules have to be executed.
try {
// load only one file (the suffix has to be .rdfs .owl .rdf or .rul)
engine.load("path/to/the/file/to/load.rdfs");
// load a whole directory (only .rdfs .owl .rdf or .rul will be loaded)
engine.loadDir("path/to/the/directory/to/load");
// run rules
engine.runRuleEngine();
} catch (EngineException e) {
e.printStackTrace();
}
Note: paths can be relative or absolute
To execute the query, use the method SPARQLQuery of the interface IEngine.
try {
IResults res = engine.SPARQLQuery(queryString);
} catch (EngineException e) {
e.printStackTrace();
}
queryString is a string which represents the query asked to Corese; engine is a IEngine object.
While executing the query, exceptions may occur. They all extend EngineException:
It is also possible to validate the query before executing it with the function SPARQLValidate:
try {
boolean success = engine.SPARQLValidate(queryString);
} catch (EngineException e) {
e.printStackTrace();
}
Results can be printed. They will be displayed as asked by the DISPLAY statement (in XML SPARQL Result Format by default, except for CONSTRUCT and DESCRIBE where results are printed in RDF format).
IResults res = engine.SPARQLQuery(queryString); System.out.println(res);
But it is also possible to access results by means of an API.
It is possible to get variables name and their corresponding value.
try {
// get the results of the query
IResults res = engine.SPARQLQuery(queryString);
// get the list of all the selected variables
String[] variables = res.getVariables();
// go through all results
for (Enumeration<IResult> en = res.getResults(); en.hasMoreElements();) {
// get a result
IResult r = en.nextElement();
// go through this result
for (String var : variables) {
if (r.isBound(var)) {
// get result values for each selected variable
IResultValue[] values = r.getResultValues(var);
for (int j = 0; j < values.length; j++)
System.out.println(var + " = " + values[j].getStringValue());
} else {
System.out.println(var + " = Not bound");
}
}
}
} catch (EngineException e) {
e.printStackTrace();
}
To know if there are results, it is possible to use the function getSuccess()
try {
IResults res = engine.SPARQLQuery(queryString);
if (res.getSuccess()) {
//do something because there is one or more results!
}
} catch (EngineException e) {
e.printStackTrace();
}
Corese can be configurated with the file corese.properties. Here are explained some of the main properties:
| Input files |
|---|
| corese.schema=ontology/humans.rdfs owlOntology.owl Description: Ontologies to load Values: rdfs files, owl files |
| corese.data=annot/data annot/data2 annot/testrdf.rdf Description: Annotations to load Values: rdf files, or directories that contain .rdf files |
| corese.rule=rule/testrule.rul Description: Rules to load Values: rul files |
| corese.rule.run=true Description: Boolean to say if we run rules automatically (otherwise use the function runRuleEngine() described above) Values: true or false; Default: true |
| corese.gui.namespace=a http://www.inria.fr/acacia# i http://www.inria.fr# Description: Predefined prefix associated with a namespace Values: (see above) |
| Runtime parameters |
| corese.debug=false Description: If true, prints a maximum of information about the inferences it is making Values: true or false; Default: false |
| corese.log4j.conf=data/log4j.properties Description: The path (absolute or relative to the launching directory) to indicate where to find the log4j configuration file; it can be a .properties or a .xml file Values: String |
| corese.source.regex=.*data2.f.* http://www.inria/acacia/corese/data/fff.rdf/ Description: Assign a source URI to a set of URL by means of a regular expression. The triple from the set of URL are assigned the given source URI. Values: String |
| Result parameters |
| corese.result.projection.max=10000 Description: Maximum number of projections computed to answer a query Values: Integer; Default: 10000 |
| corese.result.max=100 Description: Maximum number of result returned after possibly grouping projections Values: Integer; Default: 100 |
| corese.result.show.max=1000 Description: Maximum number of statements printed by the RDF pretty printer Values: Integer; Default: 1000 |
| corese.result.join=false Description: When this property is set to true, Corese groups projections that share the same first concept into one result. Values: true or false; Default: false |
Note: Corese can run without corese.properties; properties then take their default values.
A complete example of corese.properties can be found here.
Paths given (in the three first properties for example), are relative to the launching directory (i.e where Corese starts) and to the datapath.
Corese uses the log4j logging system, from Apache.
When using the jar in an application, it is possible to get the logger and then to define an appender (where messages will be displayed), a layout (the format of displayed messages) or a level (between TRACE, DEBUG, INFO, WARN, ERROR and FATAL).
// get the default logger, from whom every other logger herits
Logger logger = Logger.getLogger("fr.inria.acacia.corese");
// remove appenders
logger.removeAllAppenders();
// define a new Appender (example: a WriterAppender)
WriterAppender wa = new WriterAppender(new PatternLayout("%m%n") , System.out);
// add this appender to the default logger
logger.addAppender(wa);
Example of a redefinition of the root logger
Log4j javadoc can be found here: http://logging.apache.org/log4j/docs/api/index.html.
Corese grammar is inspired by SPARQL Grammar, but as mentioned in the part
additive functionalities,
we have added some other functionalities; moreover, to try to be
compliant with the last query language of Corese, we are more flexible
with some aspects (for example, it is not mandatory to have a dot
between triples).